
今天是2025年6月11日,星期三,北京,晴
我们继续回到文档解析这个话题,来看看一个新的思路,强化学习用于端到端文档解析Infinity Parser,其中涉及到的文档解析数据集的构造以及强化奖励函数的设计思路,很值得看看。
另一个,还是回到GraphRAG的问题,还是从评估的角度上去看看,其到底优势在哪儿,从技术上去理解。
一、强化学习用于端到端文档解析Infinity Parser
我们昨天说到文档层级结构性的问题,并不好做,虽然也可以直接让多模态大模型进行端到端输出,但还是会格式错乱或者元素丢失。
如果要分析根本原因,那么则是文档的复杂布局和缺乏显式的语义标记,导致难以恢复文档的层次结构,多模态大模型的预训练目标与文档解析所需的结构理解之间的根本性不匹配——大多数预训练集中于图像-文本对齐和阅读理解,而没有针对文档固有的结构复杂性进行优化。与标准文本相比,文档展现出更丰富、更复杂的布局,包括层次化布局、嵌套元素和多模态内容。
所以,有个很直接的思路,就是结合强化学习去做,所以,可看看一个工作,《Infinity Parser: Layout Aware Reinforcement Learning for Scanned Document Parsing》,https://arxiv.org/pdf/2506.03197,将文档解析,也就是转markdown和强化学习进行结合,https://github.com/infly-ai/INF-MLLM/tree/main/Infinity-Parser。
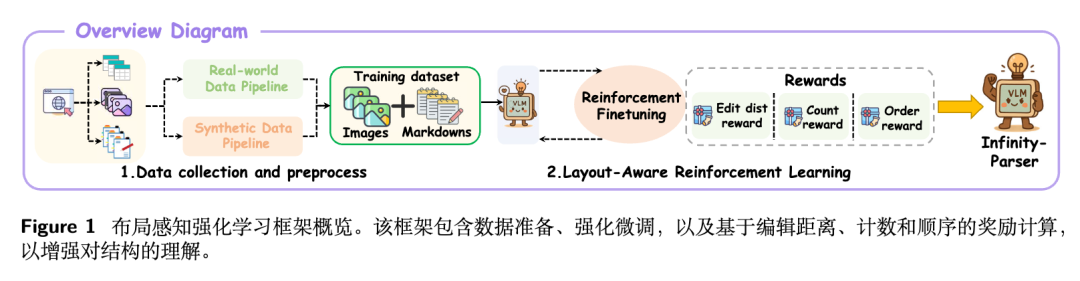
核心是训练数据的处理以及强化奖励函数的设计,通过优化多个方面的奖励函数来训练模型,使其对文档布局更加敏感。
下面来具体看看:
1、奖励函数的设计
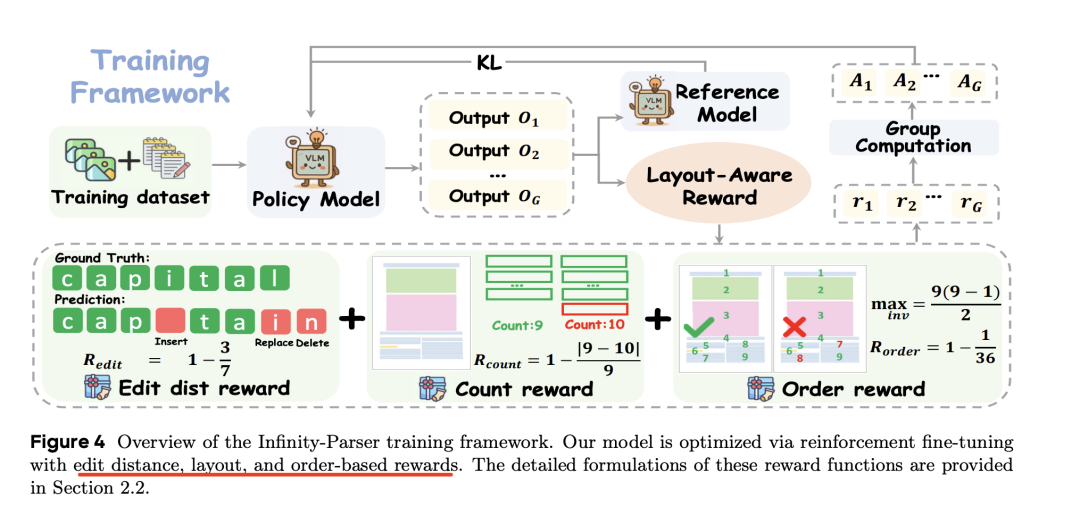
在强化阶段,使用Qwen2.5-VL-7B模型进行微调,采用GRPO进行强化学习优化,使用Group Relative Policy Optimization (GRPO)进行强化学习微调,通过生成一组候选Markdown输出,并使用多方面奖励函数进行评估,从而优化模型。
对应的提示如下:

其中核心点在于多方面奖励,包括三个,分别是编辑距离奖励(Edit Distance Reward)、计数奖励(Count Reward)以及顺序奖励(Order Reward)。
最后总合成一个奖励函数,如下:
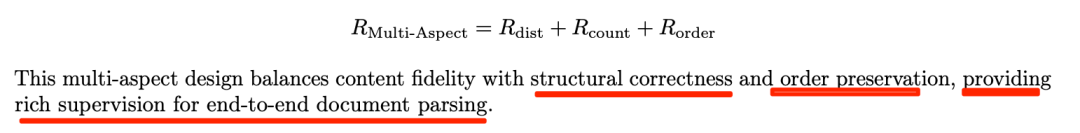
其中,细分到每个单独的奖励函数,可以看下定义和计算方式:
1)编辑距离奖励(Edit Distance Reward):基于预测输出和参考输出之间的归一化Levenshtein距离,衡量语义和格式的差异;

2)计数奖励(Count Reward):鼓励准确的段落分割,通过惩罚缺失或多余的段落来实现。

3)顺序奖励(Order Reward):通过计算参考和预测段落之间的成对逆序数来衡量序列级别的保真度。
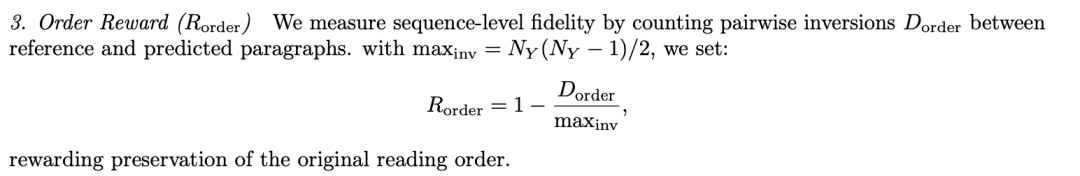
2、训练数据集
数据方面,包括Infinity-Doc-55K数据集,包含55,066个样本。合成方式是通过HTML模板和浏览器渲染生成,具体使用方式是:
从维基百科、网络爬虫和在线语料库等来源收集文本和图像,并使用Jinja模板将采样的内容注入预定义的单列、双列或三列 HTML布局中。
这些页面通过浏览器引擎渲染成扫描文档,随后进行自动过滤以去除低质量或重叠的图像。通过解析原始HTML 提取真实标注,生成对齐的Markdown表示。
最终形成的数据集涵盖七个不同的文档领域,包括财务报告、医疗报告、学术论文、书籍、杂志、网页等。
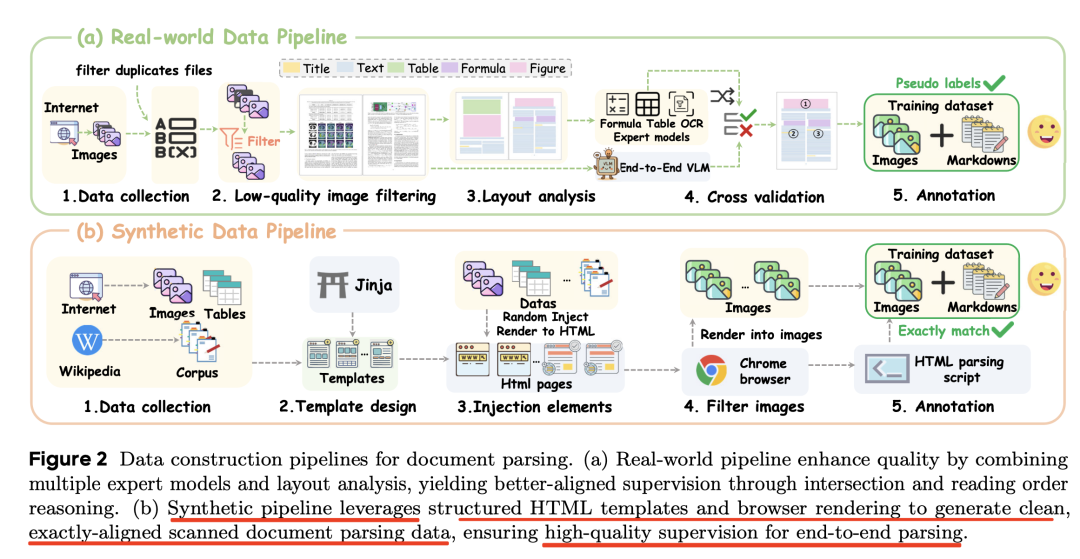
在生产出的数据上看,如下:

地址在:https://huggingface.co/datasets/infly/Infinity-Doc-55K
3、看下最终效果
可以看下最终效果,四种Markdown生成结果的对比,可以看到从直接推理到完整 Reward集成的逐步优化过程。

也可以看看与MinerU等方案的效果对比:

二、再看GraphRAG的评估结论
我们在前面的文章《GraphRAG是否总是有效?9大代表方案在GraphRAG-Bench的多维度对比》(https://mp.weixin.qq.com/s/PVQO-Pu3gWmQx9-2P0aw_A)中从现有典型的9个GraphRAG方案回顾、GraphRAG方案效果对比Benchmark、GraphRAG能否提升所有类型问题的表现三个话题做了一次总结,有一些结论,例如GraphRAG在多项选择题准确率下降、判断题准确率提升、开放式问题准确性提升、填空题准确性下降以及多项选择题准确性下降。
而这个问题的核心,其实还是评估benchmark的问题,所以,可以看看另一个工作,《When to use Graphs in RAG: A Comprehensive Analysis for Graph Retrieval-Augmented Generation》,https://arxiv.org/pdf/2506.05690v1,可以看看一些结论。
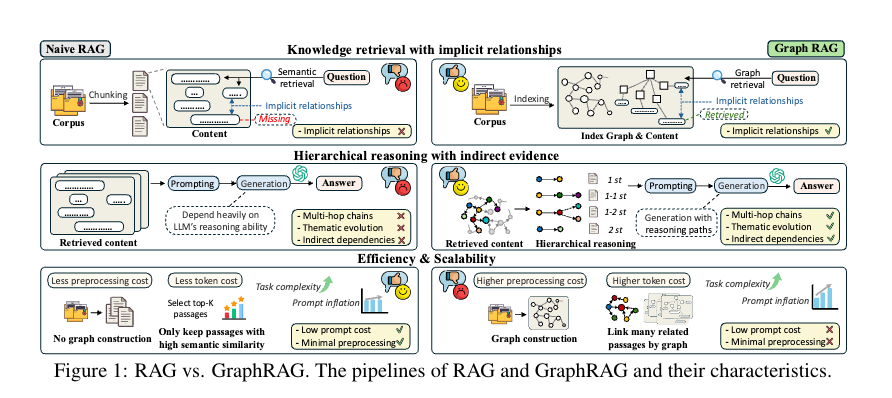
看几个点。
1、实验设定
为了说明GraphRAG是否有效,数据上包括两个数据集,一个是医学指南数据集,包含明确的层次结构和标准化协议;另一个是19世纪小说数据集,包含隐式的非线性叙事。
任务上包括四个:事实检索(要求从文本中检索孤立的知识点,主要测试精确的关键词匹配);复杂推理(要求通过逻辑连接多个知识点,测试模型的综合推理能力);上下文总结(要求将分散的信息综合成连贯的结构化答案,强调逻辑一致性和上下文理解)创意生成(要求在检索内容的基础上进行推理,生成新的内容,测试模型的创造性)
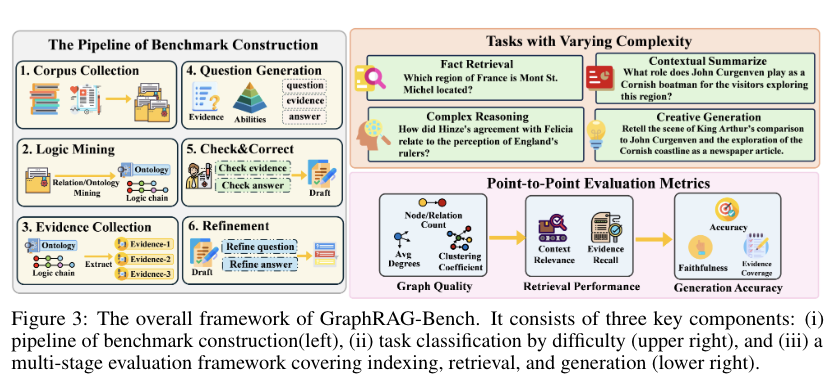
在评估对象上,选择了多种GraphRAG模型进行评估,包括GraphRAG(本地和全局)、HippoRAG、LightRAG、Fast-GraphRAG和RAPTOR等。
2、实验结论
还是从生成准确性、检索性能、图复杂性以及执行效率等几个点来说明问题:
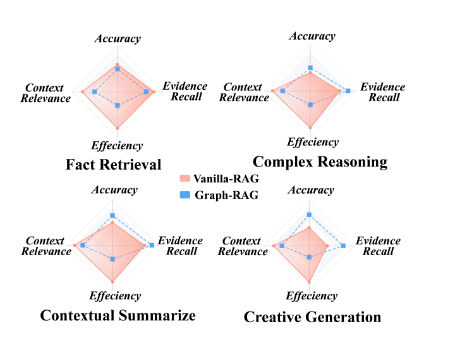
1)生成准确性方面,在简单事实检索任务中,基本RAG与GraphRAG的表现相当或更优;在复杂任务中,GraphRAG表现出明显的优势,特别是在复杂推理、上下文总结和创意生成任务中。
2)检索性能方面,在简单问题中,RAG在检索离散事实方面表现优异;在复杂问题中,GraphRAG在连接远距离文本片段方面表现出色。
3)图复杂性方面,不同GraphRAG实现生成的索引图在结构上存在显著差异,HippoRAG2生成的图密度最高,节点和边数最多,改善了信息的连接性和覆盖率。
4)执行效率方面, GraphRAG由于涉及额外的知识检索和图聚合步骤,显著增加了提示长度,特别是在复杂任务中,提示长度的增加可能导致冗余信息的引入,从而降低上下文相关性。
所以,归结起来,到底什么时候用GraphRAG,其实取决于其优势,也就是:
1)图结构的优势:GraphRAG通过构建外部结构化图来表示实体之间的关系和层次依赖关系,使得模型能够进行更复杂的逻辑推理和发现潜在的连接。
2)多跳推理能力:图结构允许模型跨越多个实体进行推理,解决多跳查询问题,而传统的RAG系统在处理多跳推理时存在局限性。
3)上下文理解深度:图结构有助于模型理解复杂的上下文关系,提高推理的深度和准确性,特别是在需要综合分析多个知识点的情况下。
4)信息组织和覆盖:图结构能够更好地组织和覆盖领域知识,使得模型在处理复杂任务时能够更全面地检索和整合相关信息。
参考文献
1、https://arxiv.org/pdf/2506.05690v1
2、https://arxiv.org/pdf/2506.03197
(文:老刘说NLP)