


研究背景:线上文章评分与MLLM的新机遇
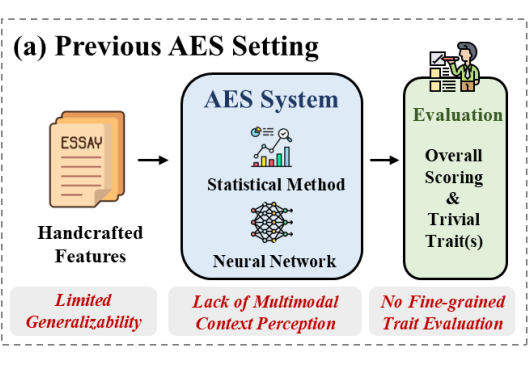
自动作文评分(AES)是教育评估中的重要技术工具,能实现对大规模写作的高效、稳定评分。然而,传统 AES 实现存在三大缺陷:
-
依赖手工特征,通用性差
-
难以评估细粒度写作特质
-
无法处理图文处境
随着 GPT-4o、Gemini 等大型多模态语言模型(MLLMs)的应用推广,AES 实现得以突破,直接依靠文本+图片输入进行特质评分。
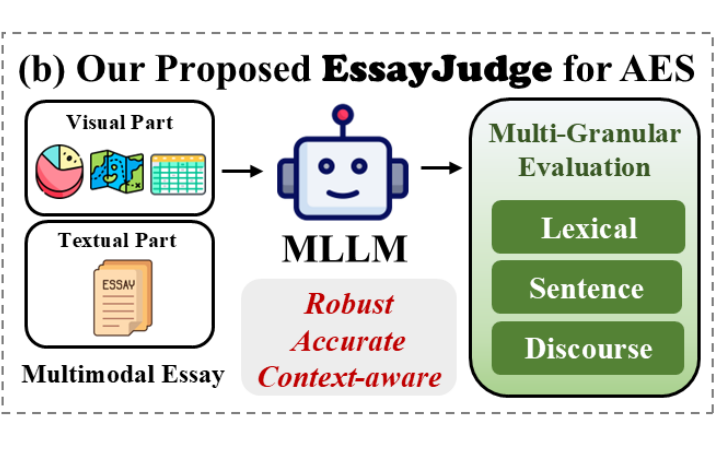
然而,MLLM 是否真正能够精确地采集细粒度写作经验,由于缺乏多模态输入(图片+文本)以及细粒度评分的高质量数据集,其准确度仍有很大疑问。

我们做了什么:EssayJudge出击
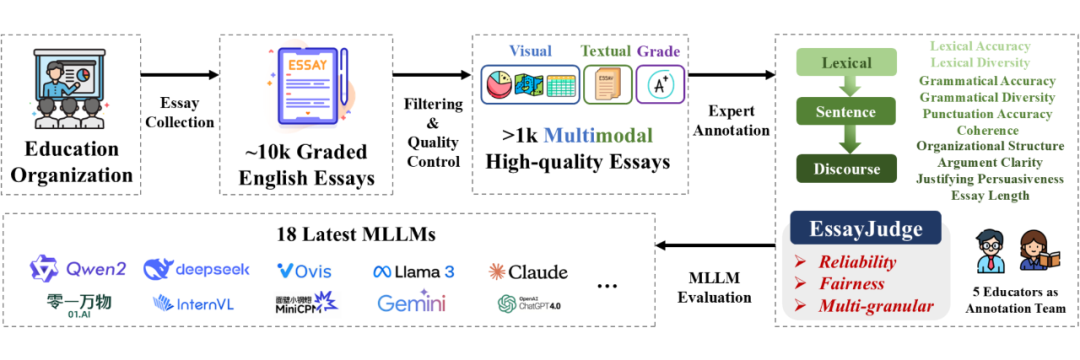
2.1 数据集构建
初始作文数据来自国内知名教育机构,题目设计合理、内容表达真实。
之后我们对原始数据进行了严格筛选,剔除低质量或评分缺失样本,保留具备图文联动特征的作文。
随后,由 5 位资深英语教师组成的团队对每篇作文在十个维度上进行多轮精细化评分:首轮由两位教师独立打分,若任一维度差异超过 1 分,则由第三方小组讨论裁定。最终建立了高一致性、高信度、公平性与细粒度(multi-granular)兼具的评分体系。
2.2 数据集特点
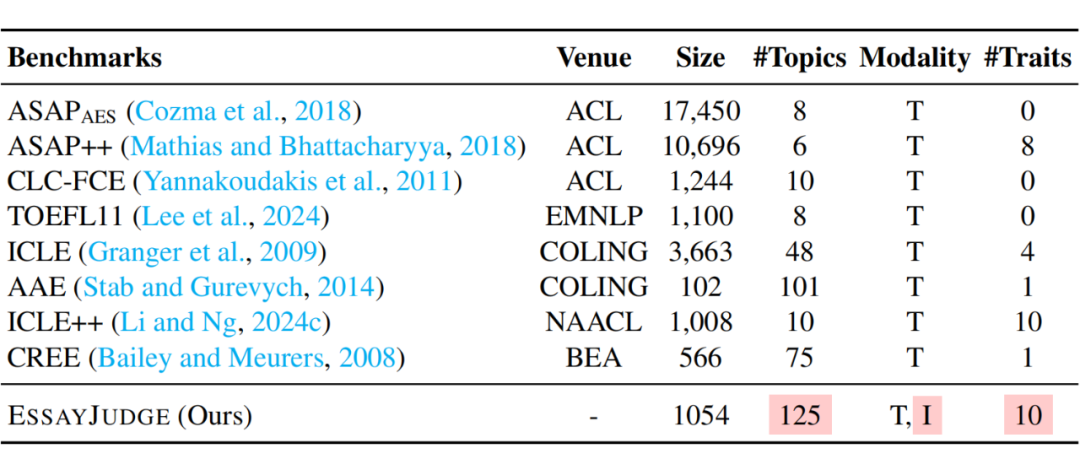
EssayJudge 是首个专为多模态大语言模型(MLLM)设计的细粒度图文作文评分 benchmark,覆盖十个评分维度,具有以下三大核心特性:
-
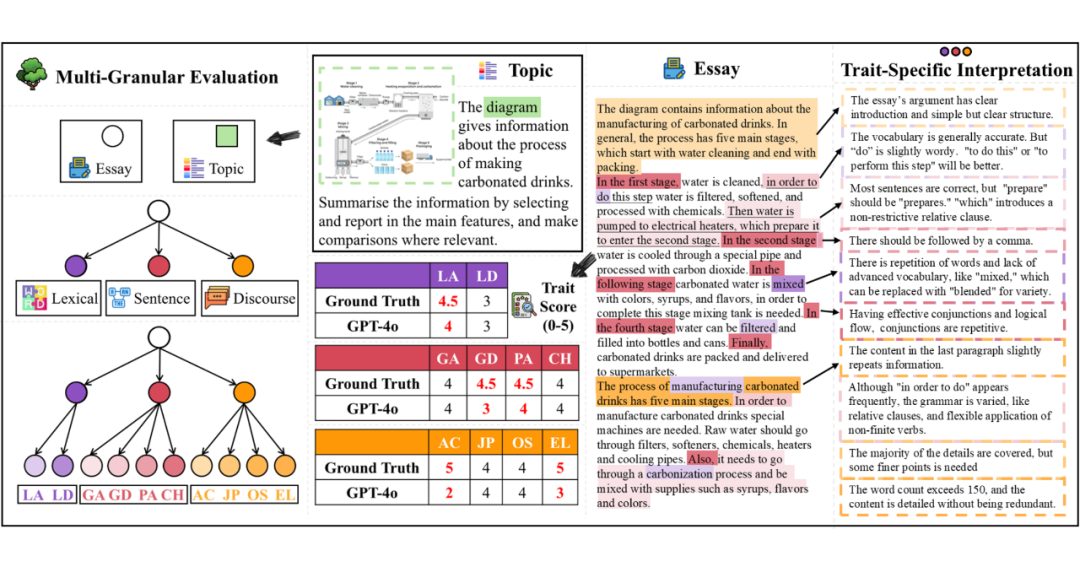
全线细粒度特质评分:构建涵盖词汇准确性(LA)、词汇多样性(LD)、语法准确性(GA)、语法多样性(GD)、标点准确性(PA)、句间连贯性(CH)、文章结构(OS)、论点清晰度(AC)、论证说服力(JP)以及文章长度(EL)等十项特质的细粒度评分框架,覆盖从词汇、句子到篇章三个层级,全面衡量写作质量。
-
大规模、高质量图文数据:收录 1,054 篇真实图文作文,涵盖 125 个多样主题,配套七类图表形式,包括流程图、柱状图、线图、表格、饼图、地图与组合图表,全面考验模型的图文信息整合与语义理解能力。

-
深度图文融合设定:作文内容高度依赖图像信息作为论据来源,促使模型在评分过程中充分理解图文关系,实现对上下文、推理链条的深层建模。

基准设计与评分系统
1. 10 项细粒度评分维度:
-
词汇层面:Lexical Accuracy (LA), Lexical Diversity (LD)
-
句子层面:Grammatical Accuracy (GA), Grammatical Diversity (GD), Punctuation Accuracy (PA), Coherence (CH)
-
文章层面:Organizational Structure (OS), Argument Clarity (AC), Justifying Persuasiveness (JP), Essay Length (EL)
2. 共进行了 18 个多模态大语言模型的综合对比,分为两类:
Open-Source MLLMs:我们评估了多个当前主流的开源多模态大模型,包括 Yi-VL、Qwen2-VL、DeepSeek-VL、LLaVA-NEXT、InternVL2、InternVL2.5、MiniCPM-V2.6、MiniCPM-LLaMA3-V2.5、Ovis1.6-Gemma2 以及 LLaMA-3.2-Vision。
上述模型均具备图文输入能力,广泛用于学术与产业中的多模态理解任务,代表开源社区在图文评分能力上的前沿水平。
Closed-Source MLLMs:同时,我们引入了多种闭源 SOTA 多模态模型作为性能上限的对比参考,包括 Qwen-Max、Step-1V、Gemini-1.5-Pro、Gemini-1.5-Flash、Claude-3.5-Haiku、Claude-3.5-Sonnet、GPT-4o-mini 以及 GPT-4o。
这些模型具备较强的图文推理与生成能力,是闭源系统中的代表性旗舰模型。

MLLM 全面评估结果

4.1 主要结论
Closed-Source 模型重现总优势:如上图大表我们可以发现,闭源模型普遍比开源模型表现好,其中 GPT-4o 突出地在 9 项特质中功能最强;Open-Source 表现有限:InternVL2 总优势最好,但完全落后 GPT-4o。
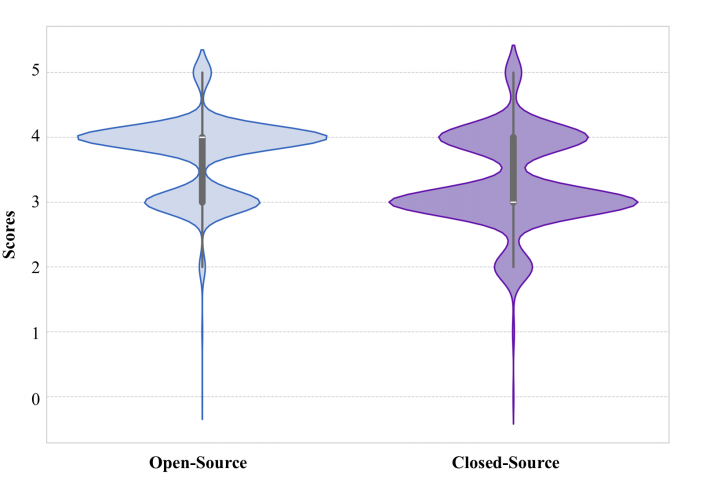
闭源多模态模型在评分行为上展现出更强的区分能力和更严格的评分倾向:参考下图的琴图,相比开源模型倾向于将作文得分集中在中间段(3-4 分),闭源模型的得分方差显著更高(0.49 vs. 0.34),能够更好地区分不同质量层次的作文。
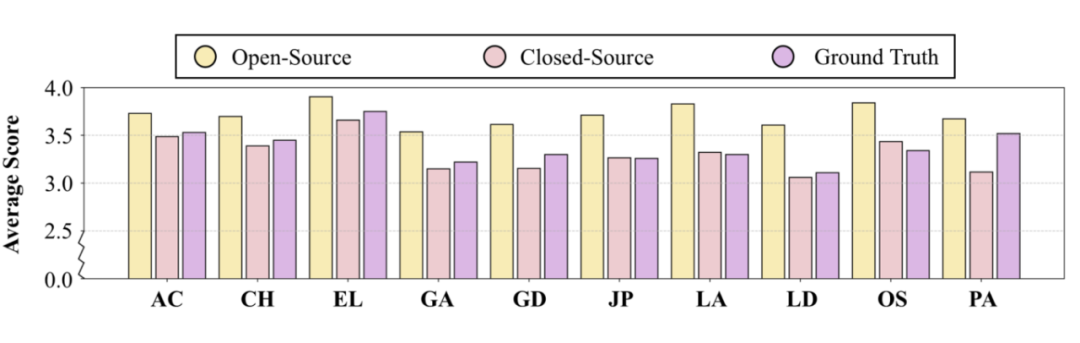
同时观察下图中的柱状图可以发现:它们在诸如论点清晰度、连贯性和语言特征等关键维度上普遍给出更低的分数,体现出对评分标准的高度遵循和更保守的打分策略。人工评分则通常位于两者之间。
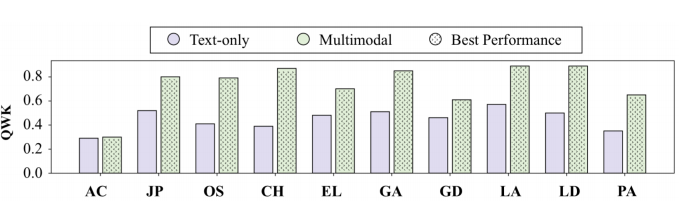
多模态模型能够有效运用多模态输入中的图片信息:消融实验表明,去除图像信息会导致 GPT-4o 在所有十个评分维度上的评分准确性下降,凸显了图像在补充论据、丰富语义层面的关键作用。
4.2 与特质有关的实验结论
闭源模型在宏观结构维度上存在明显短板:尽管闭源模型在词汇层面的评分(如词汇准确度)上表现出色,但在论点清晰度与文章长度两个涉及宏观逻辑与篇章长度判断的维度上得分偏低,反映出其在结构性与整体性评估方面仍有不足。
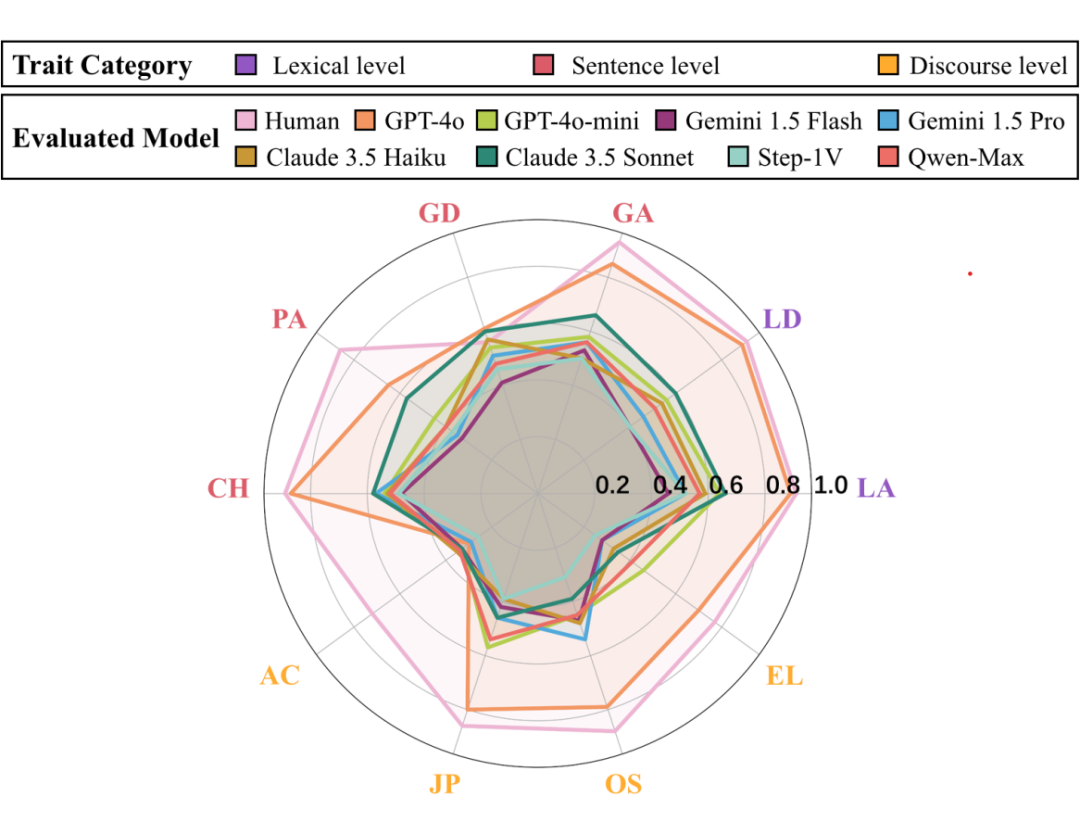
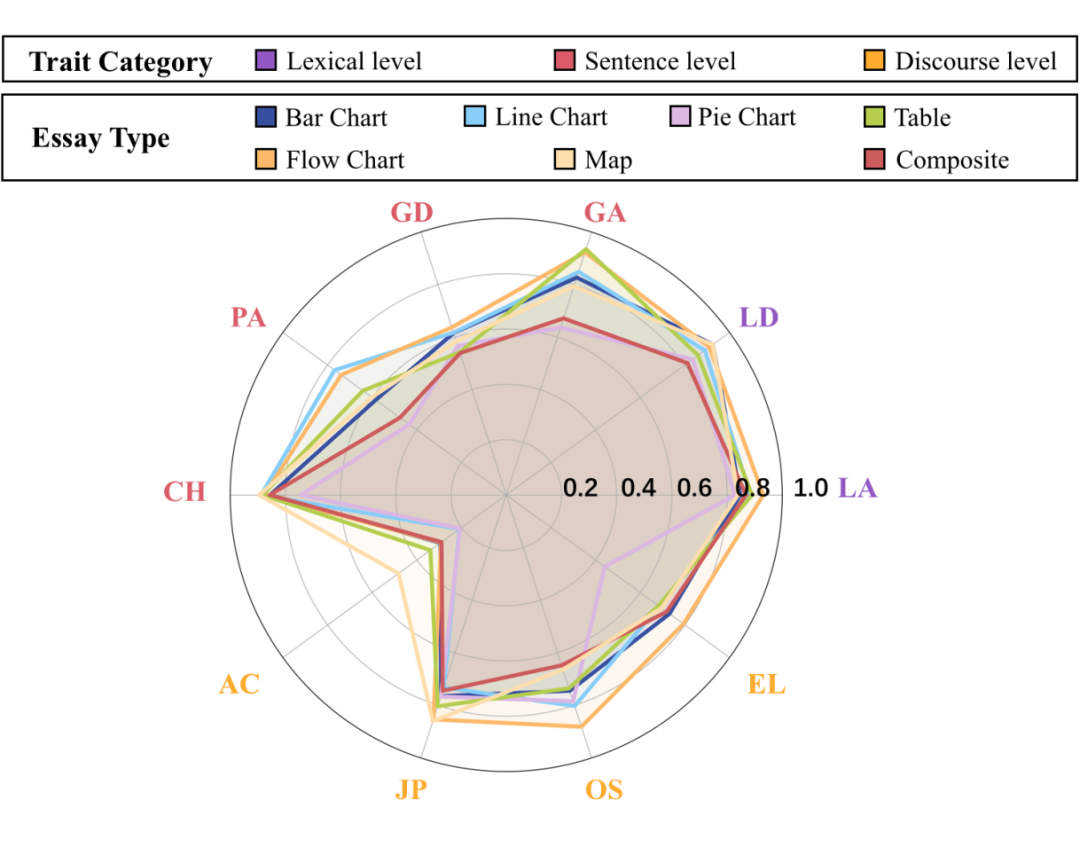
多模态模型在图表类型与评分维度之间存在互动优势:当评分对象为线图类(如折线图)作文时,多模态模型(如 GPT-4o、InternVL2)在连贯性维度上表现尤为突出,说明模型能够有效捕捉图像中连续性趋势信息,并将其映射至文本结构理解中。
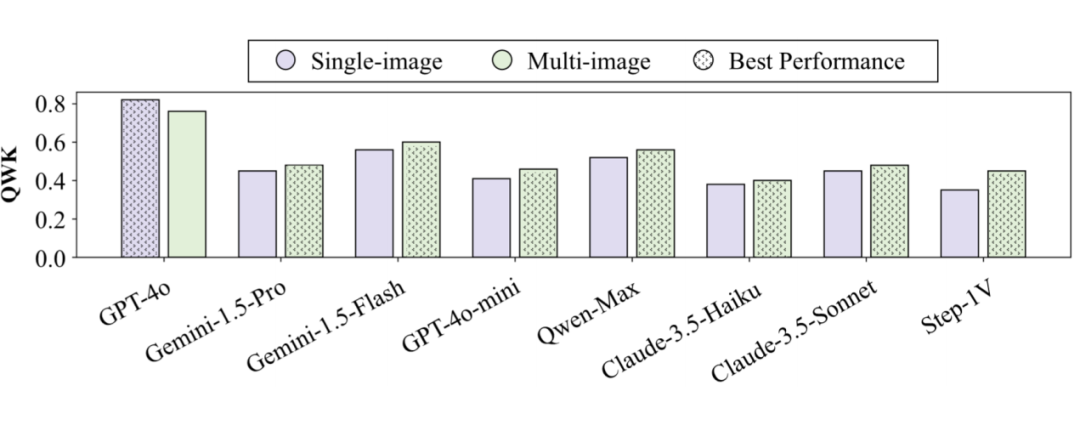
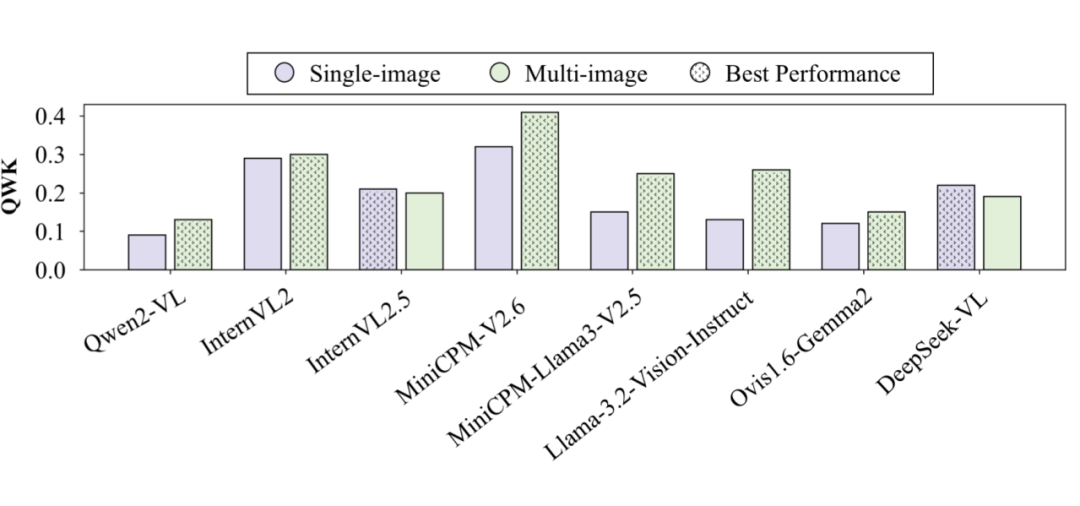
4.3 图片输入数量有关的实验结论
闭源模型更擅长处理单图场景下的作文评分:在单图(single-image)设定中,大多数闭源多模态模型的评分表现更稳定、更准确,说明它们在处理集中图文关系时具备更强的融合能力。

多图设定有助于增强模型对论证说服力的评估:在评估 Justifying Persuasiveness(论证说服力) 维度时,大多数模型在多图(multi-image)场景中表现更佳,表明多图信息有助于模型构建更完整的论证链条,从而提升其说服力评判能力。

结论与展望
EssayJudge 构建了首个面向 MLLM 的细粒度 AES 基准,但目前 MLLM 远未达到人类评分的效果。
当前围绕 EssayJudge 的研究已全面开始,数据集和代码已公开,快来试一下吧:
Github链接:
https://github.com/jsu360/EssayJudge
项目主页:
https://jsu360.github.io/EssayJudge_html/
论文链接:
https://arxiv.org/abs/2502.11916
(文:PaperWeekly)