
大模型推理太慢?来看——Sparse Transformers稀疏推理加速器。简单来说,这个项目通过稀疏化技术让 Transformer 大模型推理提速1.6-1.8倍,提供:
-
融合稀疏C++内核优化MLP层计算 -
差分权重缓存机制动态管理激活权重 -
CPU/CUDA双平台支持,完整工具链 -
开箱即用的LLaMA模型稀疏化实现
“差分权重缓存”技术会通过智能预测激活模式,只缓存真正需要的权重,实现6.7倍更快的缓存更新。项目还创新性地融合了Gate+Up投影操作,大幅减少内存访问开销。
目前在LLaMA 3.2 3B上实现了惊艳效果:首Token时间提升1.51倍(1.209s→0.803s),生成速度提升1.79倍,同时内存占用减少26.4%(13.25GB→9.75GB)。
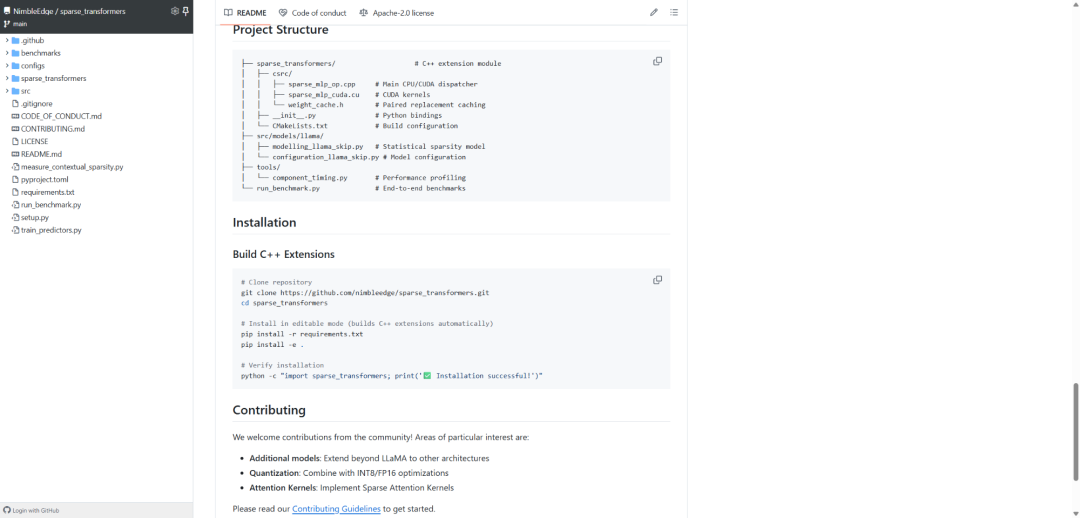
技术亮点包括配对替换算法、稀疏MLP前向计算、OpenMP并行化优化等。开发者可以直接通过pip安装使用,支持自定义稀疏性配置和性能基准测试。
参考文献:
[1] 项目地址:https://github.com/NimbleEdge/sparse_transformers
知识星球服务内容:Dify源码剖析及答疑,Dify对话系统源码,NLP电子书籍报告下载,公众号所有付费资料。加微信buxingtianxia21进NLP工程化资料群。
(文:NLP工程化)