

在人工智能领域,多模态模型的发展正逐渐改变我们对智能系统的认知。小红书与西安交通大学联合推出的DeepEyes项目,正是这一领域的前沿探索成果。它通过强化学习实现了“用图思考”的能力,无需依赖监督微调,为视觉推理和多模态任务提供了新的解决方案。

一、项目概述
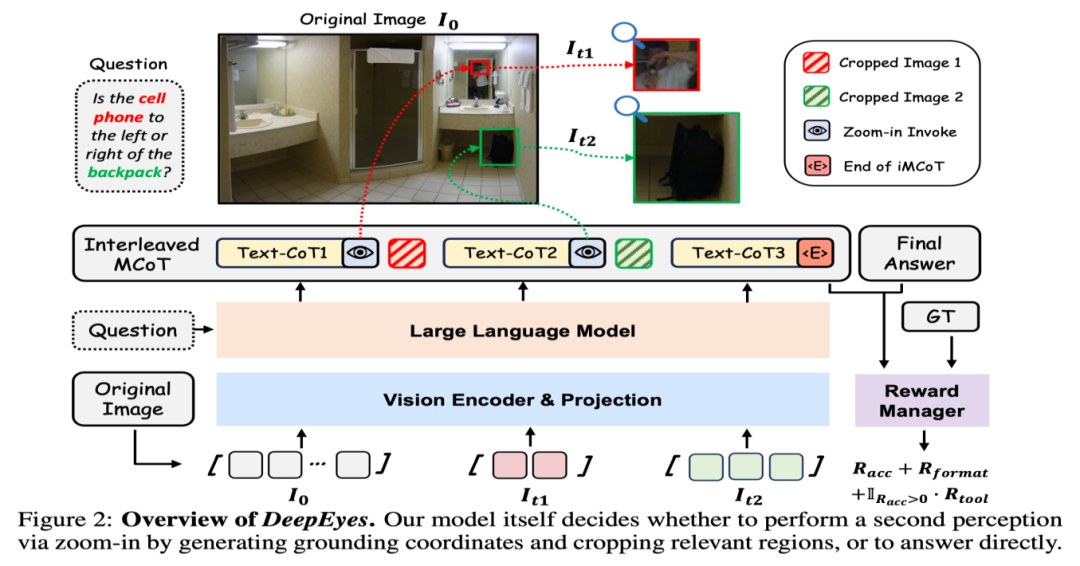
DeepEyes是一个基于端到端强化学习训练的多模态深度思考模型,由小红书团队和西安交通大学联合开发。它通过动态调用图像工具(如裁剪和缩放)增强对细节的感知与理解,实现了视觉与文本推理的无缝融合。该模型在高分辨率图像的视觉搜索任务中表现出色,准确率高达90.1%,并显著减少了幻觉现象,提升了模型的可靠性和泛化能力。
二、技术原理
(一)端到端强化学习
DeepEyes采用端到端强化学习(RL)进行训练,无需冷启动监督微调(SFT)。模型通过奖励信号直接优化行为,自主学习如何在推理过程中有效利用图像信息。奖励函数包括准确率奖励、格式奖励和条件工具奖励,确保模型在正确回答问题的同时高效使用图像工具。
(二)交错多模态思维链(iMCoT)
DeepEyes引入交错多模态思维链(Interleaved Multimodal Chain-of-Thought, iMCoT),支持模型在推理过程中动态交替使用视觉和文本信息。模型在每一步推理中决定是否需要进一步的视觉信息,基于生成边界框坐标裁剪图像中的关键区域,将区域重新输入模型,作为新的视觉证据。
(三)工具使用导向的数据选择
为激励模型的工具使用行为,项目采用工具使用导向的数据选择机制。训练数据经过精心筛选,确保样本有效促进模型的工具调用能力。数据集包括高分辨率图像、图表数据和推理数据,覆盖多种任务类型,提升模型的泛化能力。
(四)动态工具调用行为
在训练过程中,模型的工具调用行为经历三个阶段:初始探索、积极使用和高效利用。模型从最初的随机尝试逐渐发展到高效、准确地调用工具,最终实现与人类类似的视觉推理过程。

三、主要功能
(一)用图思考
DeepEyes能够直接将图像融入推理过程,不仅“看图”,还能“用图思考”。它在推理过程中动态调用图像信息,增强对细节的感知与理解。
(二)视觉搜索
在高分辨率图像中快速定位小物体或模糊区域,基于裁剪和缩放工具进行详细分析,显著提升搜索准确率。
(三)幻觉缓解
通过聚焦图像细节,减少模型在生成回答时可能出现的幻觉现象,提升回答的准确性和可靠性。
(四)多模态推理
在视觉和文本推理之间实现无缝融合,提升模型在复杂任务中的推理能力。
(五)动态工具调用
模型能自主决定何时调用图像工具,如裁剪、缩放等,无需外部工具支持,实现更高效、更准确的推理。
四、基准测试
(一)高分辨率基准测试
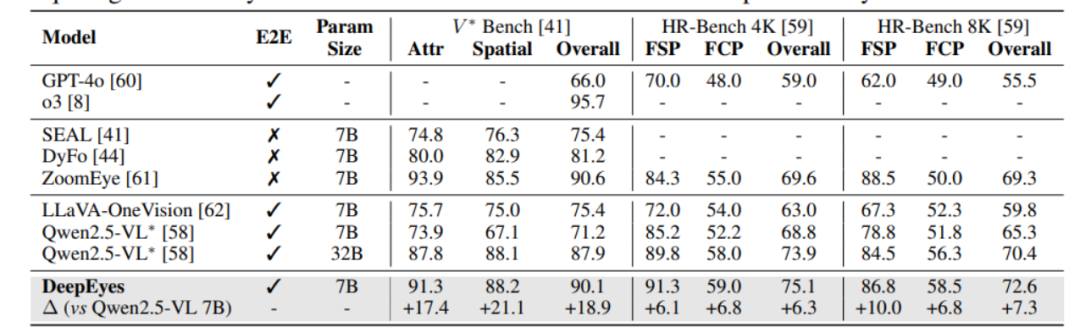
DeepEyes在高分辨率基准测试中表现出色。在V\* Bench上,7B模型的准确率达到了90.1%,相比其他开源模型有显著提升。在HR-Bench-4K和HR-Bench-8K上,准确率分别提升了6.3%和7.3%。
(二)视觉定位与幻觉缓解
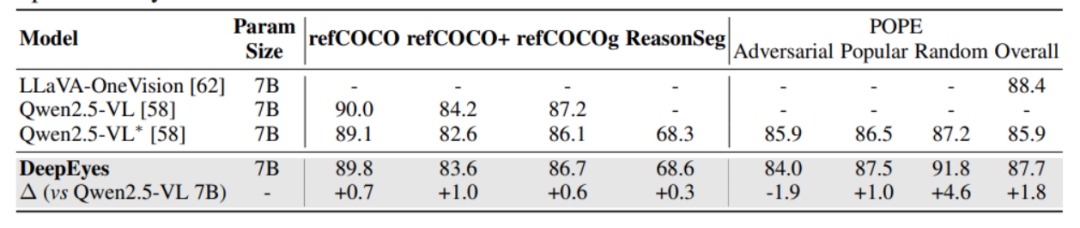
在视觉定位和幻觉缓解任务中,DeepEyes也展现了强大的能力。例如,在refCOCO、refCOCO+和refCOCOg等基准测试中,DeepEyes的准确率分别达到了89.8%、83.6%和86.7%,显著优于其他开源模型。
(三)多模态推理任务
在多模态推理任务中,DeepEyes在Math Vista、Math Verse、Math Vision等多个基准测试中均取得了优异的成绩,准确率分别达到了70.1%、47.3%和26.6%,显示出其强大的推理能力。

五、应用场景
(一)教育辅导
在教育领域,DeepEyes可以精准解析试卷中的图表和几何图形,将复杂的图形信息转化为详细的解题步骤,为学生们提供清晰、易懂的指导。学生们通过它的帮助,能够更高效地理解知识点,提升学习效率,让学习变得更加轻松愉快。
(二)医疗影像
对于医疗行业而言,DeepEyes能够对医学影像进行细致入微的分析,识别影像中的各种特征和病变信息,辅助医生做出更准确的诊断。在这个过程中,它大大提高了诊断的准确性和效率,为患者的健康保驾护航,节省了宝贵的医疗时间。
(三)智能交通
在智能交通系统中,DeepEyes可以实时分析路况图像,准确识别道路上的各种情况,如车辆行驶状态、交通标志等。基于这些信息,它能辅助自动驾驶系统做出更准确的决策,避免交通事故的发生,提升交通安全水平,让出行更加安全可靠。
(四)安防监控
安防监控工作中,DeepEyes可以分析监控视频,凭借强大的识别能力识别视频中的异常行为,如盗窃、暴力等。一旦发现异常,它会及时发出警报,增强公共安全和犯罪预防能力,让人们的生活环境更加安全稳定。
(五)工业制造
在工业制造的生产线上,DeepEyes可以对产品进行质量检测,精准识别产品中的缺陷和问题,同时还能对设备进行故障预测,提前发现潜在的故障隐患。通过这些功能,它提高了生产效率,降低了维护成本,为工业制造的高效运行提供了有力保障。
六、快速使用
(一)环境搭建
1. 安装依赖:
pip install -e .bash scripts/install_deepeyes.sh
2. 准备数据集:可以从Hugging Face下载训练数据。
(二)启动训练
1. 启动Qwen-2.5-72B-Instruct服务:
vllm serve /path/to/your/local/filedir \--port 18901 \--gpu-memory-utilization 0.8 \--max-model-len 32768 \--tensor-parallel-size 8 \--served-model-name "judge" \--trust-remote-code \--disable-log-requests
2. 配置训练环境:
wandb loginexport LLM_AS_A_JUDGE_BASE="http://your.vllm.machine.ip:18901/v1"export WORLD_SIZE=8
3. 启动训练脚本:
bash examples/agent/final_merged_v1v8_thinklite.sh(三)使用自定义工具
1. 创建自定义工具类,继承`ToolBase`,并实现`execute`和`reset`方法。
2. 在`verl/workers/agent/__init__.py`中导入自定义工具。
七、结语
DeepEyes作为小红书与西安交通大学联合推出的多模态深度思考模型,通过强化学习实现了“用图思考”的能力,显著提升了视觉推理和多模态任务的性能。它不仅在高分辨率图像的视觉搜索任务中表现出色,还在幻觉缓解和多模态推理任务中展现了强大的能力。DeepEyes的开源为研究人员和开发者提供了一个强大的工具,可以应用于教育、医疗、交通等多个领域。
八、项目地址
– 项目官网:https://visual-agent.github.io/
– GitHub仓库:https://github.com/Visual-Agent/DeepEyes
– HuggingFace模型库:https://huggingface.co/ChenShawn/DeepEyes
– arXiv技术论文:https://arxiv.org/pdf/2505.14362
(文:小兵的AI视界)