

本文第一作者杜恒辉为中国人民大学二年级硕士生,主要研究方向为多模态大模型视听场景理解与推理,长视频理解等,师从胡迪副教授。作者来自于中国人民大学,清华大学和北京腾讯 PCG AI 技术中心。
我们人类生活在一个充满视觉和音频信息的世界中,近年来已经有很多工作利用这两个模态的信息来增强模型对视听场景的理解能力,衍生出了多种不同类型的任务,它们分别要求模型具备不同层面的能力。
过去大量的工作主要聚焦于完成单一任务,相比之下,我们人类对周围复杂的的世界具有一个通用的感知理解能力。因此,如何设计一个像人类一样对视听场景具有通用理解能力的模型是未来通往 AGI 道路上一个极其重要的问题。当前主流的学习范式是通过构建大规模的多任务指令微调数据集并在此基础上直接做指令微调。然而,这种学习范式对于多任务学习而言是最优的吗?
最近中国人民大学高瓴人工智能学院 GeWu-Lab 实验室,清华大学和北京腾讯 PCG AI 技术中心合作发表的 CVPR 2025 论文指出,当前这种主流的学习范式忽视了多模态数据的异质性和任务间的复杂关系,简单地将所有任务联合训练可能会造成任务间的相互干扰。
为了有效实现任务间的显示互助,作者团队提出了多模态大模型学习的新范式,分别从数据和模型两个角度实现了多模态场景理解任务的高效一统,并在多个场景理解任务上超过了垂类专家模型,数据集、模型和代码全部开源。目前工作还在进一步拓展中,欢迎感兴趣的领域专家加入,共同构建一个统一的理解、生成与推理的框架。如有兴趣,请邮件联系 dihu@ruc.edu.cn。

-
论文标题:Crab: A Unified Audio-Visual Scene Understanding Model with Explicit Cooperation
-
论文链接:https://arxiv.org/abs/2503.13068
-
项目主页:https://github.com/GeWu-Lab/Crab
统一的多模态场景理解能力展示
时序定位
输入一段音视频,让模型找到发生的音视频事件并定位出时序片段。
空间定位
输入一段音频和一张图像,让模型定位出图片中发声的物体为止。
时空推理
输入一段乐器演奏的音视频场景,让模型回答相关问题,涉及到时序和空间信息的理解以及推理。
像素级理解
输入一段音频和一张图片,让模型分割出图片中发声的物体,具体包含 S4, MS3, AVSS 和 Ref-AVS 等多种分割任务。




视觉和听觉信息是我们人类接触最多的两类信息,近年来已经有很多工作开始探究基于这两个模态的视听场景理解任务,主要可以分为时序定位、空间定位、像素级理解和时空推理等四种不同类型的任务,它们分别要求模型具备不同层面的能力。过去大量的工作聚焦于完成单一任务,相比之下,我们人类对周围复杂的世界具有一个通用的感知理解能力。因此,让模型也像人类一样具有统一的视听场景理解能力是具有重要意义的。
随着多模态大语言模型的发展,构建大规模的指令微调数据集并将各种不同的任务直接进行联合训练已经成为当前主流的学习范式。然而,这种学习范式忽视了多模态数据的异质性和任务间的复杂关系,简单地将所有任务联合训练可能会造成任务间的相互干扰,这种现象在之前的工作中已经被证实,并且这个问题对于任务间差异较大的视听场景理解任务来说则更为重要。为了有效解决上述问题,本文分别从数据和模型的角度针对性地提出了一个统一的显示互助学习范式来有效实现任务间的显示互助。为了明确任务间的互助关系,首先构建了一个具有显示推理过程的数据集 AV-UIE,它包含具体的时序和空间信息,可以有效建立任务间的互助关系。然后为了进一步在学习过程中促进任务间的相互协助,本文提出了一种具有多个 Head 的类 MoE LoRA 结构,每个 Head 负责学习多模态数据交互的不同层面,通过这种结构将模型的不同能力解耦,让任务间的互助关系显示地展现出来,共享的能力在不同任务间建立起相互协助的桥梁。
AV-UIE: 具有显示推理过程的视听场景指令微调数据集
从数据的角度来看,现有视听场景理解数据集的标签是简单的单词或者短语,这样简单的标签在训练过程中并不能显著地帮助到其它任务,或者说只能以一种隐式的方式增强模型的训练效果,我们并不能确保一定是对其它任务有帮助的。为了进一步地促进任务间的显示互助并将互助关系显示地体现出来,本文提出了具有显示推理过程的视听场景指令微调数据集 AV-UIE,通过细化现有数据集的标签,额外增加了显示的推理过程,其中包含具体的时空信息,这些信息明确了任务间的互助关系。
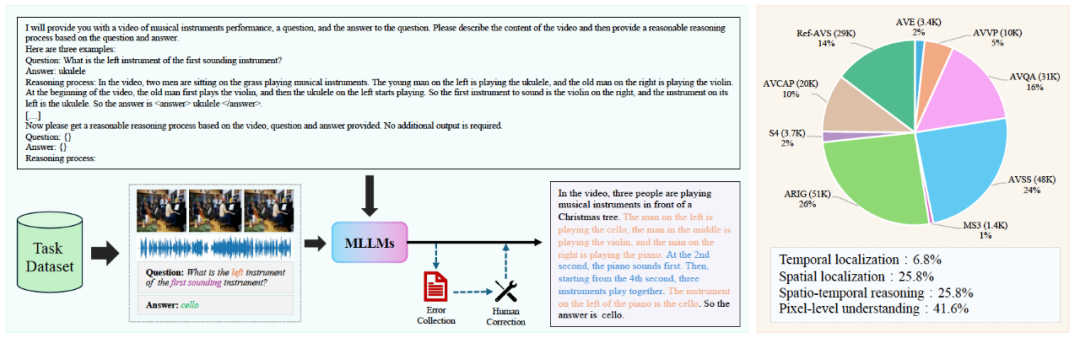
图 1. 具有显示推理过程的 AV-UIE 数集构造流程和统计分析
图 1 展示了具体的构建过程以及对数据集的统计分析,通过 in-context learning 的方式利用现有的强大的多模态大模型进行标注,从不同任务中的数据中获取音视频场景,为了保证结果的准确性和推理过程的合理性,原有数据的标签也作为输入,让 Gemini 1.5 Pro 针对该场景输出带有时序和空间等信息的显示推理过程。为了保证数据的质量,最终再由人工进行检查纠正。在训练过程中这些细化后的标签能够鼓励模型准确理解视听场景内容并输出相应的时空信息,以此来增强模型特定的能力,从而帮助到其它依赖这些特定能力的任务。图 2 展示了 AVQA 和 AVVP 这两种任务实现显示互助的数据样例,不同的颜色表示不同类型的时空信息,这两个任务都能够受益于增强后的空间定位和时序定位能力。
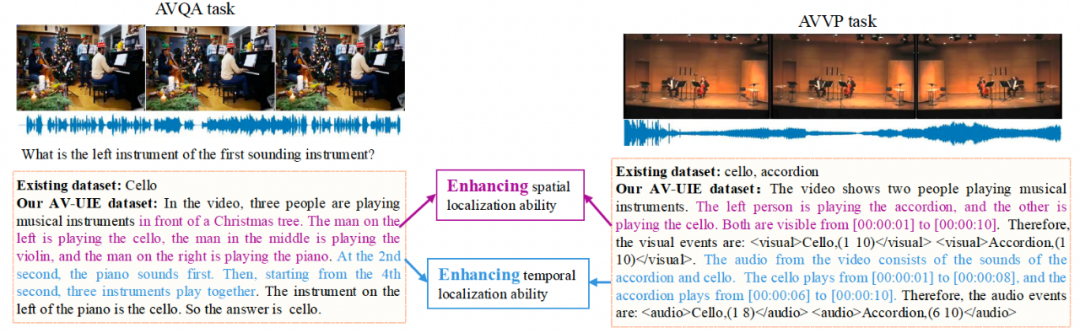
图 2. AVQA 和 AVVP 任务通过显示推理过程实现相互帮助的示例
AV-UIE 数据集包含九种任务的数据,总共 200K 训练样本。其中,时序定位任务包含 AVE 和 AVVP,数据占比 6.8%,空间定位任务包含 ARIG,数据占比 25.8%,像素级理解任务包含 S4,MS3,AVSS 和 Ref-AVS,数据占比 41.6%,时空理解任务包含 AVQA,数据占比 25.8%。相比于其它的指令微调数据集,尽管每一个任务的训练样本数比较小,但是在显示推理过程的帮助下,任务间的显示互助仍然可以增强模型在单个任务上的性能。
Crab: 实现任务间显示互助的统一学习框架
从数据的角度保证了模型可以输出带有时序信息的显示推理过程,这是从结果上对模型进行约束,显示地增强不同类型的能力,但是如何保证模型在学习过程中可以有效地学到这些不同的能力呢?为此,本文提出了一个视听场景理解的统一学习框架,图 3 展示了模型的整体架构,主要包括三个统一的多模态接口,分别用来处理 audio, visual 和 segmentation mask 数据,一个具有 interaction-aware LoRA 结构的大模型,用于在学习过程中有效学习数据交互的不同层面从而实现任务间的显示互助。
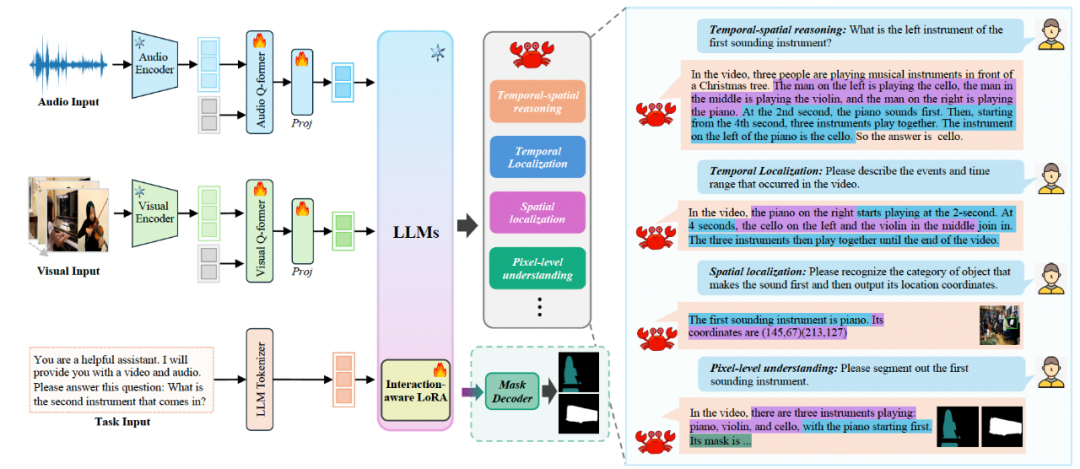
图 3. 模型总体架构
传统的 LoRA 结构由一组对称的 A 矩阵和 B 矩阵组成,用于在下游任务上高效微调模型,具有多组对称的 AB 矩阵的 LoRA MoE 结构通常被用来多任务微调,每一组 LoRA 负责解决单个任务。为了进一步地促进任务间的相互协助,本文提出的 Interaction-aware LoRA 结构(如图 4 所示)由一个共享的 A 矩阵和多个不同的 LoRA Head B 矩阵组成,每个 Head 期望去学习数据交互的不同层面,进而具备不同的能力。为了有效区分不同的 Head,额外增加一个 Router 用来给不同的任务分配不同的权重。例如,在学习过程中,时空推理任务 AVQA 聚焦于增强模型的时序和空间定位能力,那么就会更多的激活对应 Head 的参数,增强它们特定的能力,而其它的时序定位和空间任务都可以受益于这些增强后的 Head。从这个角度来说,模型的能力被解耦成多个特定的能力,模型可以显示地依赖这些能力完成不同类型的任务,而多个任务间共享的能力建立起了任务间协助的桥梁。
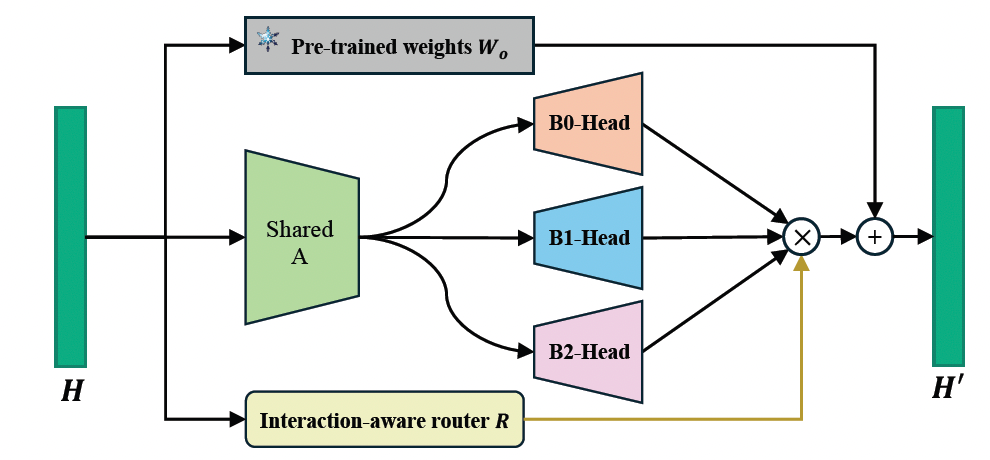
图 2. 具有多个 LoRA head 的 Interaction-aware LoRA 结构
实验与分析
为了证明显示互助学习范式的有效性,本文分别对比了在所有任务上通用的模型以及在单个任务上专有的模型,并提供了全面的消融实验对比结果。表 1 展示了与多个任务上的通用模型的对比结果,相比于其它模型,本文提出的 Crab 统一学习框架在所有类型的任务上具有更加通用的理解能力,并且在多个任务上取得了更好的表现。这表明了 Crab 在视听场景通用理解能力方面的优越性。

表 1. 与多个任务上的通用模型的对比结果
表 2,3,4,5 分别展示了与时序定位、空间定位、像素级理解和时空推理等四种类型任务的专有模型对比结果,可以看到在 AVE、ARIG、AVQA 等任务上 Crab 均优于单个任务上的专有模型,在 AVVP 和 AVS 任务上取得了相近的表现。表 6 展示了全面的消融实验结果,相比于单个任务,简单的多任务 LoRA 微调并不能充分实现任务间的相互协助,甚至在一些任务上可能会降低性能。相比之下,在显示互助的学习范式下,任务间的相互干扰被有效缓解,任务间的相互协助提高了单个任务的性能。
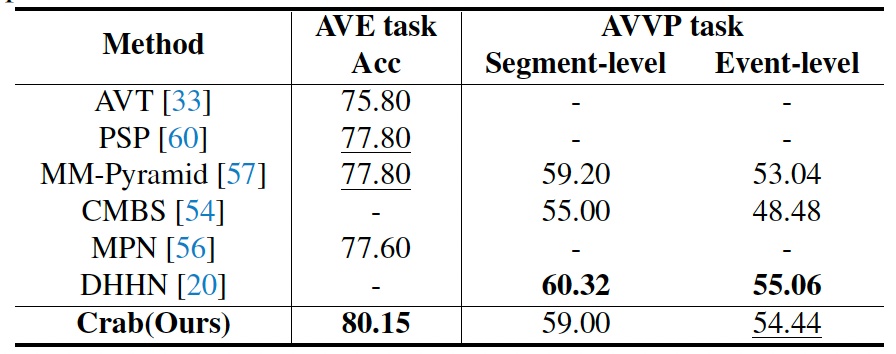
表 2. 与时序定位任务专有模型对比结果

表 3. 与空间定位任务专有模型对比结果
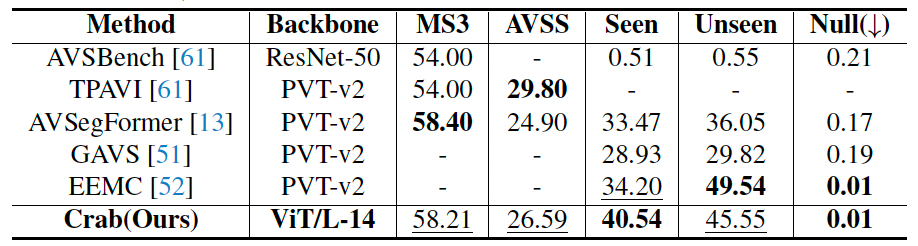
表 4. 与像素级理解任务专有模型对比结果
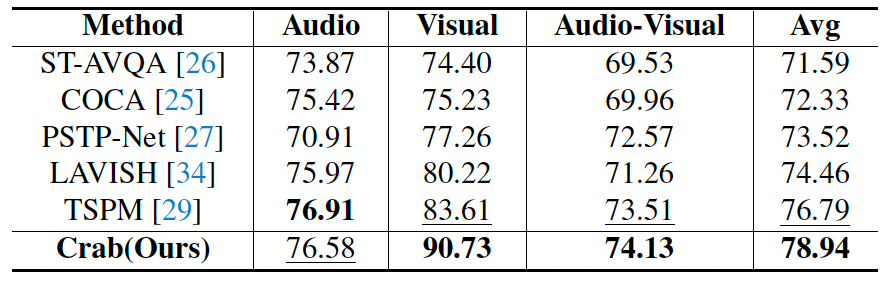
表 5. 与时空推理任务专有模型对比结果
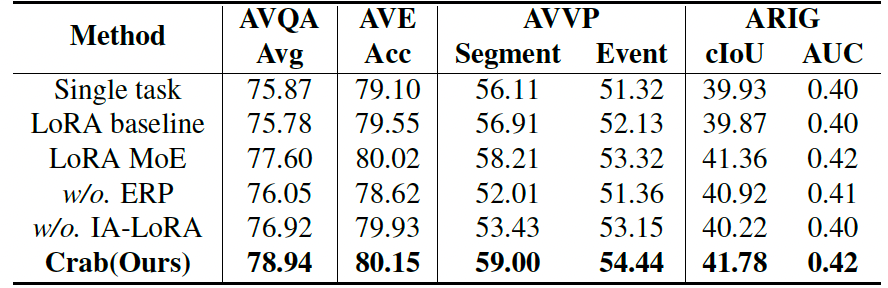
表 6. 全面的消融实验对比结果
为了进一步证明任务间显示互助的过程,本文对多个 LoRA Head 进行了可视化分析实验。在推理过程中,对于每个任务的多模态输入数据,每个 LoRA Head 会产生一个权重,权重越大,表明完成该任务越依赖于这个 Head。图 3 对比了 3 个 Head 在不同任务上的权重,左图是 B1 和 B2,右图是 B2 和 B3。可以发现两点:1)相同类型的任务对不同 Head 的依赖程度是类似的,它们对不同 Head 的依赖权重分别形成不同的簇;2)不同任务对 3 个 Head 的不同依赖性表明每个 Head 具备不同的能力。这表明模型的能力被解耦成多种不同的能力,多个任务间可能会依赖于同一种能力,因此它们可以建立相互协助的关系。
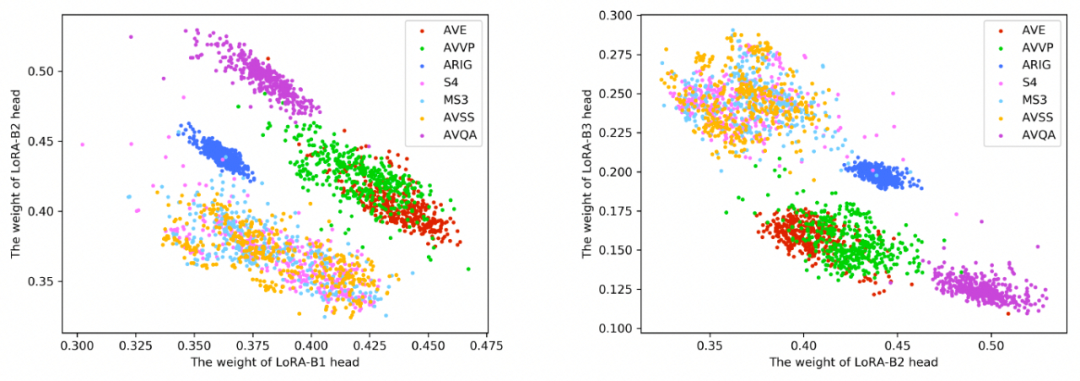
图 3. 3 个 LoRA Head 的权重可视化
总述
本文分别从数据和模型的角度出发,提出了统一视听场景理解的显示互助范式来实现任务间的显示互助,大量的实验结果以及可视化分析均证明了该范式的有效性。我们希望本文提出的想法可以为该领域的发展提供新的研究视角,并且在未来的工作中我们将聚焦于多模态推理的新范式,希望将现有的多模态推理工作提升到一个新的高度。
©
(文:机器之心)