

邮箱|damoxingjidongzu@pingwest.com
6 月 11 日,Meta AI 研究团队最新发布的开源模型 V‑JEPA 2,通过对超过一百万小时的原始视频学习,建立起对物理世界的“直觉世界模型”,无需人工标注,能帮助 AI Agents 像人类一样理解重力、物体交互并规划行动。
“像人一样推理” 不再是幻想
传统机器视觉只能“看”但不会“想”。V‑JEPA 2 则突破了这一局限:它学会了“球掉下桌子不会消失”、“拿锅铲会把食物转移到盘子里”,这类从婴幼儿时期就具备的直观物理常识 。
目标是让 AI Agents 在物理世界中实现“理解—预测—规划—执行”闭环能力。

Meta 副总裁兼首席人工智能科学家杨立昆 Yann LeCun 亲自出镜并提到:“世界模型将引领机器人进入新时代,让机器行动前先思考,即使面对从未见过的环境”。
零标注训练:原始视频+行为微调就能用
V-JEPA 2 采用联合嵌入预测架构 (JEPA) 构建,包含两个主要组件:
编码器:接收原始视频并输出嵌入,以捕获有关观察世界状态的有用语义信息。
预测器:接收视频嵌入和关于要预测的内容的附加上下文,并输出预测的嵌入。
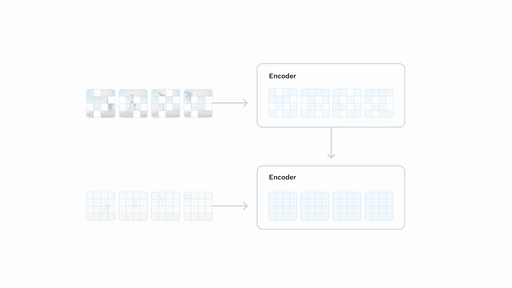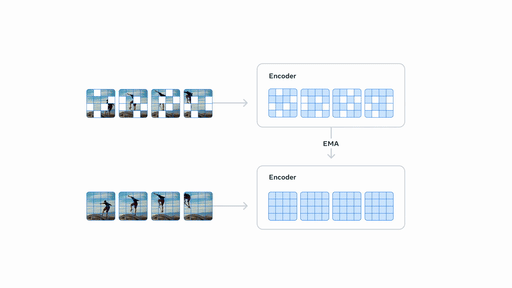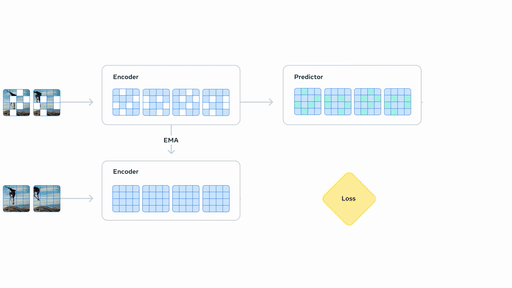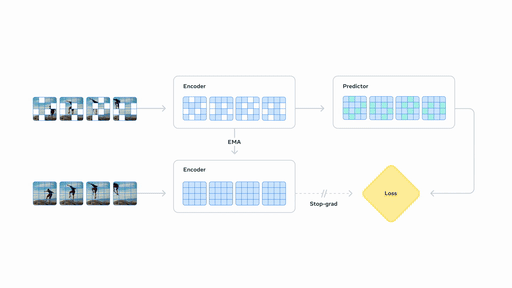
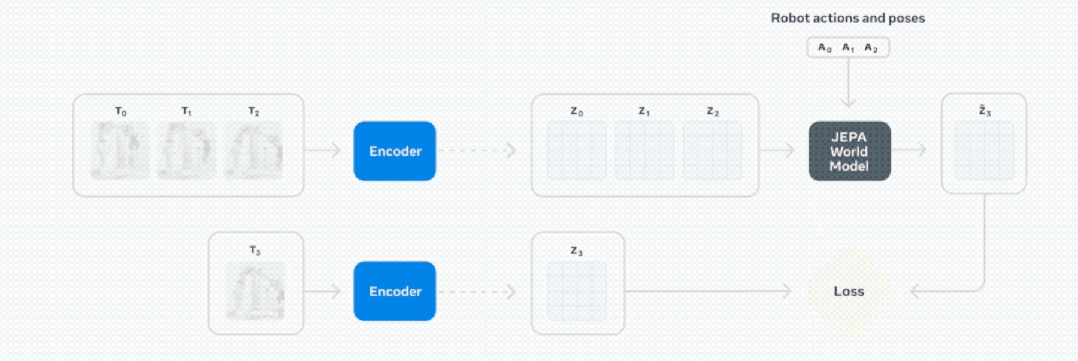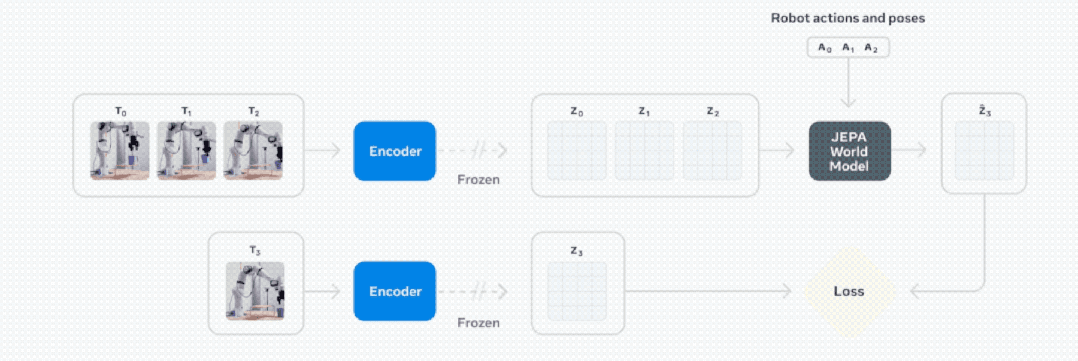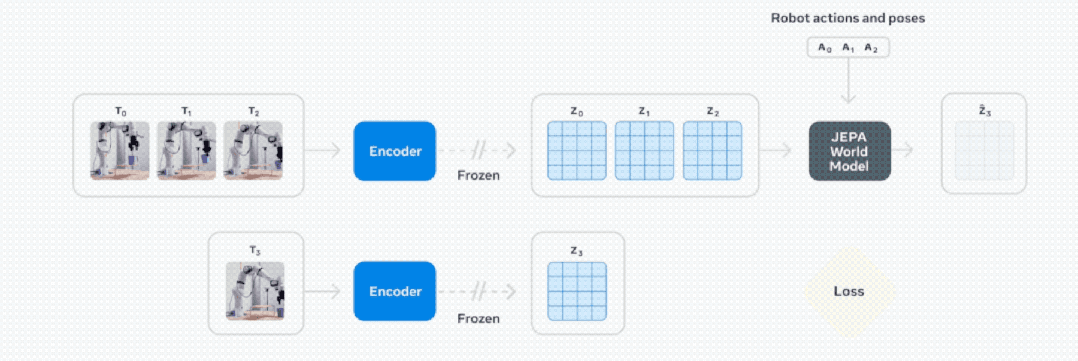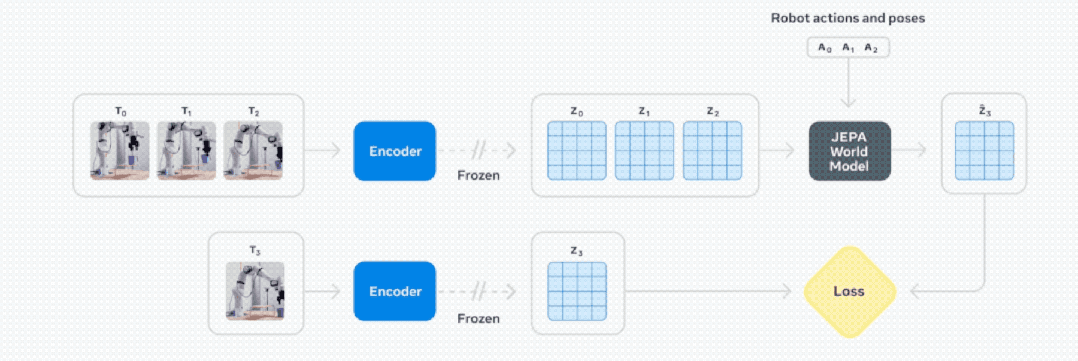
基于视频的自监督学习来训练 V-JEPA 2,无需额外的人工注释即可在视频上进行训练。
V-JEPA 2 训练包含两个阶段:无动作预训练,以及后续的动作微调。
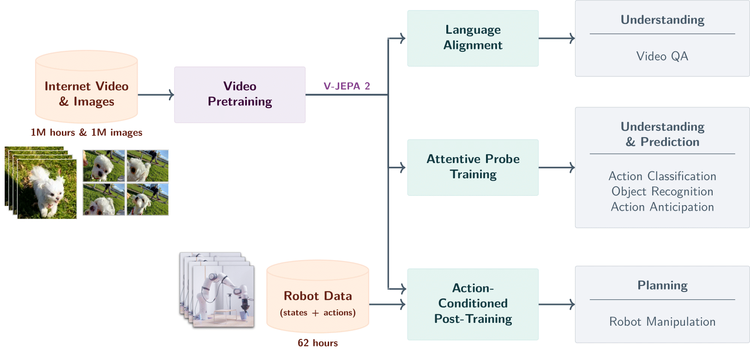
无动作预训练:利用超过一百万小时视频,通过自监督学习(masked latent prediction)方式,学习抽象特征的上下文关系。
动作微调:使用 62 小时机械臂操作视频微调,使其将视觉理解转化为实际行动指令,且无需为每个新环境重建数据集。
在 Meta 的实验室测试中,搭载 V-JEPA 2 的机器人成功完成了涉及不可见物体的拾取和放置任务,仅使用视觉子目标作为指导,成功率高达 65% 至 80%。该系统的工作原理是设想候选动作的结果,并在每一步中选择最佳动作。

多任务能力提高:不仅看视频,还能具体做
数据显示,V‑JEPA 2在 SSv2、EK‑100、Diving48 等动作识别任务中全面超越此前模型,提升显著。

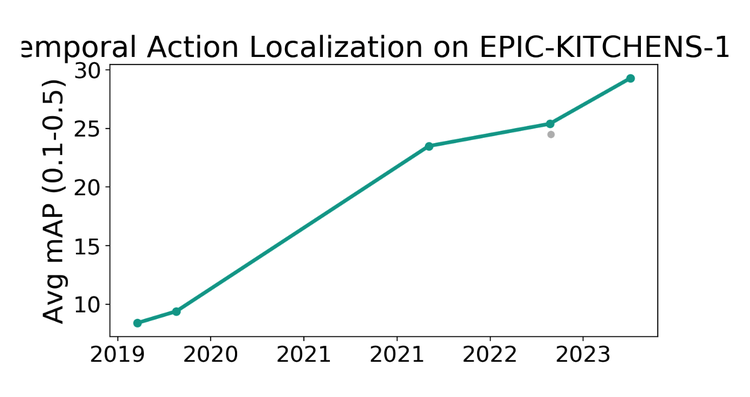
在机器人执行任务时,V‑JEPA 2‑AC 通过 latent predictor (潜在预测)生成动作序列,控制流畅,这一过程比传统模型如 Nvidia Cosmos 快约30 倍。
在实验中,V‑JEPA 2 能够通过输入目标图像(例如“将杯子拿到桌子右侧”),在完全未见过的环境中预测一系列合理步骤并逐步实现目标。
这种“看到目标就能推断下一步”的能力,体现出模型在视觉空间下自回归规划的强大zero‑shot 通用性。
为 AI 积累“常识”:不仅看,还能推理频率和因果
除了 V‑JEPA 2 之外,Meta 还发布了三个新的基准来评估 AI 对物理现象的理解:
IntPhys 2:检测配对视频中不合理的物理现象。

下载 IntPhys 2:
https://github.com/facebookresearch/IntPhys2
MVPBench:使用最少的视频对来测试因果理解。
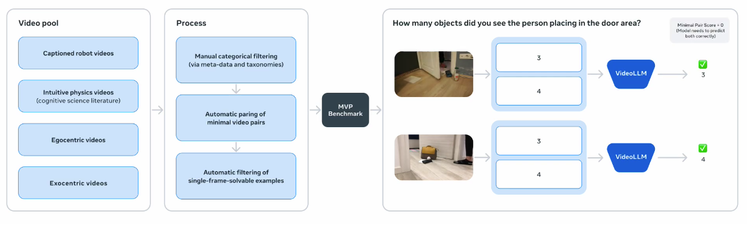
下载 MVPBench:
https://github.com/facebookresearch/minimal_video_pairs
CausalVQA:评估模型是否可以根据物理因果关系回答“如果”和“下一步做什么”的问题。
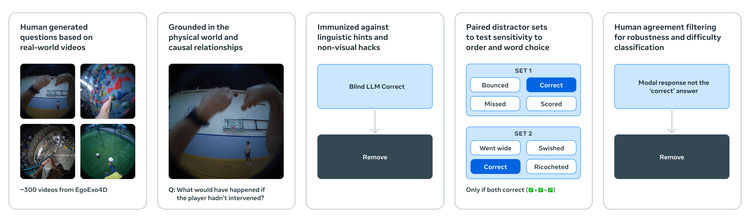
下载 CausalVQA:
https://github.com/facebookresearch/CausalVQA
Meta 指出,虽然人类在这些任务上的准确率高达 95%,但当前的视频模型(包括 V-JEPA 2)仍然远远落后,凸显了改进的空间。
开源资源:想试就能试
Meta 已在 GitHub 上发布完整 PyTorch 代码与预训练模型,遵循 MIT/Apache-2.0 开源许可 。
开发者只需几行代码加载模型,就能用于视频理解、物理推理、甚至 robotics 应用,这意味着研究和商业团队都能快速上手。
在 V‑JEPA 2 基础上,研究者正探索更强的 seq‑JEPA 架构:它能处理多视角短视频,通过自回归学习视角不变性与层级预测,具备更强情境理解与规划深度。
GitHub 开源地址:
https://github.com/facebookresearch/jepa
V‑JEPA 2 的意义,远不止是一项模型能力的跃升。在这个模型中,机器第一次具备了“观察–理解–行动”的闭环能力:无需脚本,不靠标签,只凭模糊的视觉目标,它就能推演出合理的路径,像个学徒一样,在世界中“试着做”。
Meta 的下一站,是多时间尺度的分层世界模型、多模态的感知整合系统——那些曾属于人类认知系统的复杂能力,正逐渐被建构出来。我们所处的,或许正是那个“机器获得常识、具备直觉”的临界点。
参考资料:
https://ai.meta.com/blog/v-jepa-2-world-model-benchmarks/
https://github.com/facebookresearch/vjepa2?tab=readme-ov-file
*文中插图来源于 Meta 官方论文和 GitHub 图表

(文:硅星GenAI)