
SurveyForge团队 投稿
量子位 | 公众号 QbitAI
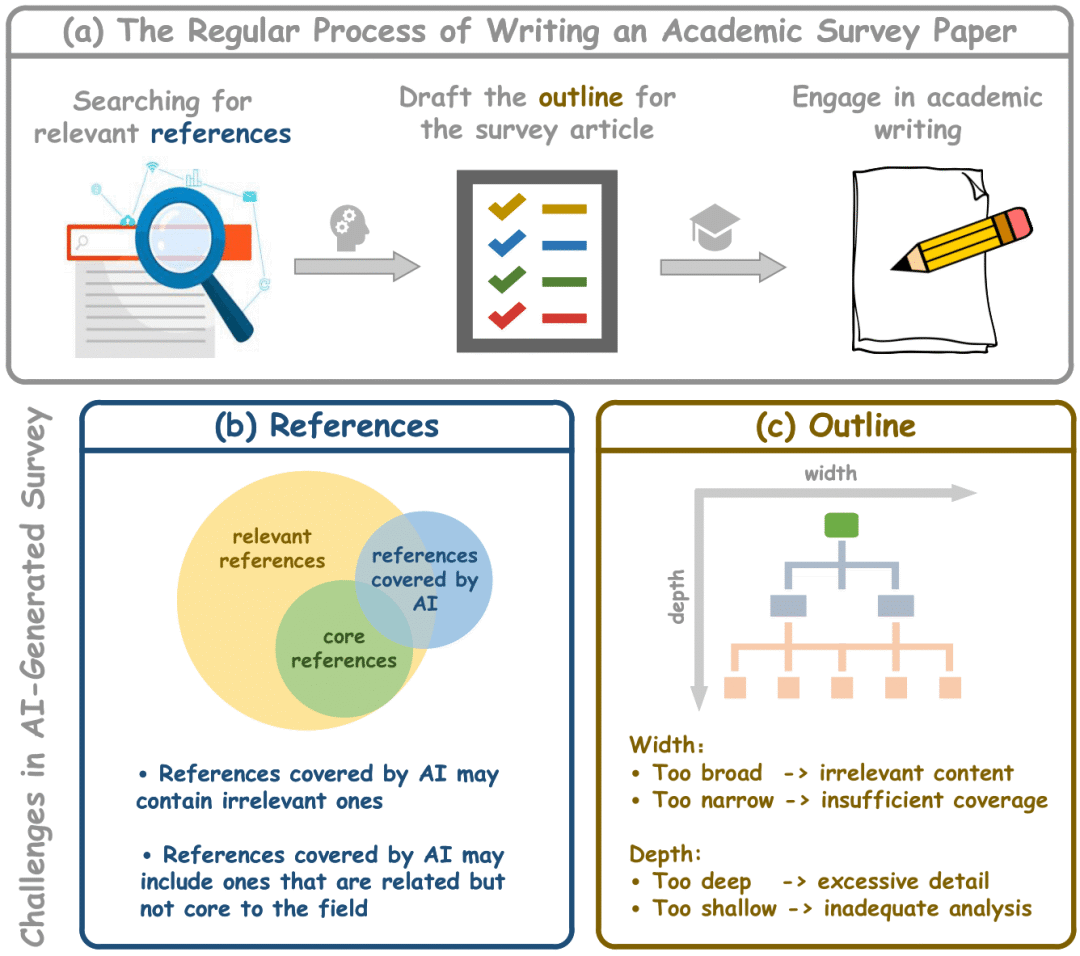
学术综述论文在科学研究中发挥着至关重要的作用,特别是在研究文献快速增长的时代。传统的人工驱动综述写作需要研究者审阅大量文章,既耗时又难以跟上最新进展。而现有的自动化综述生成方法面临诸多挑战:
AI生成的综述结构往往缺乏连贯逻辑,组织结构较差,存在宽度和深度的结构失衡问题;在参考文献方面,经常无法引用真正相关和有影响力的文献,容易引用无关文献而忽略核心贡献;评估方式主要依赖LLM整体质量评估,缺乏对大纲质量、参考文献相关性等关键方面的细粒度分析。
在此背景下,上海人工智能实验室联合复旦大学、上海交通大学等多家单位,提出了SurveyForge——一个自动化生成高质量学术综述论文的创新框架,该研究已被ACL 2025主会议接收。
实验结果显示,SurveyForge在所有关键指标上都实现了显著提升:核心参考文献覆盖率提升了近一倍,大纲质量接近人工撰写水平,内容质量在多个维度均超越现有方法。
更重要的是,系统生成约64k token的综述仅需不到$0.50(折合3.6元)的成本,整个过程在10分钟内完成。

SurveyForge:面向高质量综述生成的创新框架
SurveyForge采用两阶段框架设计:大纲生成和内容生成,通过启发式学习方法和基于记忆的学者导航代理,确保生成结构合理的综述框架和高质量的内容。
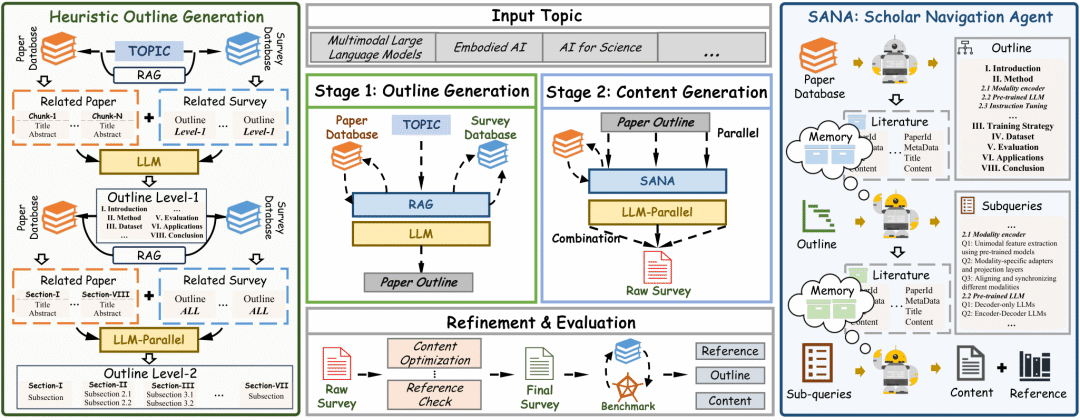
核心技术创新主要包括三个部分。
首先,双数据库协同驱动的启发式大纲生成机制。
传统LLM在生成综述大纲时常常陷入”报告式”结构,缺乏学术写作的层次感和逻辑性,根本原因在于现有方法缺乏结构化指导和领域知识支撑。SurveyForge的架构创新在于构建了研究论文数据库(约60万篇arXiv计算机科学领域论文)和综述大纲数据库(约2万篇综述文章的层次化大纲结构)的协同机制,前者提供领域知识的广度和深度,后者提供专家级的结构化模式。
基于这一双数据库架构,系统突破性地引入了人类专家的结构化思维模式:首先通过跨数据库知识融合,同时检索主题相关论文和已有综述大纲,既获得内容广度又学习结构规范性;然后采用递归构建策略,先通过分析专家撰写的综述结构模式生成体现全局逻辑的一级大纲,再针对每个章节结合领域文献深入细化二级结构。这种由粗到细、由整体到局部的方法让AI从单纯的文本生成转变为模仿专家思维的结构化学习,实现了知识内容与结构模式的有机结合,确保了大纲既有宏观的逻辑框架,又有微观的细节完整性。
其次,学者导航代理SANA。
现有检索方法的核心问题在于”遗忘性”——每次检索都是独立的,缺乏上下文连续性,同时将各章节视为孤立单元,未能考虑全局结构和主题连贯性。SANA的设计逻辑是让AI具备类似人类学者的”研究记忆”,通过三个创新模块实现智能化的文献检索与筛选。
子查询记忆模块解决了传统查询分解的核心缺陷。传统方法主要通过简单提示和LLM实现查询分解,不仅需要针对不同任务精心调优提示,更容易导致分解的子查询与原查询之间存在显著语义差异,从而降低参考文献的质量。SANA将大纲生成阶段检索的文献集合作为记忆上下文,结合包含每个子章节标题和描述的原查询,确保查询分解过程始终围绕主题核心,避免语义偏移的同时提高子查询的精准性。
检索记忆模块则从根本上改变了传统”全库检索”的低效模式。传统检索方法通常直接查询整个文献数据库,不仅效率低下且缺乏上下文焦点,更重要的是容易产生冗余或不相关的检索结果,限制生成内容的整体连贯性。检索记忆模块巧妙地将整个大纲相关的文献作为全局记忆,基于嵌入相似度为每个子查询检索最相关的文献,这种设计既提高了检索精度,又确保了各章节内容与整体框架的语义一致性,真正实现了从局部到全局的有机统一。
时间感知重排序引擎针对学术文献评估的复杂性提出了创新解决方案。现有重排序方法往往局限于表面的语义匹配,忽略了学术影响力和时间因素的重要作用。我们深刻认识到论文发表日期在确定其领域影响力方面的关键作用,以及分析不同时期论文对识别高质量贡献的重要性。系统将检索到的文献按发表时间分组(每组跨度2年),组内按引用数进行top-k筛选,这种策略不仅整合了文本相关性、引用影响力和发表新近性三个维度,更重要的是实现了经典权威文献与前沿新兴研究的平衡代表,确保综述既有深厚的理论基础,又紧跟学术前沿。
最后,并行生成与协调机制
长文档生成面临的根本挑战是如何在保证效率的同时维持内容的一致性。SurveyForge采用的并行生成策略,让每个章节可以独立生成内容,极大提升了生成速度。但更重要的是其协调机制:通过共享的记忆系统,确保各章节虽然并行生成,但都围绕统一的主题框架;最后的精炼阶段则如同人类编辑的统稿过程,消除重复、理顺逻辑,形成连贯的整体。
SurveyBench:多维度评估新标准
自动化综述生成领域面临的最大瓶颈之一是缺乏统一、客观的评估标准。
现有评估方法主要存在三个关键问题:一是过度依赖LLM自身的内部判断进行整体质量评估,缺乏外部客观基准;二是无法有效评估关键文献覆盖情况,特别是对领域核心文献的识别能力;三是缺乏对大纲结构、参考文献质量、内容质量等关键维度的细粒度分析。这些局限性使得不同方法间的比较缺乏说服力,也难以建立一致的质量基准。
SurveyBench的创新在于将”质量”这一抽象概念转化为可量化的指标体系。
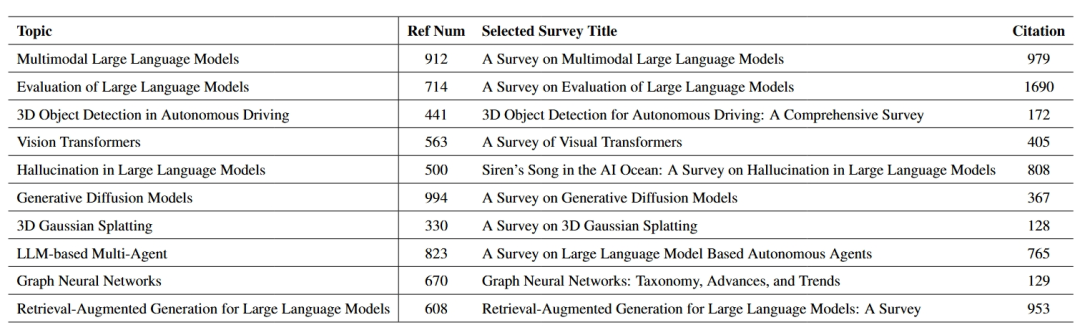
研究团队精心选择了10个计算机科学前沿主题,涵盖多模态学习、大语言模型、计算机视觉等领域,每个主题包含上百篇核心参考文献,从约100篇高质量专家撰写的综述中系统收集构建。
更重要的是,团队深入分析了顶级CS会议的同行评审标准,发现传统评审往往依赖评审者的隐性知识和经验,难以在自动化系统中实现。
为此,研究团队系统性地将这些高层次的评审指导原则分解为更具体、可测量的组件,最终形成了既保持专家评审本质又便于自动化实施的三维评估框架。
SAM评估指标系列
参考文献质量(SAM-R):这一指标的设计基于”核心文献决定综述价值”的学术共识。通过计算AI综述与专家策划基准的引用文献重叠度,不仅评估了文献选择的准确性,更体现了AI系统对领域核心知识的把握程度。
大纲质量(SAM-O):从主题独特性、结构平衡、层次清晰度、逻辑组织四个维度构建综合评估体系,分数范围0-100。这一指标的核心价值在于将”好的大纲”从主观的定性描述转化为客观的定量标准,通过详细的评估准则确保LLM评估的一致性和可靠性。
内容质量(SAM-C):采用结构质量、相关性、覆盖度的三维评估模式,以专家撰写的高质量综述作为参考标准。这一设计确保生成内容不仅在形式上符合学术写作规范,更在实质内容上达到专家级水平,实现了形式与内容的双重保障。
实验结果与核心发现
研究团队在10个不同主题上对SurveyForge与AutoSurvey等现有方法进行了全面比较,结果显示:
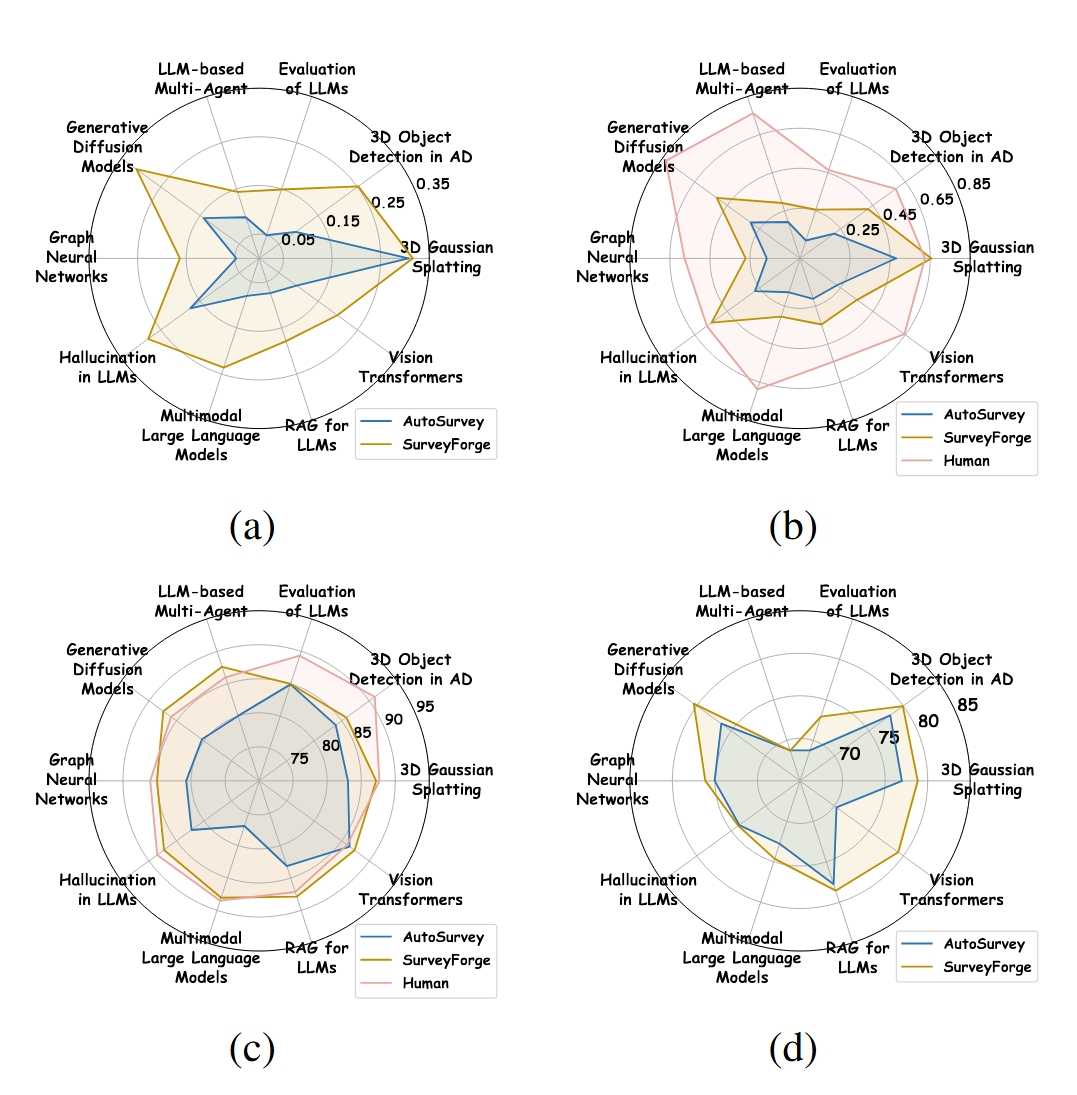
人机评估的高度一致性
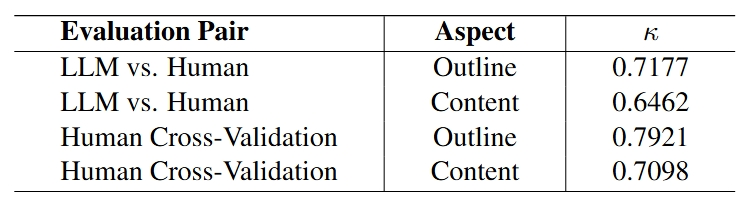
通过20位计算机科学博士专家的独立评估,验证了自动评估系统的可靠性。自动评估与人工评估的一致性达到70%以上,Cohen’s kappa系数显示强一致性,这表明SurveyBench不仅是一个评估工具,更是一个可信的质量标准。

技术组件的有效性验证
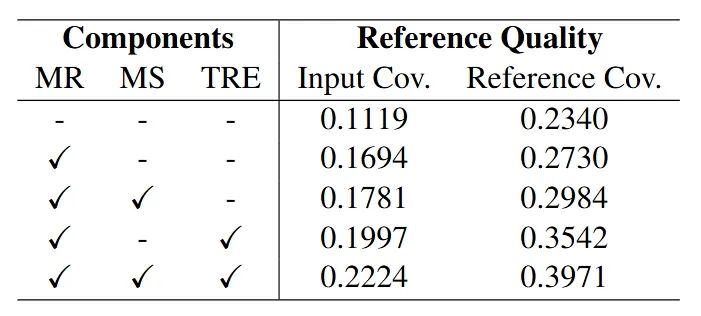
系统性的消融实验证明了每个技术组件的必要性:启发式学习使大纲质量显著提升,SANA的各个模块都对最终质量产生了积极贡献,时间感知重排序引擎显著提升了高质量文献的选择精度。

应用前景与影响
SurveyForge的价值不仅在于技术创新,更在于为学术研究生态带来的积极变化。对于初入某一领域的研究者,系统提供了快速获取领域全景的有效途径;对于跨学科研究,系统降低了知识整合的门槛;对于资深研究者,系统可以作为文献调研的得力助手,提升研究效率。
自动化综述生成系统不是要替代人类学者,而是要增强人类的研究能力,让研究者能够将更多精力投入到创新性思考和深度分析中,而将繁重的文献整理和初步综述工作交给AI来完成。
论文链接:https://arxiv.org/abs/2503.04629
Github仓库:https://github.com/Alpha-Innovator/SurveyForge
评估数据集:https://huggingface.co/datasets/U4R/SurveyBench
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)