
金磊 发自 凹非寺
量子位 | 公众号 QbitAI
没有一个大模型可以一统天下。
这,或许已经成为了AI大模型时代行业里的一个共识。
在如此背景之下,面对众多且日新月异的主流大模型和AI技术,如何能在一个框架、生态下去体验,却成了开发者们“老大难”的问题。
难道就没有一个又快又好又方便的解决办法吗?
有的——
华为开源的昇思MindSpore,了解一下。

在这里,主流SOTA大模型的“搬家”是这样的——训练Day0迁移:
只需改动极少极少的代码就OK,并且精度和性能都在线。
推理是一键部署的:
训练转推理全流程自动化,20多个主流大模型开箱即用,百亿参数模型加载只需不到30秒。
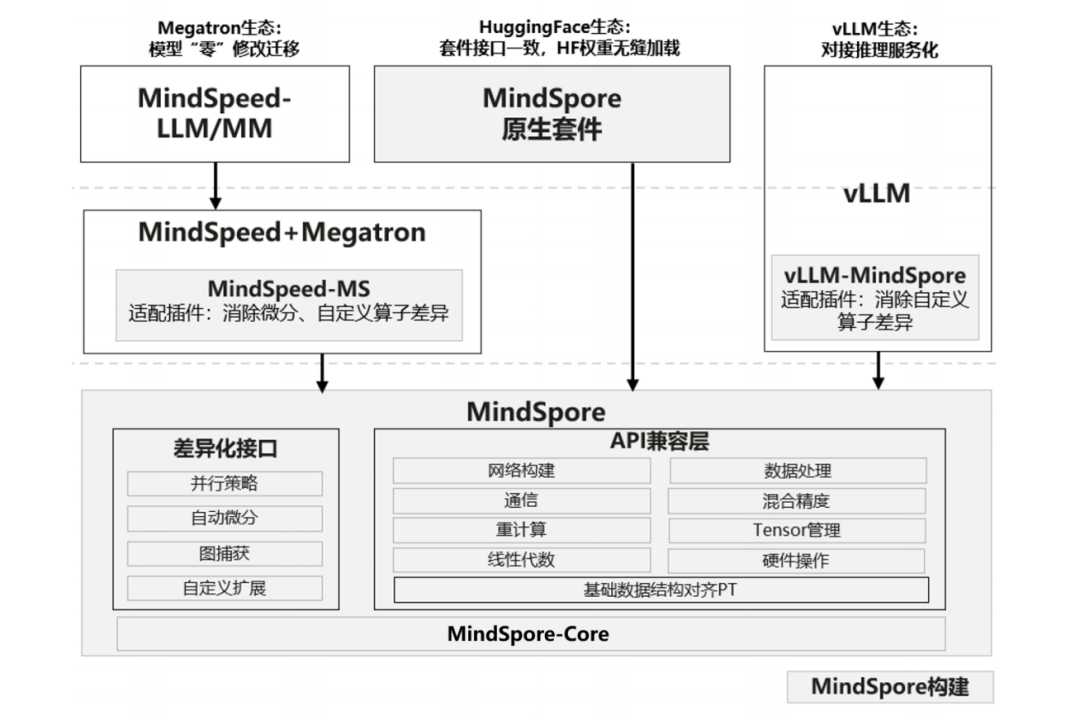
△MindSpore生态快速迁移解决方案的技术架构
那么昇思MindSpore是如何做到,我们继续往下看。
改4行代码,“搬家”DeepSeek-V3
为了让迁移大模型这件事变得无感知,昇思MindSpore“翻译神器”——MSAdapter。
简单来说,这个工具可以把其他框架的代码转换成MindSpore能看懂的语言,从而实现 “零损耗” 迁移。
比如PyTorch写的训练脚本,直接在MindSpore里运行,动态图体验和原来一样顺手,95%以上的接口都能自动转换,迁移损耗几乎为零。
在此背后还有其他的“独家秘笈”,加速训练调试调优,具体技术如下:
-
动态图多级流水:把算子(模型的基本计算单元)的处理拆成4个阶段(如Python 转换、形状推导等),用多核并行处理,速度提升3-4倍。 -
JIT 编译:把常用代码 “打包” 成高效执行的模块,像把重复工作做成模板,用的时候直接拿出来用,兼顾灵活编程和高性能。 -
自动策略寻优:大模型训练需要选最佳并行策略(比如数据并行、张量并行等),传统靠专家经验,现在MindSpore能自动搜索最优方案,比如在DeepSeek-V3训练中,性能提升了9.5%。 -
执行序比对:大模型训练可能因算子执行顺序不同导致精度问题,MindSpore能自动比对执行顺序,快速找到差异,避免人工排查几十万算子的麻烦。
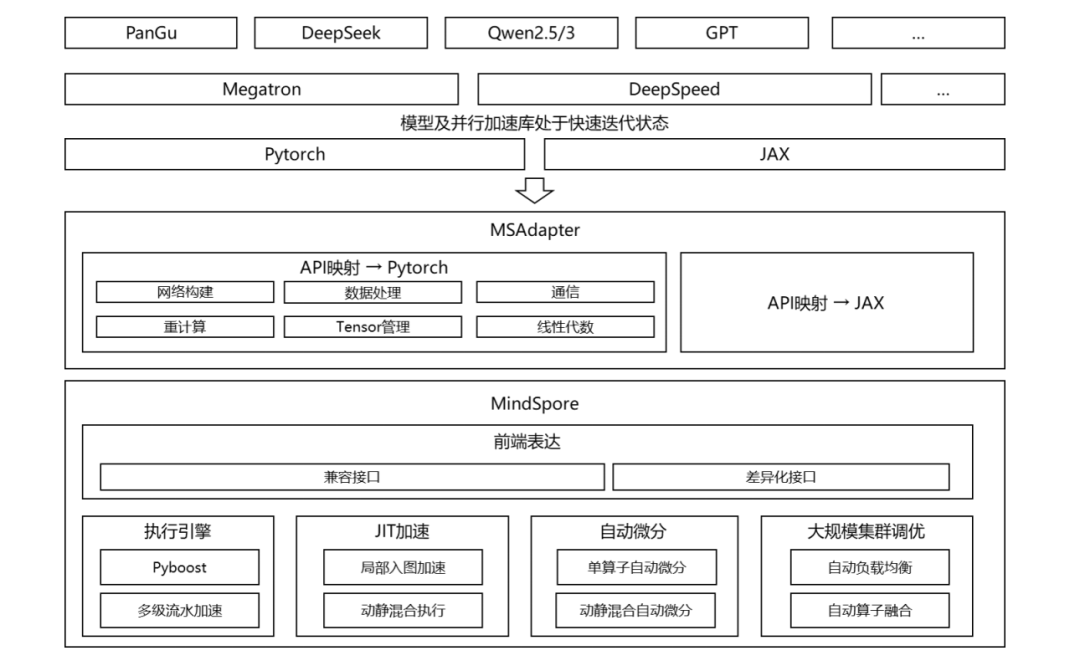
△MindSpore训练Day0迁移方案
以DeepSeek-V3为例,代码改动量如下:
-
Shell脚本:修改分布式任务启动相关参数,共涉及4行代码调整。 -
Python脚本:变更量占比<1%,已通过代码补丁工具自动完成修改。

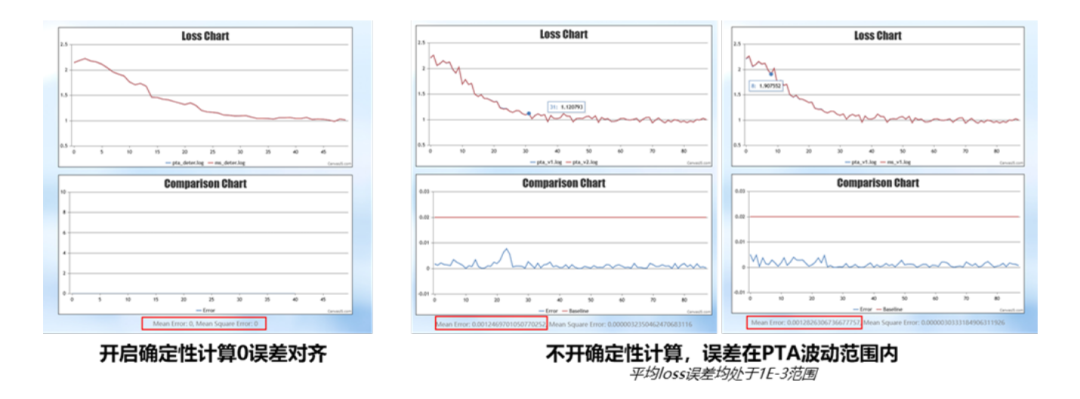
不仅精度上可以实现Day0对齐,而且在保持并行策略一致的情况下叠加MindSpore自研增量特性,性能还能提升5%。
HuggingFace模型们,推理一键部署
在推理部署这块儿,昇思则是用vLLM-MindSpore插件能让HuggingFace模型在半小时内完成部署并上线。
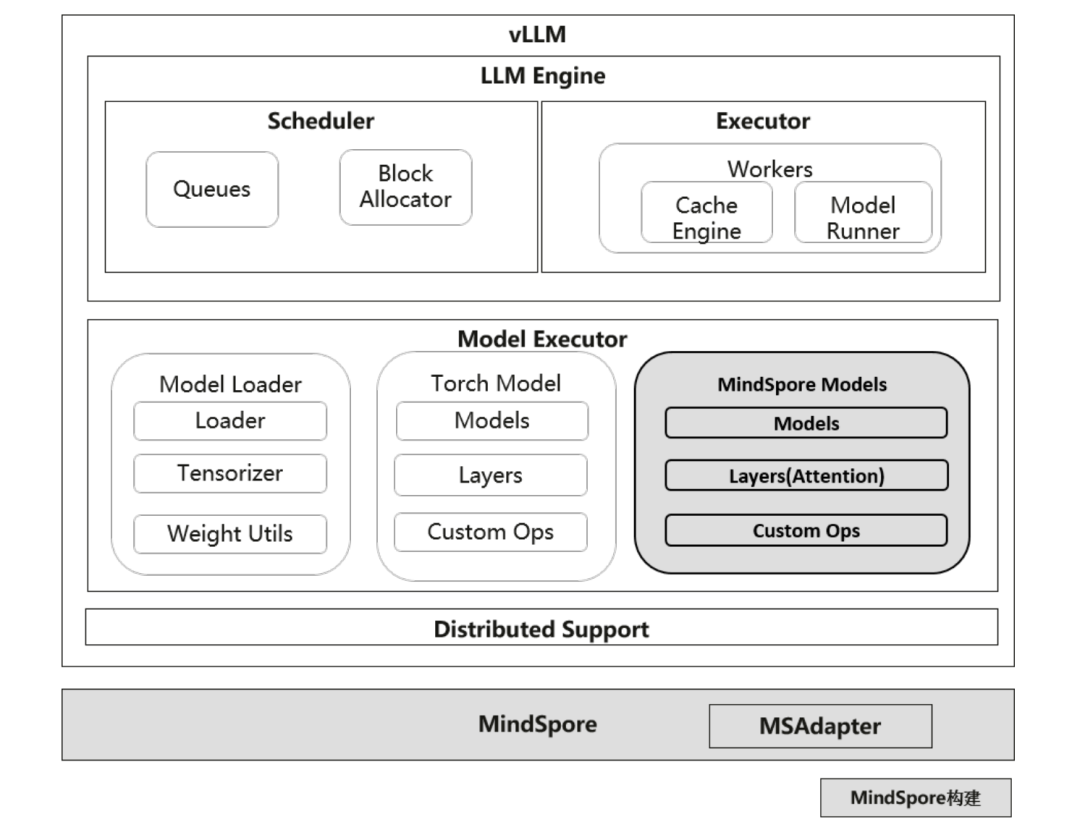
△vLLM x MindSpore 框架图
要是碰到千亿参数的大模型,MindSpore用三层部署模式重新打造了推理流程:
-
直接用HuggingFace的权重:能直接加载HuggingFace的模型权重,不用转换格式;通过vLLM – MindSpore插件,短短几分钟就能把模型变成可提供服务的状态。 -
模型拿来就能用:支持很多业内常用的模型,拿来就能直接用,像DeepSeek、Pangu、Qwen这些,已经有20多个模型上线了。 -
减少启动时的延迟:权重加载花费的时间减少了80%(百亿参数的模型加载时间不到30秒);图编译的延迟也压缩到了毫秒级别。
从实测效果来看,以Pangu Pro MoE 72B为例,使用vLLM和MindSpore在Atlas 800I A2上部署推理服务,当前在时延小于100ms的情况下单卡增量吞吐可达每秒1020tokens,在Atlas 300I Pro上可达每秒130tokens。
以上便是关于昇思MindSpore“训练Day0迁移、推理一键部署”的大致内容了,了解更多详情可戳 。
。
https://gitcode.com/ascend-tribe/ascend-cluster-infra/blob/main/MindSpore/ascend-cluster-infra-mindspore.md
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
🌟 点亮星标 🌟
(文:量子位)