

极市导读
为解决长上下文场景下GRPO训练中的计算冗余难题,本文提出了Prefix Grouper算法,通过“共享前缀前向计算”,实现了在保留策略优化效果的同时显著降低FLOPs和内存开销。技术报告与代码已开源,可即插即用。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

技术报告、代码均已开源。
技术报告:https://arxiv.org/abs/2506.05433
代码:https://github.com/johncaged/PrefixGrouper
背景:GRPO训练的效率瓶颈
Group Relative Policy Optimization(GRPO)是一种强大的强化学习优化算法,其核心思想是:针对同一个输入前缀(Prompt/上下文)生成多个候选响应(Rollout),然后通过比较这些响应的相对优劣(如Reward或人工偏好)来计算策略梯度,进而更新模型。这种方法避免了显式值函数估计,已被广泛应用于指令遵循、思维链推理、多模态任务等场景。
然而,标准GRPO训练存在一个显著的效率瓶颈:在模型的前向计算(Forward Pass)中,每个候选响应都需要独立且完整地编码整个共享的输入前缀。当输入前缀较长(例如包含复杂指令、多模态信息或长文档上下文),并且组大小(Group Size ,即候选响应数量)较大时,这种对相同前缀的冗余计算会消耗海量的计算资源(FLOPs)和GPU内存,成为GRPO方法在长上下文任务中扩展(如使用更大或更长前缀)的主要障碍。
Prefix Grouper——高效GRPO训练算法
为解决这一核心痛点,团队创新性地提出了Prefix Grouper算法。该算法基于“共享前缀前向计算”(Shared-Prefix Forward)的核心策略,实现了GRPO训练效率的飞跃。
特点:共享前缀,一次编码。
-
传统方法(Repeated-Prefix Forward) :将每个候选响应与共享前缀拼接成独立序列输入模型,导致前缀被重复编码次。 -
Prefix Grouper(Shared-Prefix Forward):将共享前缀仅输入一次,然后将所有候选响应顺序拼接在其后,形成单个长序列输入模型。
算法的关键在于如何处理这种拼接序列中的自注意力计算。Prefix Grouper将自注意力计算巧妙地拆分为两部分:
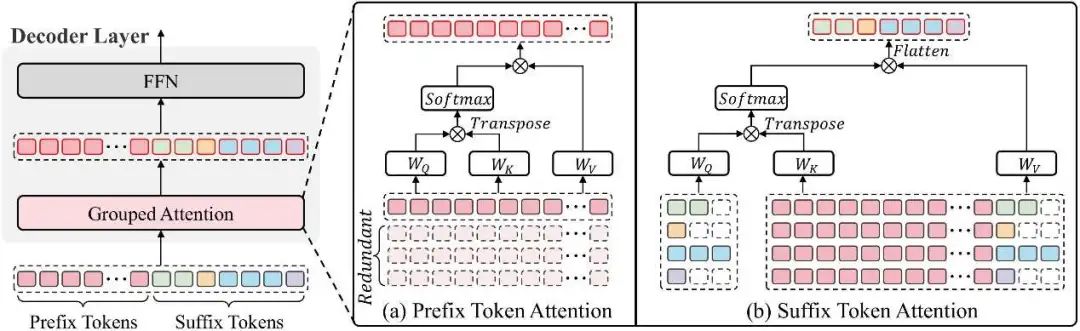
-
前缀自注意力(Prefix Self-Attn) :仅在前缀的tokens之间计算自注意力,更新其表示。 -
后缀拼接注意力(Suffix Concat-Attn):每个响应后缀中的tokens,其Query向量仅来自,但其Key和Value向量则来自。
这种分组注意力(Grouped Attention) 机制,确保了注意力计算的等价性和高效性。
训练等效性(Training Equivalence)
团队证明了Prefix Grouper在前向输出(Forward Outputs)和反向梯度(Backward Gradients)上等效于标准的Repeated-Prefix Forward GRPO训练,这意味着采用Prefix Grouper不会改变GRPO的优化过程和最终学到的策略性能。其带来的效率提升是“免费”的,没有性能妥协的代价。
显著效率提升
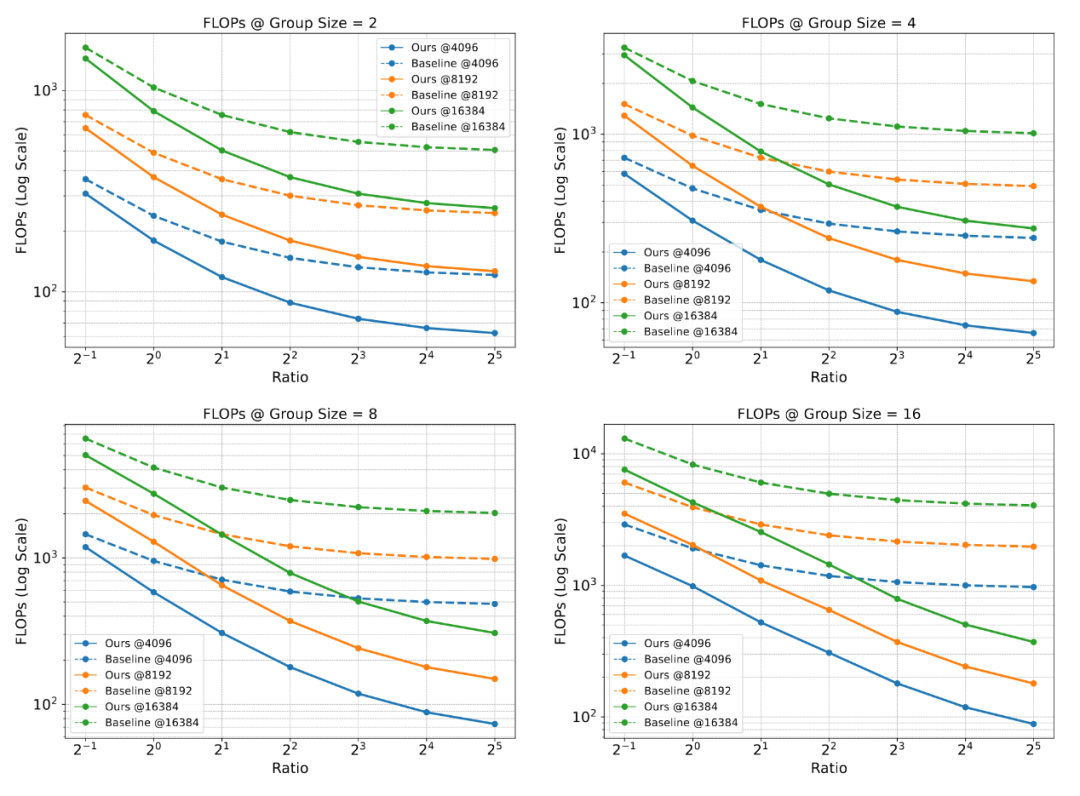
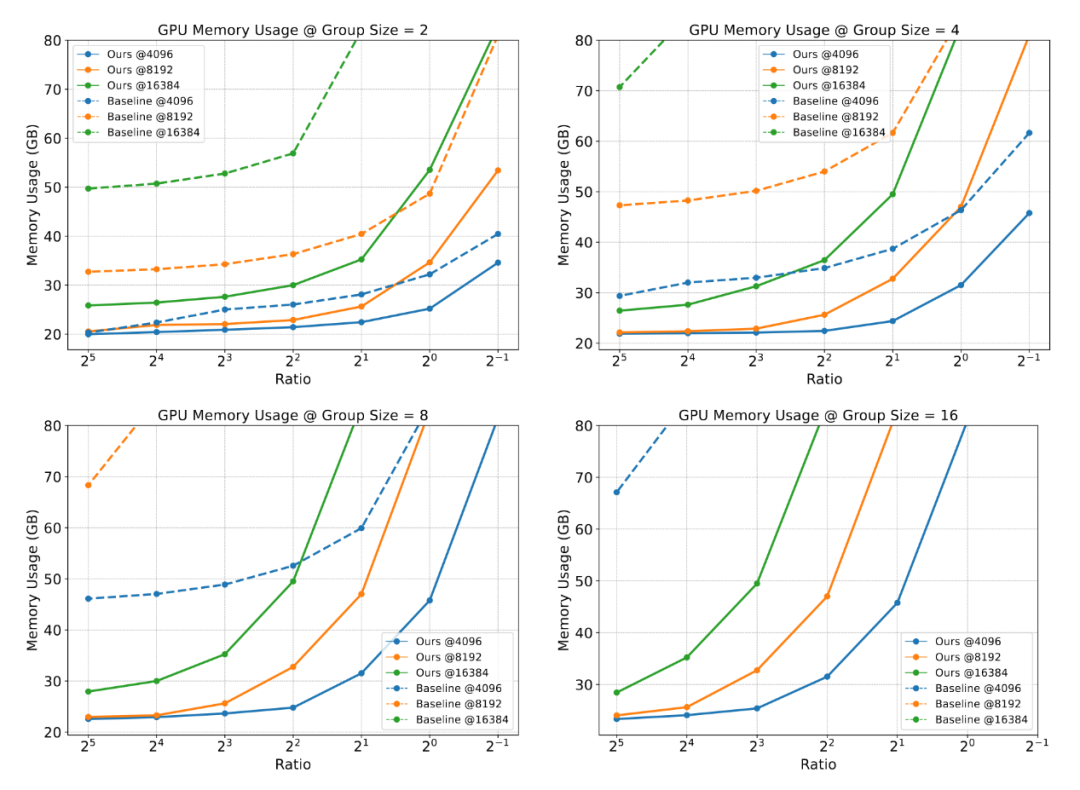
-
计算量(FLOPs)锐减:理论分析与实验验证均表明,在共享前缀长度远大于单个响应长度的长上下文典型场景下,Prefix Grouper能将自注意力部分的计算量降低到传统方法的。点式操作(MLP,投影层)的计算量也大幅降低。 -
内存占用大幅降低:由于避免了冗余前缀状态的存储,GPU内存消耗显著下降,尤其在较大时优势更明显。
即插即用(Plug-and-Play)
Prefix Grouper是一个实现层面的优化。它兼容现有的基于Transformer和GRPO的训练框架,只需调整输入数据的组织方式和修改注意力计算的实现(通常是少量代码改动),即可无缝集成到现有训练流程中。另外,该方法设备友好,支持各种训练设备(GPU、NPU等)和Attention算法。
(文:极市干货)