
明敏 克雷西 发自 凹非寺
量子位 | 公众号
CVPR 2025奖项出炉!谢赛宁苏昊齐获青年学者奖。
该奖项面向获得博士学位不超过7年的早期研究工作者,表彰他们在计算机视觉领域的杰出研究贡献。

其中,苏昊是李飞飞的博士生,他参与了对计算机视觉领域鼎鼎有名的ImageNet。
谢赛宁以一作身份和何恺明合作完成ResNeXt,同时也参与了MAE,都是计算机视觉领域影响深远的工作。
最值得关注的CVPR 2025最佳论文奖也新鲜出炉!
今年只有一篇论文获奖:《VGGT: Visual Geometry Grounded Transformer》,由Meta和牛津大学联合提出,第一作者为牛津大学Meta联培博士王建元。
VGGT是首个能在单次前馈中端到端预测完整3D场景信息的大型Transformer,性能超越多项现有几何或深度学习方法,具有广泛的应用潜力。

Best Student Paper颁给《Neural Inverse Rendering from Propagating Light》,由多伦多大学、卡内基梅隆大学等联合带来。
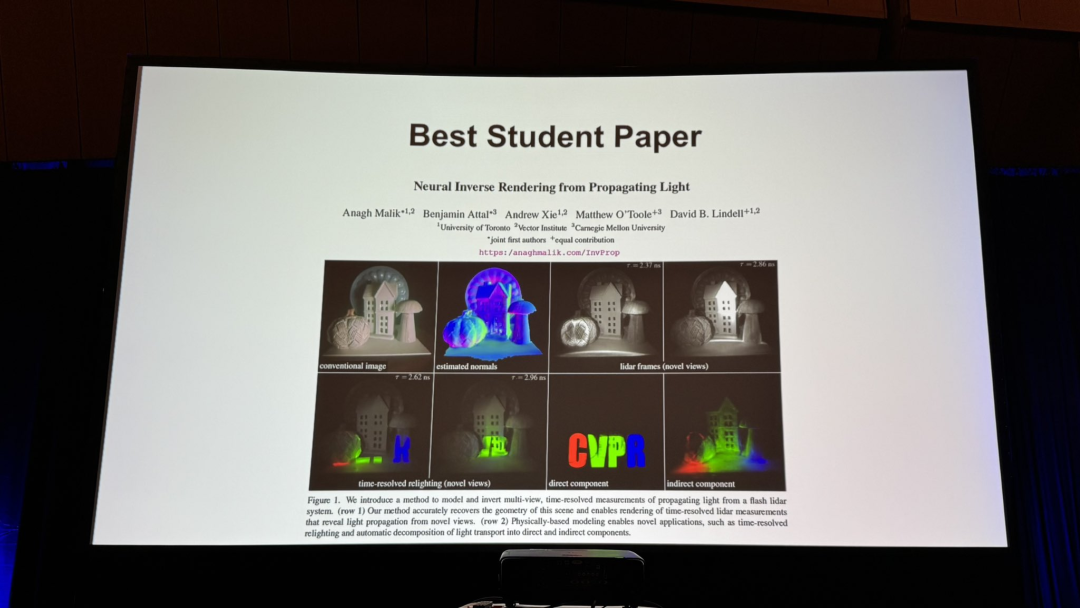
它首次提出针对从多视角、时间分辨的光传播视频进行物理基础的神经逆向渲染(Neural Inverse Rendering)。
Best Paper Honorable Mention一共有4篇,分别是:
-
MegaSaM: Accurate, Fast, and Robust Structure and Motion from Casual Dynamic Videos -
Navigation World Models -
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models -
3D Student Splatting and Scooping
最佳论文
VGGT: Visual Geometry Grounded Transformer
论文链接:https://arxiv.org/abs/2503.11651

传统的三维视觉(如Structure-from-Motion、Multi-view Stereo)方法严重依赖几何优化(如Bundle Adjustment),不仅计算复杂、时间消耗大,还难以端到端训练。
本研究提出的问题是:能否使用简单的前馈神经网络(无后处理)同时预测所有核心3D属性(相机参数、深度图、点云图、3D轨迹),并优于传统几何优化方案?
VGGT基于Vision Transformer,采用交替“全局-帧内”自注意力(Alternating Attention)机制。
它不含几何归纳偏置,仅靠大量3D标注数据自学习。
实现输入:1张到200张图像;输出:每张图的相机内外参、深度图、点图、特征图(用于点追踪)。
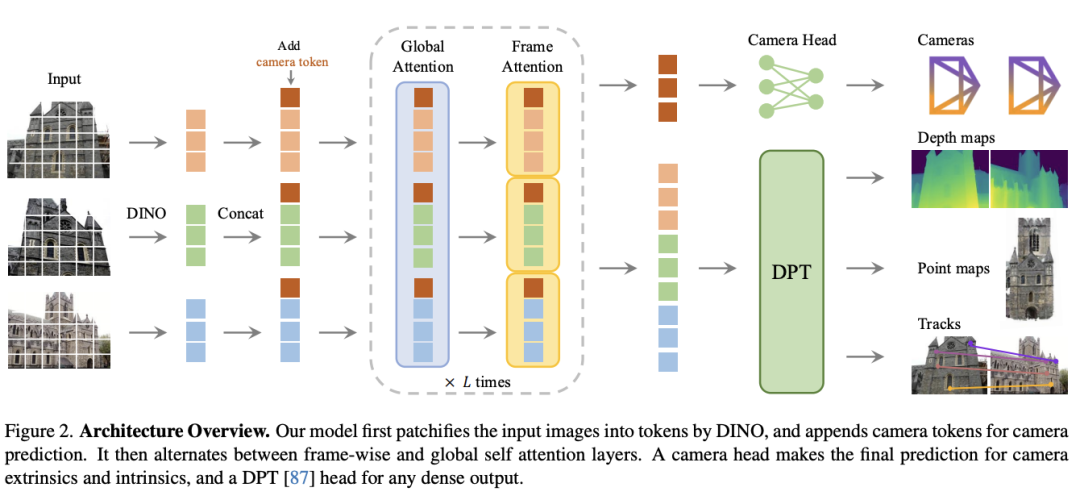
输入图像被分块为patch tokens,每帧加入一个“相机token”和多个“寄存token”来分别学习相机参与与全局场景特性。
Alternating Attention中,Frame-wise Self-Attention处理每一帧图像内的patch tokens(保持局部一致性);Global Self-Attention实现不同帧间的tokens交互(整合多视角信息),两种注意力机制在24层Transformer中交替堆叠。
这种设计可以在保留单帧细节同时,整合多帧场景信息,同时相比直接使用Global attention更省内存(最高40GB)。

本文一作为王建元,他是牛津大学和Meta AI研究和VGG联合博士生。

最佳学生论文
Neural Inverse Rendering from Propagating Light
论文链接:http://www.arxiv.org/abs/2506.05347
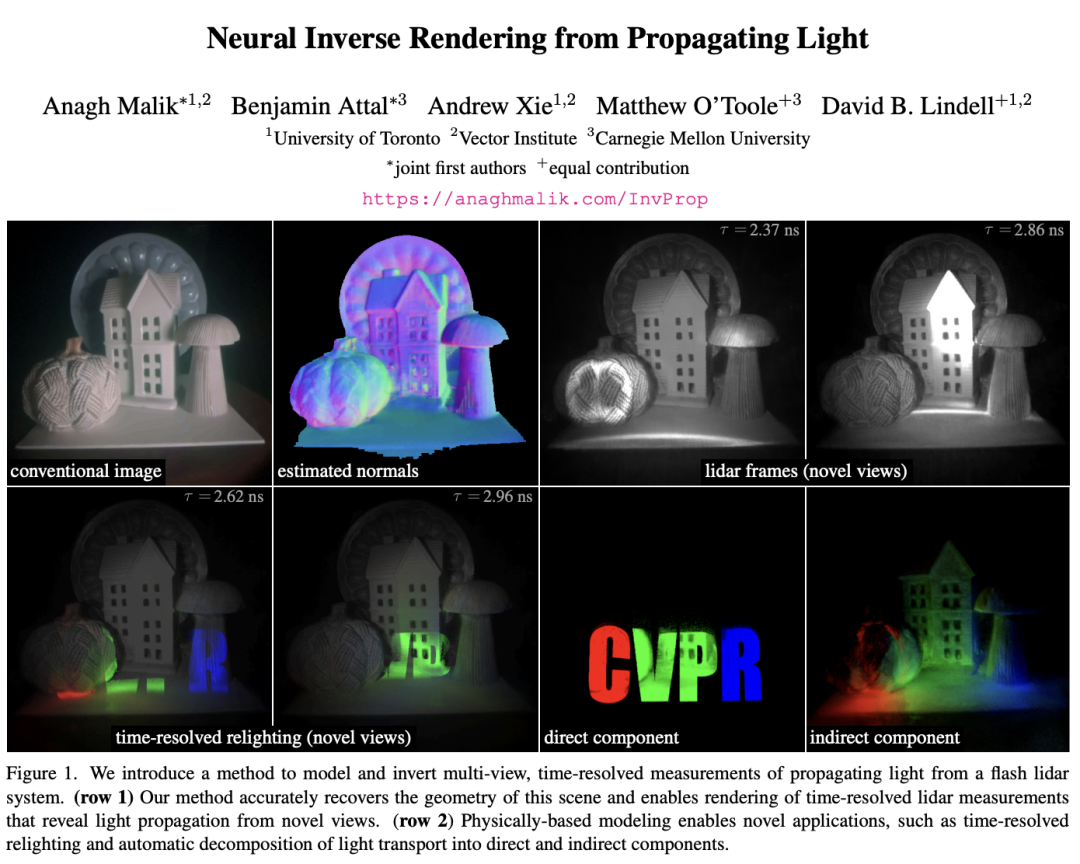
这篇论文的核心内容是提出了一种基于物理模型的神经逆向渲染方法,用于从多视点、时间分辨的激光雷达(LiDAR)测量数据中重建场景几何和材质,并生成新的光传播视频。
简单来说,它实现了让激光雷达不仅看见直接光,还能看懂间接光,并利用这些信息来重建场景。
核心思路有两步:
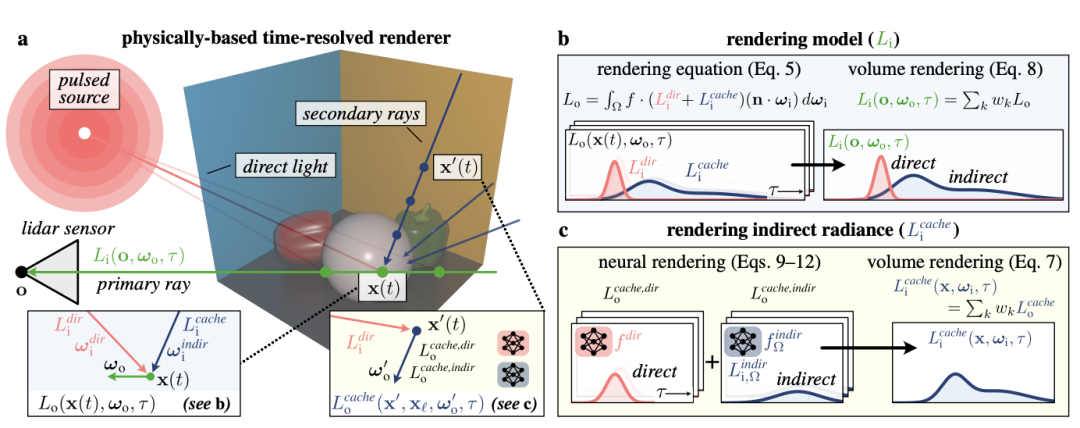
第一,提出时间分辨辐射缓存(time-resolved radiance cache),记录某一时刻某个位置的光线是从哪来的、经过了哪些反射。这个缓存可以理解为一个“光的地图”,能告诉我们光是怎么传播的。
第二,用神经网络加速计算。“提前学会”光的传播规律。这样一来,只需要简单查询这个“光的记忆库”,就能快速计算出场景中每一点的光线分布。
这种技术在自动驾驶、3D建模和虚拟现实等领域有广泛应用前景。
Best Paper Honorable Mention
MegaSaM: Accurate, Fast, and Robust Structure and Motion from Casual Dynamic Videos
论文链接:https://arxiv.org/abs/2412.04463

本文提出了一种系统,能够从动态场景的普通单目视频中准确、快速且鲁棒地估计相机参数和深度图。传统的结构光束法(SfM)和单目SLAM方法通常依赖于具有大量视差且主要为静态场景的视频输入,在不满足这些条件时,容易产生错误估计。
本项研究开发了一个改进的深度视觉SLAM系统,通过对训练方式和推理过程的优化,使得这个系统可以:
-
适应真实世界中复杂的动态场景。 -
处理相机运动轨迹不规则的视频(甚至是相机运动很少的情况)。

大量在合成和真实视频上的实验表明,该系统在相机姿态和深度估计方面的准确性和鲁棒性明显优于现有和同期工作,同时运行速度更快或相当。
Navigation World Models
论文链接:https://arxiv.org/abs/2412.03572

这篇研究来自LeCun团队。
本文提出了一种导航世界模型(Navigation World Model,简称NWM),这是一种可控的视频生成模型,能够基于过去的视觉观测和导航动作预测未来的视觉观测。
NWM 采用了一种叫“条件扩散变换器”的技术,可以根据导航动作和过去的视觉信息,生成下一步可能的视觉画面。
这个模型是用大量“第一视角”(egocentric)视频训练的,包括人类和机器人在各种环境中的导航视频,总参数规模达到10亿。

在熟悉的环境中,NWM可以“在脑内模拟”不同的路径,并判断哪条路径能达到目标。
不像固定规则的导航方法,NWM可以在规划路径时灵活加入新的约束(比如避开障碍物)。
即使是在陌生的环境中,NWM也能从一张图片(比如初始场景)出发,想象出可能的导航路径,表现出很强的适应性。
实验结果显示,NWM可以在没有现成导航策略的情况下,直接规划出合理的路径。对于其他导航系统生成的路径,NWM可以对其进行排名,找到最优解。
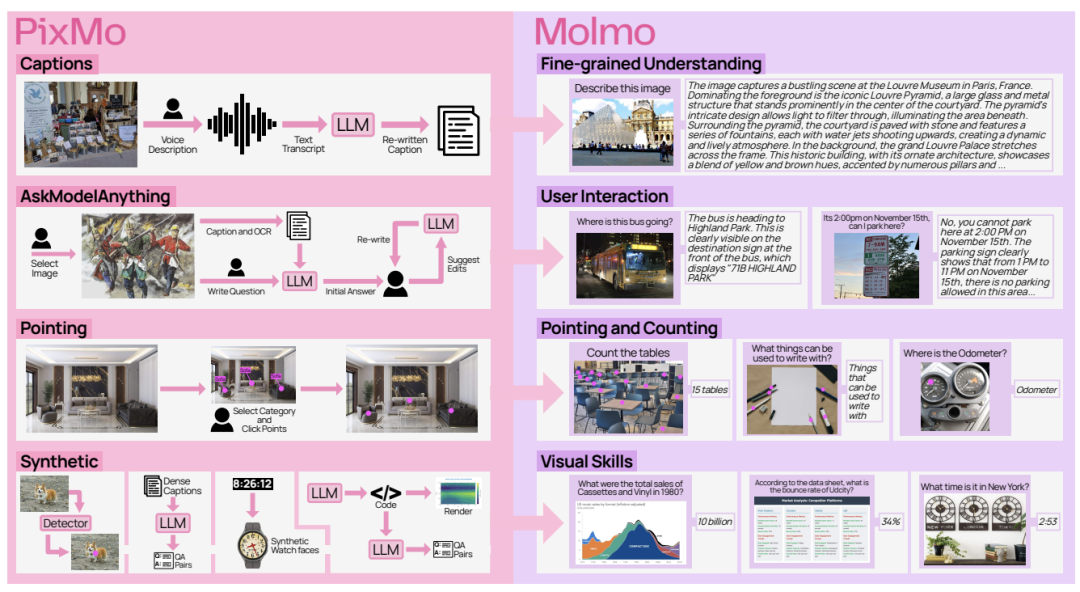
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models
论文链接:https://arxiv.org/abs/2409.17146

本项研究提出了一个新的视觉-语言模型家族Molmo,是当时最强开源模型之一。它有72亿参数规模,不仅拿下开源SOTA,还超越了Claude 3.5 Sonnet、Gemini 1.5 Pro等(注:该论文第一版发表时间为2024年9月)。
作者认为,现有性能最强的开源权重模型在很大程度上依赖于由闭源VLM生成的合成数据来获得良好表现,实质上是将这些闭源模型“蒸馏”成开源模型。
因此,作者认为学术界一直缺乏关于如何从零开始构建高性能VLM的基础知识,Molmo就是基于这一背景提出。
Molmo模型架构采用标准的视觉编码器(ViT)+语言模型设计,模型设计与优化方面,Molmo提出了若干新策略。
例如重叠多裁剪(overlapping multi-crop)图像处理策略、改进了视觉-语言连接模块、设计了支持指点能力的训练流程,这些创新提高了模型对复杂视觉任务(如定位、计数、自然图像理解)的能力。
他们还创建了一组全新数据集PixMo,完全没有依赖外部闭源模型生成。
其中包括用于预训练的高细节图像描述数据集、用于微调的自由问答图像数据集,以及一个创新的二维指点(pointing)数据集。
此外,PixMo还包含数个辅助的合成数据集,增强模型在读表、读图、读钟表等特定技能上的能力。
3D Student Splatting and Scooping
论文链接:https://arxiv.org/abs/2503.10148

这项研究提出了一个新的3D模型——Student Splatting and Scooping,简称SSS,其作者全部为华人,且均来自英国高校。
随着3DGS(3D高斯泼溅)逐渐成为众多模型的基础组件,任何对3DGS本身的改进都可能带来巨大的收益,为此,作者致力于改进3DGS的基本范式和公式结构。
但3DGS本质上是一个未归一化的混合模型,因此不必局限于高斯分布,也不一定要采用泼溅方式。
因此,作者提出了一种由灵活的Student’s t分布(distribution)组成的新型混合模型,它具有正密度(泼溅Splatting)和负密度(挖空Scooping)两种形式,这就是其名称的由来。
与传统高斯相比,Student’s t 分布通过可学习的尾部厚度参数实现了对从Cauchy到Gaussian的广泛分布建模能力,使得 SSS 在表达能力上更为强大。
但在提供更强表达能力的同时,SSS也带来了新的学习挑战,主要是参数耦合问题和负密度引入的优化复杂性。
为此,作者还提出了一种新的、具有理论依据的采样优化方法——SGHMC。
SGHMC通过在优化过程中引入动量变量(momentum)和受控噪声项,使得参数在优化过程中能跳出局部最优,同时能有效缓解参数之间的耦合问题。
通过在多个数据集、设置和评测指标上的全面评估与对比,作者证明了 SSS 在质量和参数效率方面优于现有方法。
在使用相似数量组件的情况下,SSS 可实现相当甚至更高的渲染质量,同时在某些场景下可将组件数量最多减少 82%,仍保持可比的结果。
最后,再次祝贺所有获奖团队与学者!
— 完 —
📪 量子位AI主题策划正在征集中!欢迎参与专题365行AI落地方案,一千零一个AI应用,或与我们分享你在寻找的AI产品,或发现的AI新动向。
💬 也欢迎你加入量子位每日AI交流群,一起来畅聊AI吧~

一键关注 👇 点亮星标
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
(文:量子位)