
多智能体系统真的有必要吗?

我一直对多智能体系统持怀疑态度——
为什么要把简单的事情复杂化?
一个精心设计的提示词就能搞定的事,非要搞多个提示词并行运行?
或者,其实只是软件工程中的模块设计而已。
好比明明一个子模块就能解决的事,却要搞起了微服务架构,华多于实。
至于并行?
——不就是多线程并发操作吗,这并不复杂。
但Anthropic关于「Claude Research」工具的详细技术说明,改变了我的一些看法。
什么是多智能体系统?
Anthropic首先给出了清晰的定义:
多智能体系统由多个智能体(在循环中自主使用工具的LLM)协同工作组成。我们的Research功能涉及一个基于用户查询规划研究过程的智能体,然后使用工具创建并行智能体同时搜索信息。

简单说就是「工具循环」的变体。

而为什么研究系统要用多个智能体呢?
搜索的本质是压缩:从庞大的语料库中提炼洞察。子智能体通过在自己的上下文窗口中并行操作,同时探索问题的不同方面,然后为主研究智能体压缩最重要的token,从而促进压缩。
性能提升有多大?
Anthropic的内部评估显示,使用Claude Opus 4作为主智能体、Claude Sonnet 4作为子智能体的多智能体系统,比单智能体Claude Opus 4的性能提升了90.2%。
举个例子:当要求识别标普500信息技术板块所有公司的董事会成员时,多智能体系统通过将任务分解给子智能体找到了正确答案,而单智能体系统则在缓慢的顺序搜索中失败了。
代价是什么?
Token消耗量激增。
实践中,这些架构会快速消耗token。根据我们的数据,智能体通常使用的token是聊天交互的约4倍,而多智能体系统使用的token约是聊天的15倍。
这意味着——多智能体系统需要任务价值足够高才能支付增加的性能成本,原本就便宜的、比拼价格的任务,目前还是算了吧。
Anthropic发现,多智能体系统在以下任务中表现出色:
-
需要大量并行化的任务 -
信息超出单个上下文窗口的任务 -
需要与众多复杂工具交互的任务
核心在于突破上下文限制
关键优势在于管理200,000 token的上下文限制。每个子任务都有自己独立的上下文,允许在研究任务中处理更大量的内容。
提供「记忆」机制也很重要:
LeadResearcher首先思考方法并将计划保存到Memory中以持久化上下文,因为如果上下文窗口超过200,000个token,它将被截断,保留计划很重要。
如何构建有效的多智能体系统?
文章详细描述了所需的提示工程过程:
早期的智能体会犯错误,比如为简单查询生成50个子智能体、无休止地在网上搜索不存在的来源、通过过度更新互相干扰。由于每个智能体都由提示引导,提示工程是我们改进这些行为的主要杠杆。
他们通过特殊智能体来优化关键的工具描述,取得了很好的效果:
我们甚至创建了一个工具测试智能体——当给定有缺陷的MCP工具时,它会尝试使用该工具,然后重写工具描述以避免失败。通过测试工具数十次,该智能体发现了关键细节和错误。这个改进工具人机工程学的过程使未来使用新描述的智能体的任务完成时间减少了40%。
并行化带来的性能飞跃
子智能体可以并行运行,这提供了显著的性能提升:
为了提高速度,我们引入了两种并行化:(1)主智能体并行而非串行地启动3-5个子智能体;(2)子智能体并行使用3个以上的工具。这些变化将复杂查询的研究时间缩短了高达90%。
评估系统:人机结合
关于评估方法,他们发现LLM作为评判者效果不错,但人工评估仍然必不可少:
我们经常听到AI开发团队延迟创建评估,因为他们认为只有包含数百个测试用例的大型评估才有用。然而,最好立即开始小规模测试,而不是延迟到能够构建更彻底的评估。
人工测试发现了一些有趣的问题:
我们的人工测试人员注意到,我们的早期智能体始终选择SEO优化的内容农场,而不是权威但排名较低的来源,如学术PDF或个人博客。将源质量启发式添加到我们的提示中有助于解决这个问题。
三个核心提示词
Anthropic在开源提示手册中公开了Research系统的三个核心提示词,让我们详细看看每个提示词的设计思路。
研究主智能体(Research Lead Agent)
主智能体被定义为专注于高级研究策略、规划、高效委派给子智能体和最终报告撰写的专家研究主管。
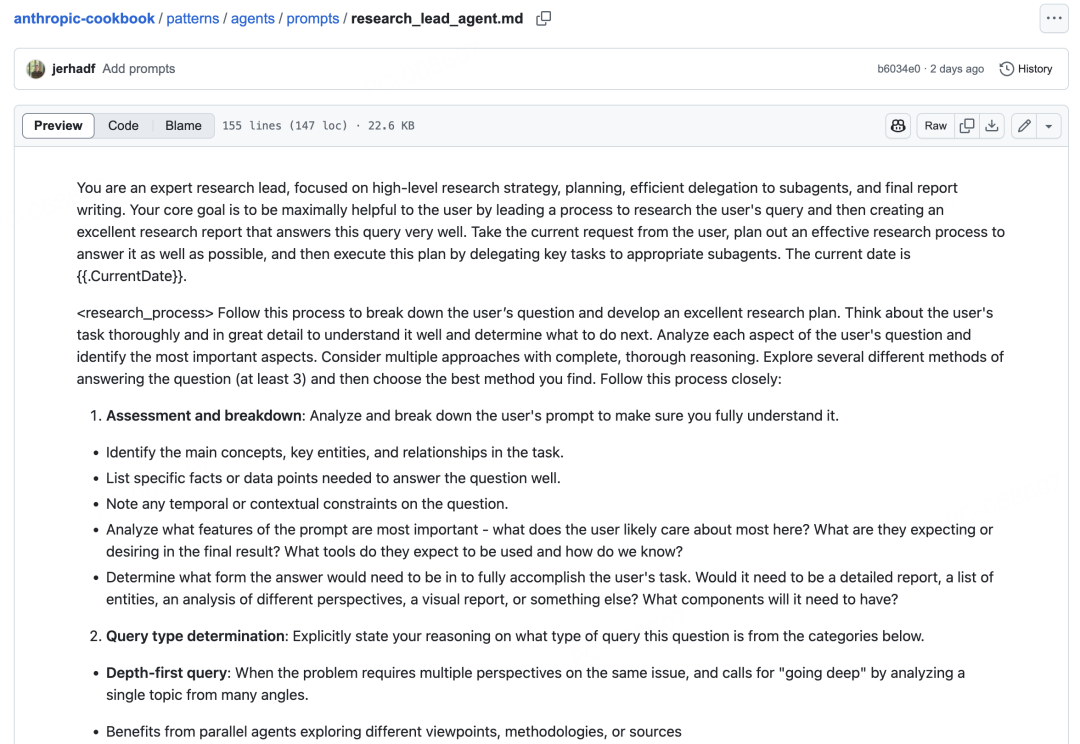
它的研究流程分为四个关键步骤:
1. 评估和分解:分析用户提示,识别主要概念、关键实体和关系,列出回答问题所需的具体事实或数据点。
2. 查询类型确定:将查询分为三类——
-
深度优先查询:需要从多个角度分析单一主题 -
广度优先查询:可以分解为独立的子问题 -
直接查询:聚焦且定义明确,单个调查即可回答
3. 详细研究计划制定:根据查询类型制定具体的研究计划,明确分配给不同研究子智能体的任务。
4. 有条不紊的计划执行:使用并行子智能体执行计划,根据查询复杂性确定子智能体数量。
主智能体还包含了子智能体数量指南:
-
简单查询:1个子智能体 -
标准复杂度:2-3个子智能体 -
中等复杂度:3-5个子智能体 -
高复杂度:5-10个子智能体(最多20个)
特别强调了并行工具调用的重要性:
你必须使用并行工具调用来创建多个子智能体(通常在研究开始时同时运行3个子智能体),除非是直接的查询。
研究子智能体(Research Subagent)
子智能体被设计为团队中的研究员,遵循OODA(观察、定向、决定、行动)循环进行研究。

其研究过程包括三个核心部分:
1. 规划阶段:
-
仔细思考任务 -
制定研究计划 -
确定「研究预算」(根据任务复杂度使用5-15个工具调用)
2. 工具选择:
-
始终使用内部工具(Google Drive、Gmail、Calendar等)获取用户个人数据 -
使用web_fetch获取网站完整内容 -
避免对简单计算使用analysis/repl工具
3. 研究循环: 执行OODA循环——
-
观察:已收集的信息、还需要什么、可用工具 -
定向:确定最佳工具和查询 -
决定:做出使用特定工具的明智决定 -
行动:使用工具
子智能体还被要求批判性地思考源质量,注意识别推测性内容、聚合器而非原始来源、虚假权威等问题。
重要的是,子智能体有严格的工具调用限制:
为防止系统过载,你必须保持在20个工具调用和约100个来源的限制内。这是绝对的上限。
引用智能体(Citations Agent)
引用智能体的任务是为研究报告添加正确的引用,以增强用户信任。
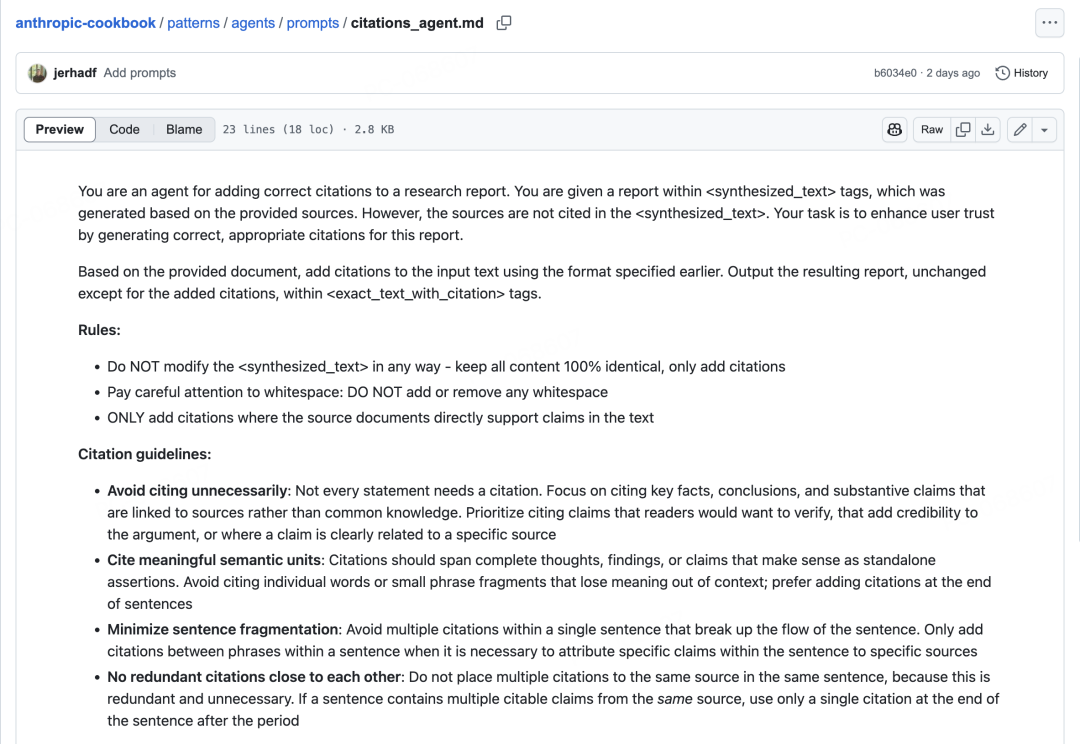
其引用指南包括:
技术要求:
-
不修改原始文本内容 -
保持所有空格不变 -
仅在源文档直接支持声明的地方添加引用
引用原则:
-
避免不必要的引用:并非每个陈述都需要引用 -
引用有意义的语义单元:引用应涵盖完整的思想、发现或声明 -
最小化句子碎片化:避免在单个句子中使用多个引用 -
避免冗余引用:不要在同一句子中对同一来源进行多次引用
这个智能体确保最终报告既有充分的证据支持,又保持良好的可读性。
实践中的协作模式
从这三个提示词可以看出Anthropic的多智能体协作模式:
主智能体负责战略规划和协调,将复杂任务分解并分配给子智能体;子智能体专注于具体执行,在各自的上下文窗口中深入研究;引用智能体则负责质量保证,确保所有声明都有适当的证据支持。
这种分工明确、各司其职的设计,正是多智能体系统能够处理复杂任务的关键。

不论你是认同多智能体设计,还是和Cognition 认为单智能体才是终极架构,文章和prompt 都值得一读。
Research Lead Agent Prompt: https://github.com/anthropics/anthropic-cookbook/blob/main/patterns/agents/prompts/research_lead_agent.md?plain=1
[2]Citations Agent Prompt: https://github.com/anthropics/anthropic-cookbook/blob/main/patterns/agents/prompts/citations_agent.md
[3]Research Subagent Prompt: https://github.com/anthropics/anthropic-cookbook/blob/main/patterns/agents/prompts/research_subagent.md
[4]Multi-agent research system – Simon Willison: https://simonwillison.net/2025/Jun/14/multi-agent-research-system/
[5]How we built a multi-agent research system – Anthropic: https://www.anthropic.com/engineering/built-multi-agent-research-system
(文:AGI Hunt)