

机器之心编辑部
上上周的 2025 高考已经落下了帷幕!在人工智能领域,各家大模型向数学卷发起了挑战。
在机器之心的测试中,七个大模型在「2025 年数学新课标 I 卷」中的成绩是这样的:Gemini 2.5 Pro 考了 145 分,位列第一;Doubao 和 DeepSeek R1 以 144 分紧随其后,并列第二;o3 和 Qwen3 也仅有一分之差,分别排在第三和第四。受解答题的「拖累」,hunyuan-t1-latest 和文心 X1 Turbo 的总成绩排到了最后两名。
其实,向今年数学卷发起挑战的大模型还有其他家,比如 Xiaomi MiMo-VL,一个只有 7B 参数的小模型。
该模型同样挑战了 2025 年数学新课标 I 卷,结果显示,总分 139 分,与 Qwen3-235B 分数相同,并只比 OpenAI o3 低一分。
并且,相较于同样 7B 参数的多模态大模型 Qwen2.5-VL-7B,MiMo-VL 整整高出了 56 分。
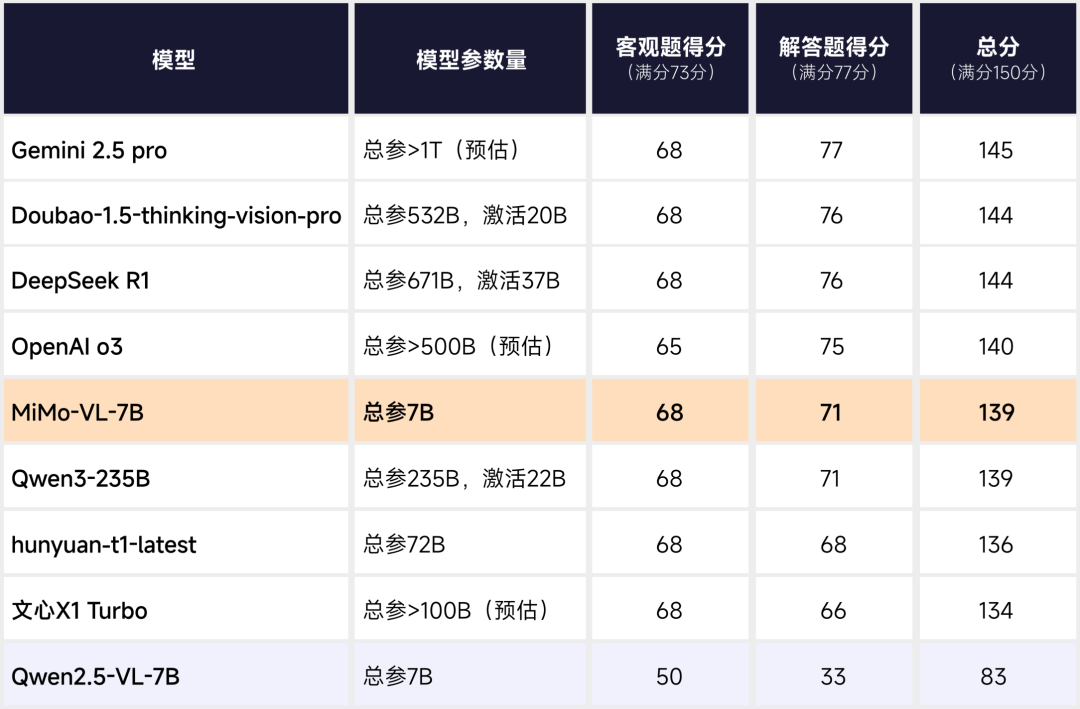
MiMo-VL-7B 和 Qwen2.5-VL-7B 是通过上传题目截图的形式针对多模态大模型进行评测,其余均是输入文本 latex 进行的评测;不做 System Prompt 引导,不开启联网搜索,直接输出结果。
我们接下来一一看 14 道客观题(总计 73 分)、5 道解答题(总计 77 分)的具体答题结果。
其中,MiMo-VL 在单选题中得到 35 分(总分 40)。

MiMo-VL 在多选题中得到满分(18 分)。
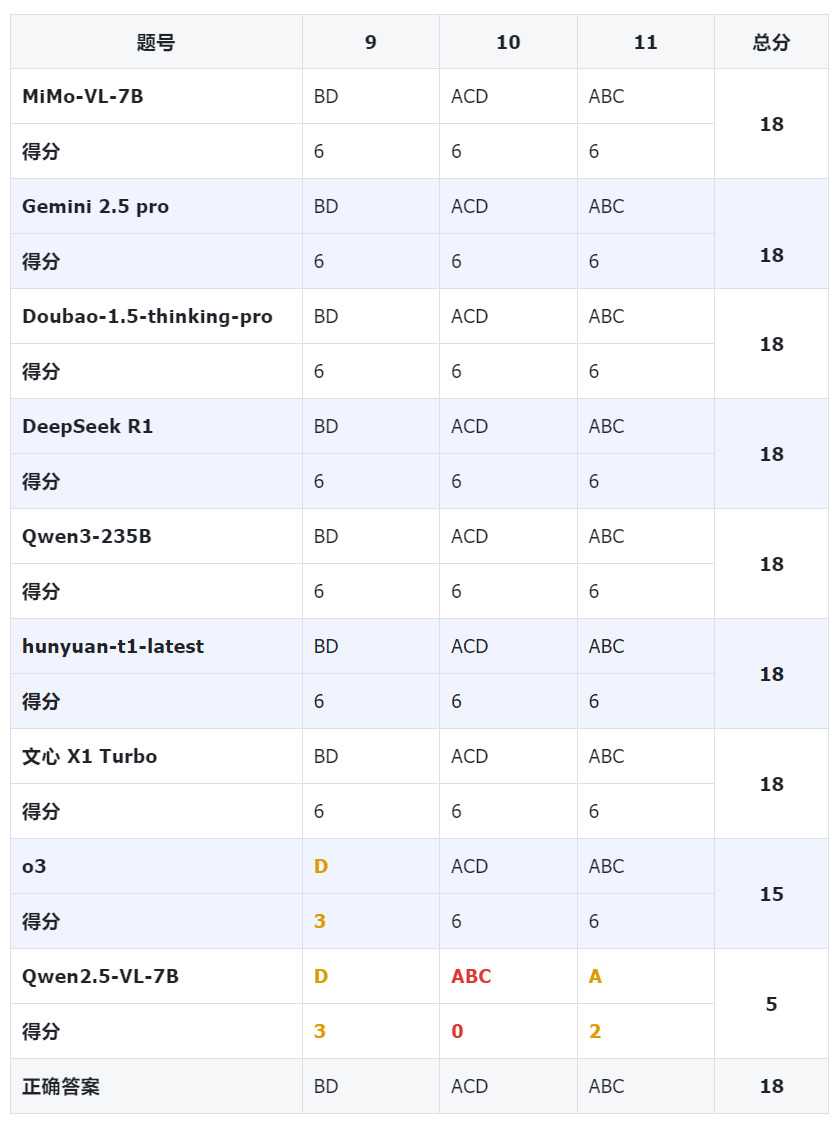
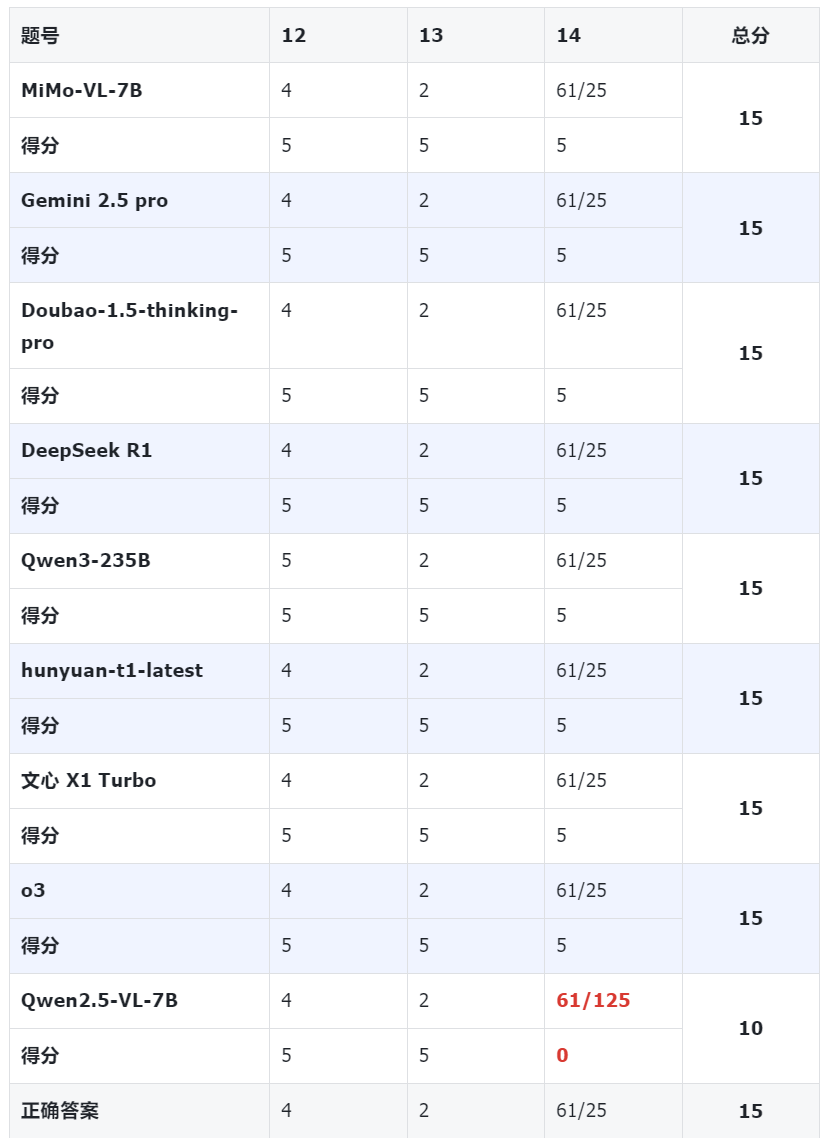
MiMo-VL 在填空题中同样得到满分(15 分)。
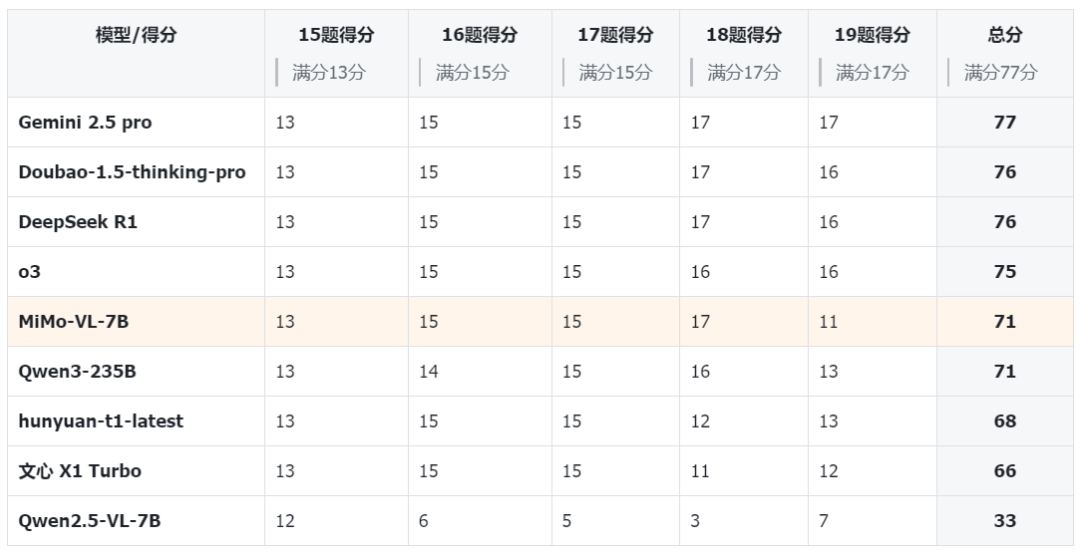
MiMo-VL 在解答题中得到了 71 分,位列第 5,超越了 hunyuan-t1-latest、文心 X1 Turbo。
查看详细测评截图以及答题情况,请移步:https://rwgi1pvz1gm.feishu.cn/docx/Z8dNdScFdopPwnxMJxfcnVpnnwh
比肩 Qwen3-235B、o3
7B 小模型如何做到?
今年 4 月 30 日,小米宣布开源了首个专注于推理的大模型「Xiaomi MiMo」,推理能力全面提升。
在数学推理(AIME 24-25)和代码竞赛(LiveCodeBench v5)公开测评集上,MiMo 仅用 7B 的参数规模,超越了 OpenAI 的闭源推理模型 o1-mini 和阿里 Qwen 更大规模的开源推理模型 QwQ-32B-Preview。
一个月后,该模型经过持续的 RL 训练,推理与通用能力再次大幅提升。在多个数学代码竞赛中,新版本模型 MiMo-7B-RL-0530 已经与最强开源推理模型 DeepSeek R1 和 OpenAI 闭源推理模型 o1、o3-mini 相差无几。
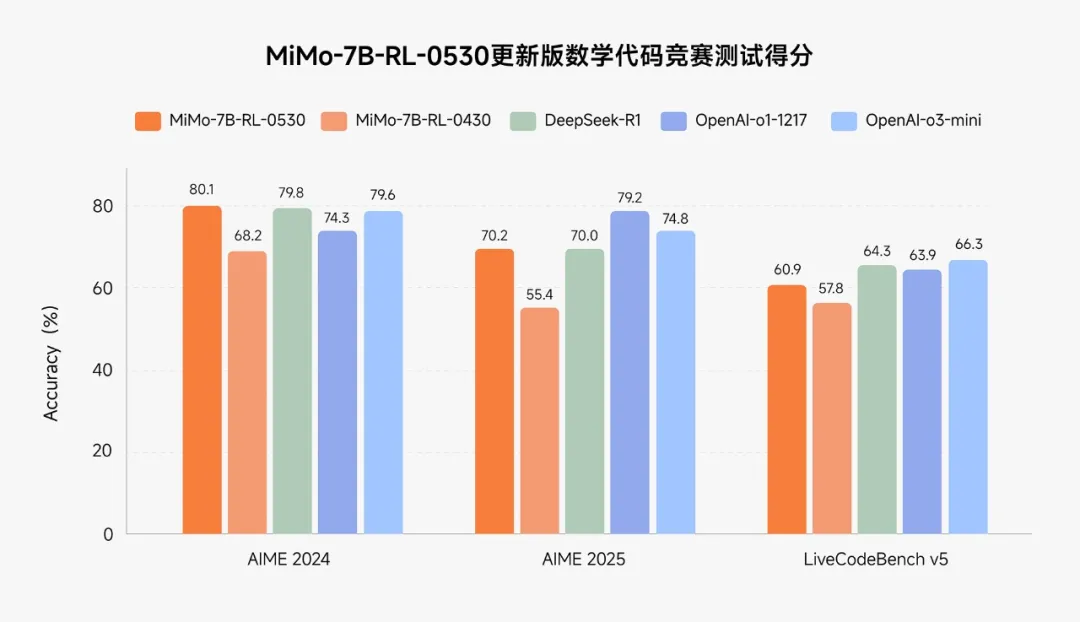
同一时间,MiMo-VL 作为 MiMo-7B 的后续版本推出,不仅在图片、视频、语言的通用问答和理解推理等多个任务上大幅领先同尺寸标杆多模态模型 Qwen2.5-VL-7B,还在 GUI Grounding 任务上比肩专用模型。
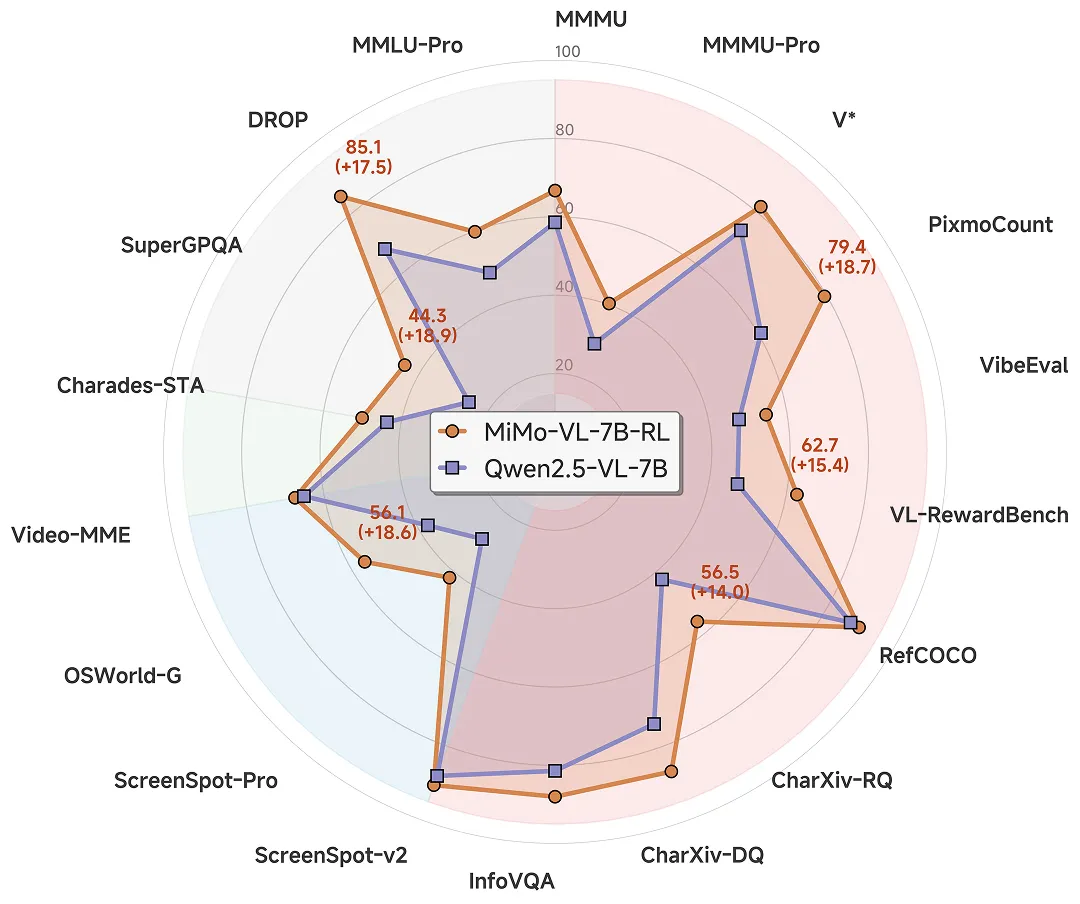
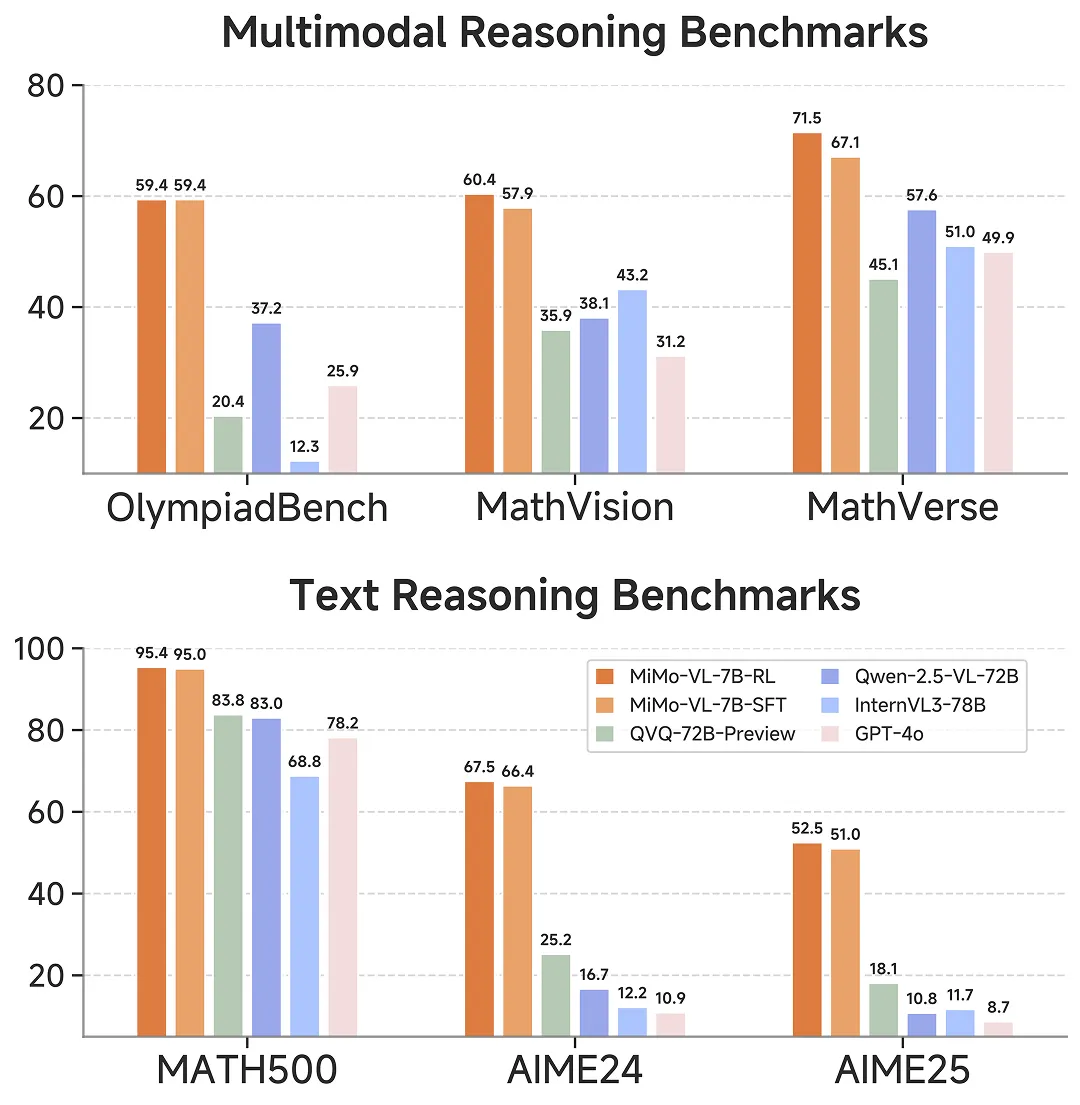
MiMo-VL 保持了 MiMo-7B 的纯文本推理能力,并在多模态推理任务上,仅用 7B 参数,在 OlympiadBench 以及 MathVision、MathVerse 等多个数学竞赛中大幅领先 10 倍参数大的阿里 Qwen-2.5-VL-72B 和 QVQ-72B-Preview,也超越闭源模型 GPT-4o。
在评估真实用户体验的内部大模型竞技场中,MiMo-VL-7B 同样超越了 GPT-4o,成为开源模型第一。

视觉理解能力展示。
从技术层面来看,MiMo-VL-7B 全面的视觉感知能力得益于高质量的预训练数据以及创新的混合在线强化学习算法(Mixed On-policy Reinforcement Learning,MORL)。
一方面收集、清洗、合成了高质量的预训练多模态数据,涵盖图片 – 文本对、视频 – 文本对、GUI 操作序列等数据类型,总计 2.4T tokens。通过分阶段调整不同类型数据的比例,强化长程多模态推理的能力。
另一方面,混合文本推理、多模态感知 + 推理、RLHF 等反馈信号,并通过在线强化学习算法稳定加速训练,全方位提升模型推理、感知性能和用户体验。
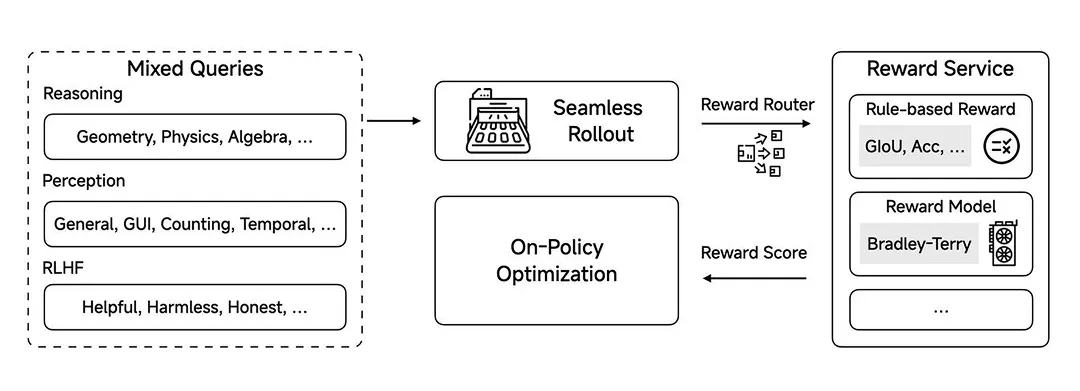
框架概览。
目前,MiMo-VL-7B 的技术报告、模型权重和评估框架均已开源。

-
已开源的 RL 前后两个模型:https://huggingface.co/XiaomiMiMo
-
技术报告地址:https://github.com/XiaomiMiMo/MiMo-VL/blob/main/MiMo-VL-Technical-Report.pdf

©
(文:机器之心)