


在大型语言模型(LLM)飞速发展的今天,如何进一步提升其性能,成为了研究者们关注的焦点。现在许多工作基于“重复采样-投票”框架在测试时进行大量采样以提高回答的准确性,有时一个问题甚至需采样成百上千次,这带来巨大的计算开销。我们不禁要问:我们真的需要那么多次采样吗?
本文介绍的 ModelSwitch 策略,正是在性能和效率间寻找一平衡点。它放弃一味增加单一模型的采样次数,而是巧妙地将采样预算分配给多个 LLM,利用它们之间潜在的互补优势。
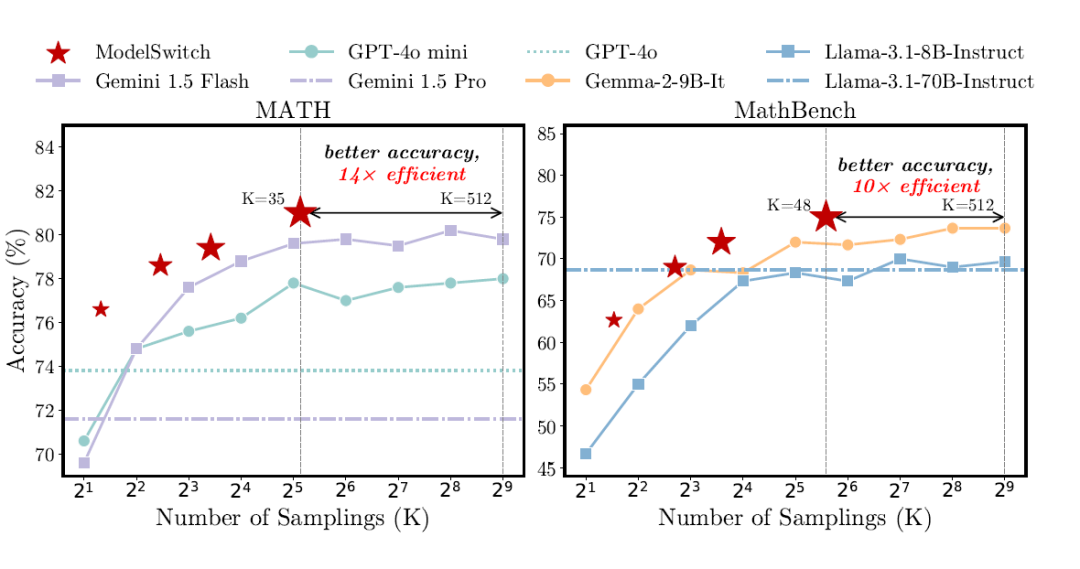
▲ 图1. quad ModelSwitch 与 Self-Consistency 在 Math 和 MathBench 数据集上的性能比较
如图 1 所示,在 MATH 数据集上,ModelSwitch(使用 GPT-4o mini 和 Gemini 1.5 Flash 的组合)仅仅通过 35 次采样便达到了 81% 的准确率,这一成绩不仅优于其中较强的 Gemini 1.5 Flash 单独采用 Self-Consistency 方法通过多达 512 次采样才达到的 79.8% 准确率,更在计算效率上实现了高达 14 倍的提升!
在 MathBench 数据集上,ModelSwitch(使用 Gemma-2-9B-It 和 Llama-3.1-8B-Instruct 的组合)仅用 48 次采样就达到了 75% 的准确率,优于其中较强的Gemma-2-9B-It 单独采用 Self-Consistency 方法在 512 次采样下达到的 73.7% 准确率,效率同样提升了 10 倍。

论文标题:
Do We Truly Need So Many Samples? Multi-LLM Repeated Sampling Efficiently Scales Test-Time Compute
论文链接:
https://arxiv.org/abs/2504.00762
项目代码:
https://github.com/JianhaoChen-nju/ModelSwitch

ModelSwitch算法机制详解
ModelSwitch 的核心机制是什么呢?答案是利用模型生成答案的一致性作为信号,在不同模型间进行智能切换。这一设计则是基于一项关键的经验性观察:一个模型的准确性,往往与其生成答案时表现出的一致性紧密相关。
可以想象,当一个模型面对某个问题,给出的答案五花八门、高度不一致时,这通常意味着它对这个问题“心中无数”,正确的可能性自然不高。
ModelSwitch 捕捉到这种不确定的信号后,并不会继续强求当前模型,而是果断地切换到另一个 LLM,期待下一个模型可能知道前一个模型不知道的东西。如果后续模型能够给出高度一致的答案,那么获得正确解的概率便会大大增加。
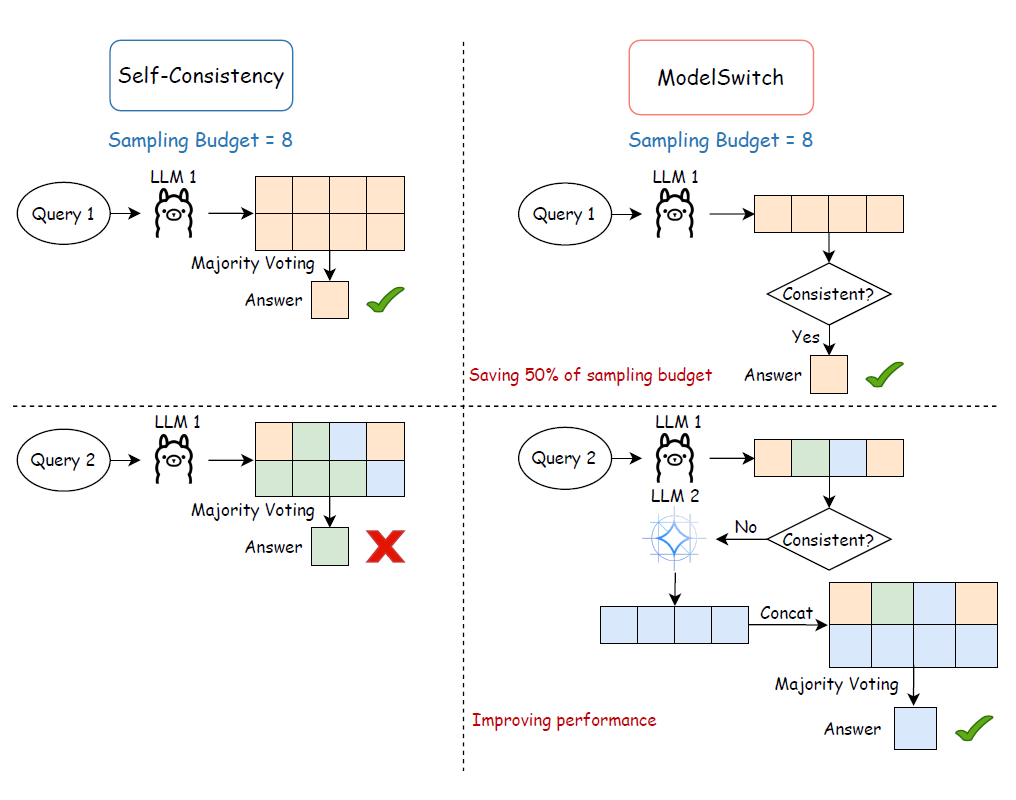
▲ 图2. ModelSwitch 在两个 LLM 间工作的示意图
参照图 2,ModelSwitch 算法在运行时会让多个 LLM 依次生成预先分配采样数量的答案。如果当前模型 给出的所有答案完全一致,那么算法会自信地采纳这个答案,并提前终止整个流程,从而后续模型的计算开销得以节省。
但如果 的答案并不一致,算法会转交给下一个模型 继续采样,直至寻找到某个模型能生成完全一致的答案,若没有模型能产生完全一致的答案,或者所有模型都已采样,则汇总所有模型的答案。
这种动态切换不仅旨在提升最终答案的准确性,更重要的是,它同时显著降低不必要的计算成本。在汇总答案时,ModelSwitch 采用了一种加权投票算法。

加权投票算法综合考量了两个维度的权重:一是各模型对当前查询给出答案时自身的一致性 ,通过答案分布的熵来计算,一致性越高,熵越低,权重则越高。二是模型自身的先验性能 。这样的设计确保了既能动态捕捉模型在特定问题上的信心,又能顾及模型历史的表现。

性能评估
那么,ModelSwitch 在更广泛的实际测试中表现如何呢?研究团队在多达七个涵盖数学推理(GSM8K, MATH, AIME24)、常识及特定领域知识理解(MMLU-Pro)、符号推理(DATE)及多语言任务(MGSM)等多样化挑战的数据集上对 ModelSwitch 进行了广泛而严格的评估。
实验采用了多种闭源 LLM 包括 GPT-4o mini、Gemini 1.5 Flash、Claude 3 Haiku、GPT-4o、Gemini 1.5 Pro,以及多种开源 LLM 包括 Llama-3.1-8B-Instruct、Gemma-2-9B-It、Qwen2.5-7B-Instruct、Llama-3.1-70B-Instruct。
主要对比了单 LLM 重复采样-投票方法 Self-Consistency 和多种先进多智能体辩论方法包括 MAD、ChatEval、AgentVerse、MOA。
实验结果的多项关键发现凸显了 ModelSwitch 的价值:
首先,一项贯穿所有实验的基础性发现是:模型生成答案的一致性(以熵衡量,熵越低,一致性越大)与最终答案的准确性之间,存在着普遍且强烈的正相关关系。
如图 3 所示,答案的熵值与准确率呈现显著的负相关,相关系数 ∣r∣ 常大于 0.8 ,并且在统计学上极为显著(p<0.001)。这一横跨多种模型和数据集的普遍规律,为 ModelSwitch 依赖一致性作为核心判断信号的机制提供了坚实的实证基础——“一致往往意味着正确,而混乱则更容易出错”。
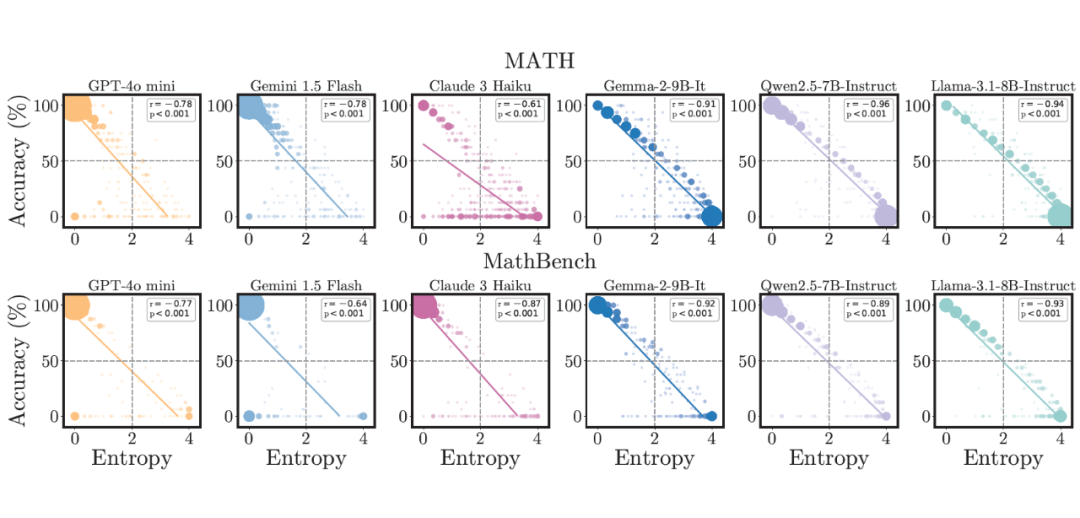
▲ 图3. 六种常见 LLM 在 MATH 和 MathBench 上的答案的一致性(熵)和准确性之间的相关性
其次,在与单模型 Self-Consistency 的较量中,ModelSwitch 展现了性能和效率的双重优势。如图 4 所示,在所有数据集上,ModelSwitch 使用两个 LLM(Gemini 1.5 Flash 和 GPT-4o mini)做切换的效果均超越单模型 Self-Consistency。
例如,在采样预算从 1 提高到 16 次时,ModelSwitch 在 MathBench 上的性能提升了 7 个百分点(从 72.7% 提升到 79.7%),显著超过了 Self-Consistency 为单模型带来的提升:Gemini 1.5 Flash 的 2.6 个百分点(从 72.7% 提升到 75.3%)和 GPT-4o mini 的 1 个百分点(从 71.7% 提升到 72.7%)。
与此同时,ModelSwitch 平均能节省 34% 的采样次数,从而大幅降低 API 调用成本与计算消耗。此外,较小模型的组合通过 ModelSwitch 能够超越单个更大参数模型的性能。例如在 GSM8K 上 ModelSwitch 同时超越了更大的模型 GPT-4o 和 Gemini 1.5 Pro。
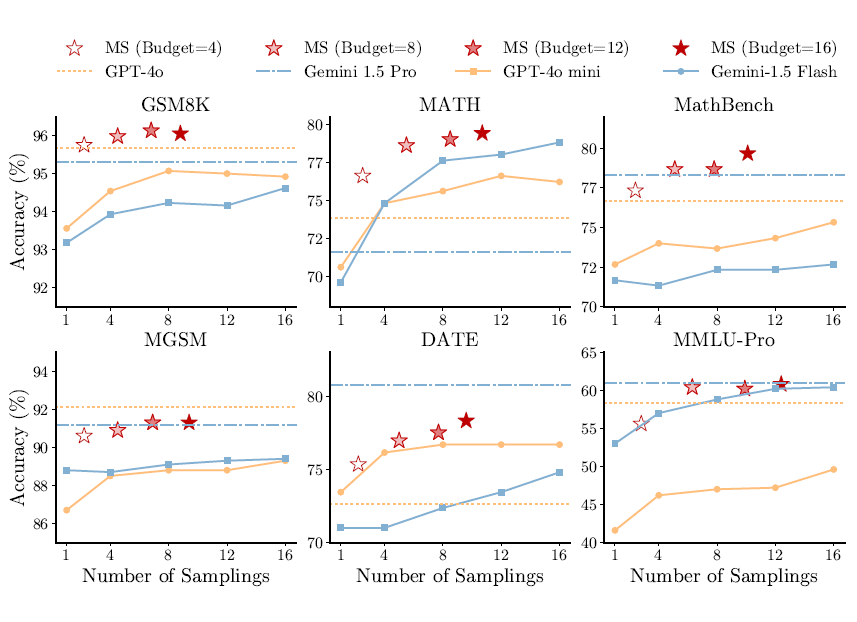
▲ 图4. 使用 GPT-4o mini 和 Gemini 1.5 Flash 组合的 ModelSwitch 和两种模型单独使用 Self-Consistency 的性能比较
再者,面对主流的多智能体辩论方法,ModelSwitch 同样综合表现更优。如图 5 所示,在统一设定为 15 次的公平采样预算下,ModelSwitch 在多个数据集上的性能超越了其他五种复杂的多智能体辩论框架。
尤其在极具挑战性的 MMLU-Pro 数据集上,ModelSwitch 的准确率达到了 63.2%,这比表现最佳的单个 LLM(53% )足足高出了 10.2 个百分点,并且显著优于 MAD(47.6%)和 MOA(52.6%)。
这背后的原因在于,ModelSwitch 采用简洁的切换机制,有效避免了在复杂的多智能体交互过程中可能出现的错误传播问题。
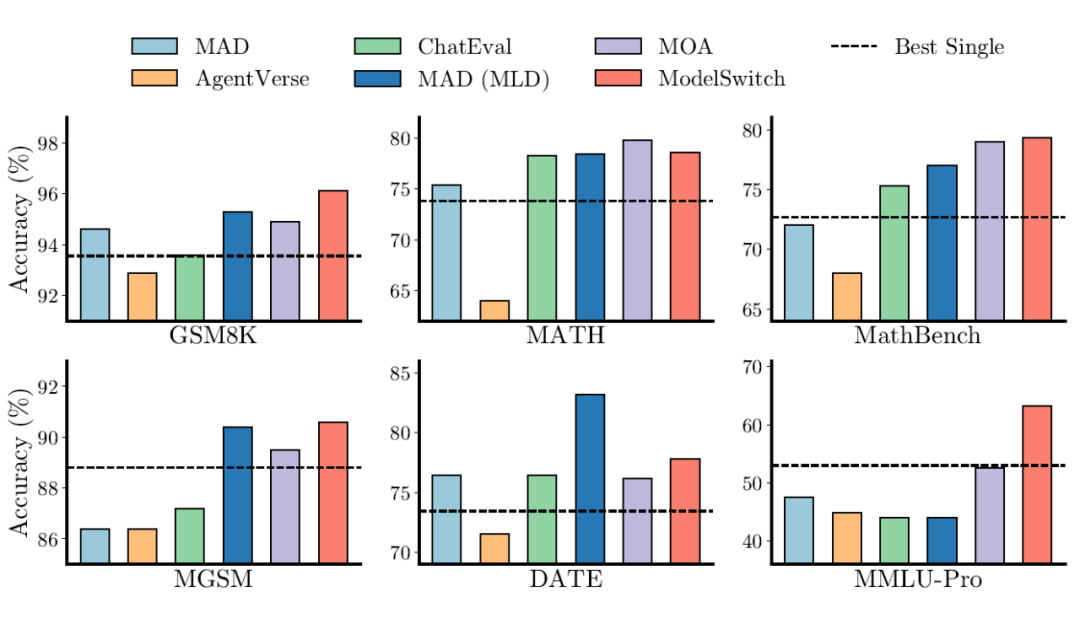
▲ 图5. ModelSwitch 和多智能辩论方法的性能对比

影响ModelSwitch效能的因素分析
实验还探究了 LLM 数量与排列顺序对 ModelSwitch 性能的影响。如图 6 所示,性能提升最为显著的阶段通常发生在 LLM 数量从一个增加到两个时。若继续增加 LLM 的数量,带来的收益可能会递减,性能可能趋于平稳或略有下降。
这启示我们,为 ModelSwitch 选择少数几个(通常是两个)性能相当且具有多样性的 LLM 组合,往往是达到最佳效果的关键。
至于模型的排列顺序,按从强到弱的顺序排列通常能通过尽早达成一致来提高整体效率,但 ModelSwitch 对模型顺序表现出了较好的鲁棒性,即使是从弱到强的排列,最终性能也未出现急剧下降。
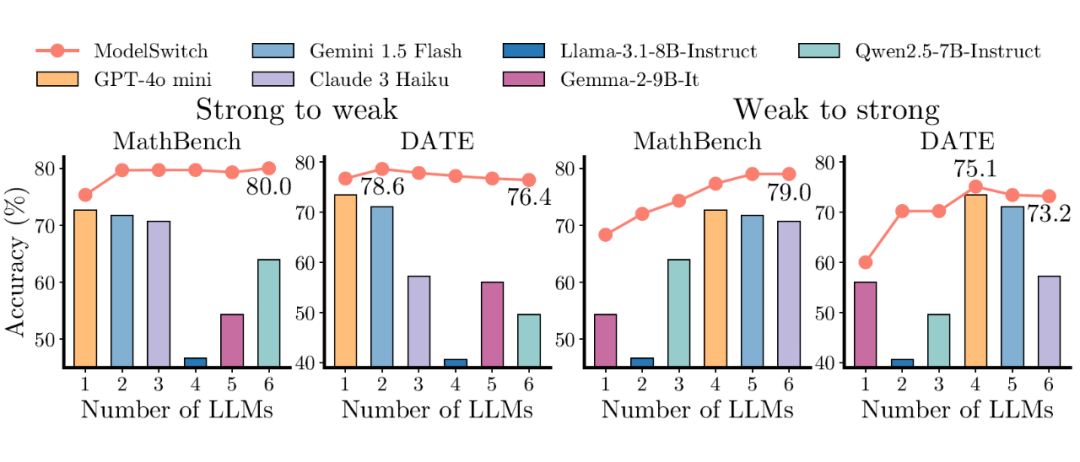
▲ 图6. 模型数量和顺序对 ModelSwitch 的性能影响
最后,ModelSwitch 还能与更强大的验证机制有效结合,实现性能的进一步飞跃。如图 7 所示,当 ModelSwitch 与基于 Qwen2.5-MATH-RM-72B 这类高性能奖励模型的 Best-of-N 选择策略(简称 RM-BoN)相结合时,其性能得到了进一步提升。
在 MATH 数据集上,结合 RM-BoN 后的准确率从多数投票的 80% 提升到了 84%。并且,ModelSwitch+RM-BoN 的组合依然能够优于最佳的单个 LLM 结合 RM-BoN 的策略。
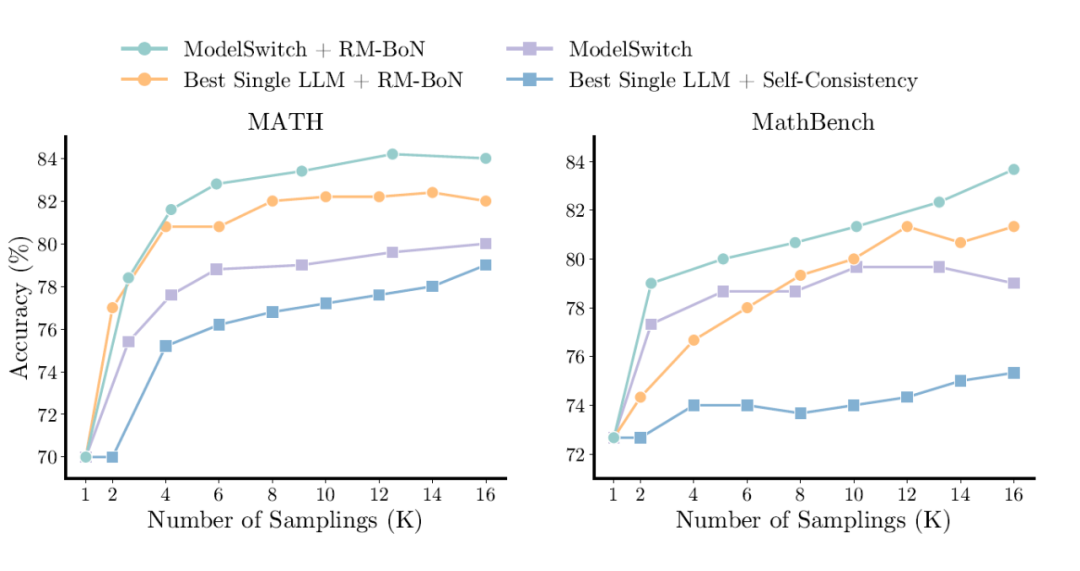
▲ 图7. ModelSwitch 和单模型结合奖励模型作为验证机制的性能对比

论文总结
ModelSwitch 是一种无需额外训练或复杂模型融合的简单、高效策略。它通过基于答案一致性的动态模型切换机制,巧妙地利用了多个 LLM 在测试计算时的互补优势,在多种基准测试中显著提升了整体性能和计算效率。
该方法的核心机制基于模型答案一致性与准确性之间强相关性的经验观察,并得到了坚实的理论分析支持。
总的来说,ModelSwitch 为如何有效扩展大型语言模型在推理时的计算能力,提供了一个简单普适且卓有成效的解决方案。
(文:PaperWeekly)