
大家好,今天给大家分享一个图像生成的新工作—-Marrying Autoregressive Transformer and Diffusion with Multi-Reference Autoregression,后面我们简称TransDiff。

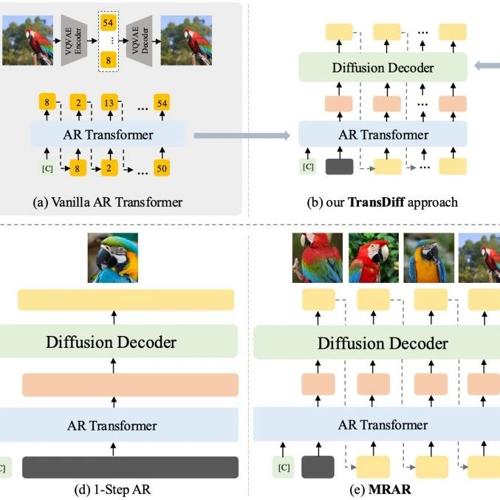
首先,TransDiff是目前最简洁的、将AR Transformer与Diffusion结合用于图像生成方法。TransDiff将离散输入(如类别、文本等)、连续输入(图像等)经过AR Transformer 编码 为图像语义表征,而后将表征通过一个较小的Diffusion Deocder 解码 为图片。
其次,我们提出了一种新的自回归范式– MRAR(Multi-Reference Autoregression)。此范式类似NLP领域的In-context Learning(ICL):通过学习上文同类别图片生成质量更好、更多样的图片,唯一的区别是上文的图片是模型自己生成的。
Paper: https://arxiv.org/pdf/2506.09482
Code:https://github.com/TransDiff/TransDiff
Model: https://huggingface.co/zhendch/Transdiff
具体介绍
为了节省读者的时间,抛弃论文的结构,用Q&A这种更简介的方式介绍TransDiff。
问:为什么使用Transformer?我们工作中AR Transformer编码出了什么信息?
答:早期的CLIP工作以及后来大模型时代层出不穷的VL模型已经证明Transformer在图像理解领域的优势。尤其是在CLIP工作中,ViT模型可以将图片的表征对齐到语义空间(文字bert表征与图片的ViT表征cosine相似度)。
相似的,实验证明:TransDiff中AR Transformer也是将类别和图片编码至图片的高级(对比像素)语义空间。以下将不同类别的256维特征随机进行拼接后生成得到图片,不同于其他模型(VAR、LlamaGen等)的像素编辑,定性实验展现出了模型的语义编辑能力。

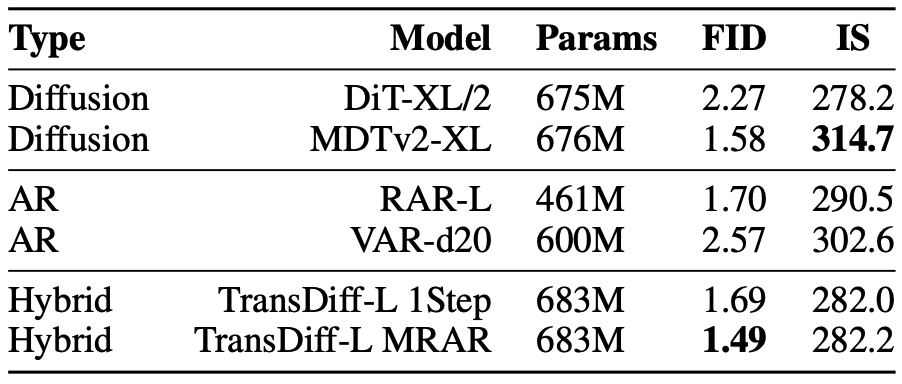
问:TransDiff使用较小Diffusion Deocder是否有制约? 是否优于单纯Diffusion和AR Transformer方法?
答:TransDiff的deocder使用DiT结构,使用Flow Matching范式。diffusion占总体参数的1/3,参数量显著低于主流diffusion模型。但是对比能够搜集到的所有单纯Diffusion和AR Transformer方法,TransDiff在Benchmark上还是有一定优势,至少是“打的有来有回”。
问:TransDiff很像MAR,是否只是MAR的简单模仿?
答:TransDiff与MAR虽然结构上很像,但是模型展现的特点截然不同。首先,MAR是在像素(或patch)上生成,没有显性的语义表征,其次由于MAR使用的Diffusion Deocder过于简单(n层MLP Layer)导致decoder表现力有制约。 因此,从下图可以看出:MAR无法 “一步生图”,且图像patch是在自回归过程中逐步迭代“完善”。

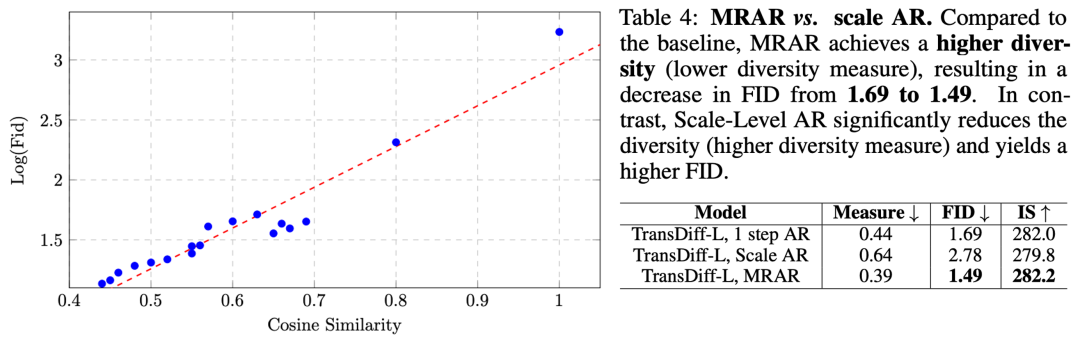
问:MRAR好在哪里? 对比AR Transformer中常用的Token-Level AR 和 Scale-Level AR优势吗?
答:首先对比Token-Level AR和Scale-Level AR,TransDiff with MRAR在在Benchmark上有着较大的优势。其次,我们发现 语义表征多样性越高,图像质量越高。而MRAR相较于Scale-Level AR可以显著提升语义表征多样性。
最后放一些demo

One More Thing
TransDiff with MRAR在未经视频数据训练的情况下,展现出了连续帧生成的潜力。 所以后续也会将TransDiff应用在视频生成领域,大家敬请期待。

(文:PaperAgent)