


昨天,我不是写了篇用Agent做PPT的文章嘛。
我用MiniMax Agent做PPT,实在太爽了
发完稿后,我看到豆包新上线了一个功能:AI播客。
我就把这篇文章丢给了她。结果你猜怎么着,当我听到第一口声音出来的时候,直接就跪了。这也太像真人了吧,完全没有一丝AI味道,是一丝都没有啊。
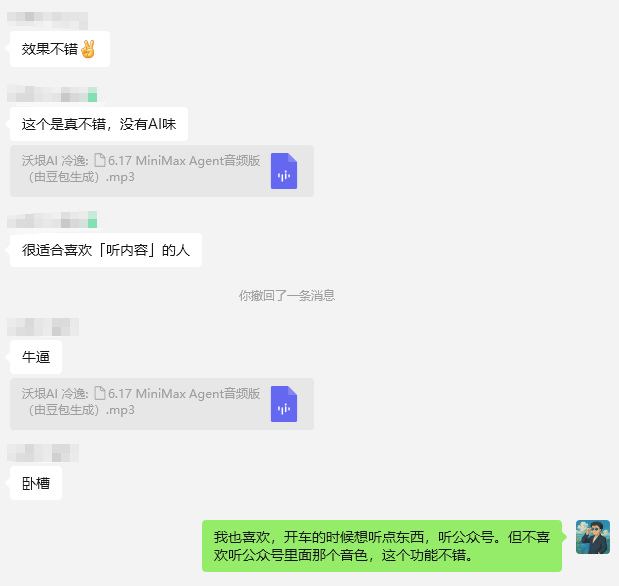
我把这个音频发到了群里,大家都说NB。

怎么体验?
要做这个播客音频,很简单。
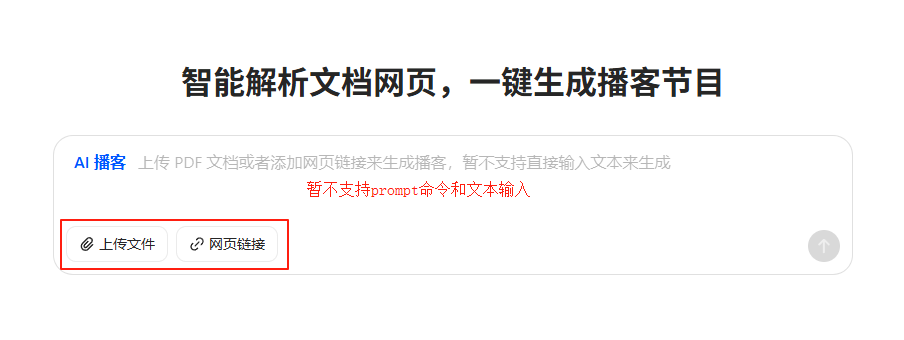
你什么都不用管,只需要发1个链接或者PDF给豆包就可以了,prompt不用写,音色不用选,内容不用管。豆包全盘帮你搞定。
目前,可以在豆包电脑版和网页版上进行体验。
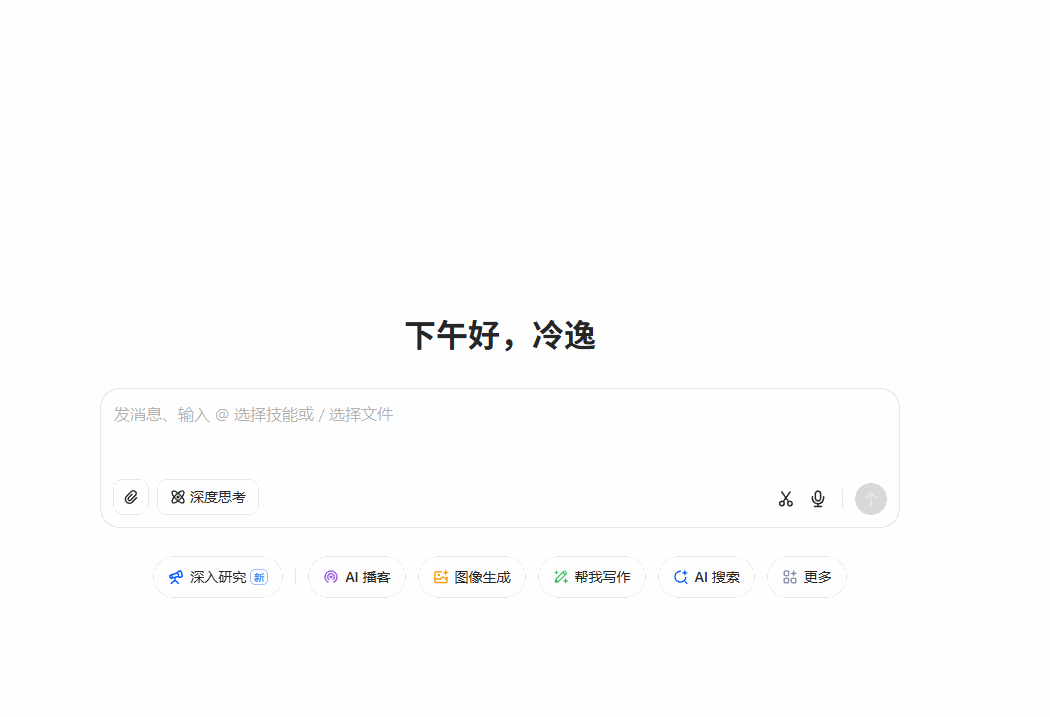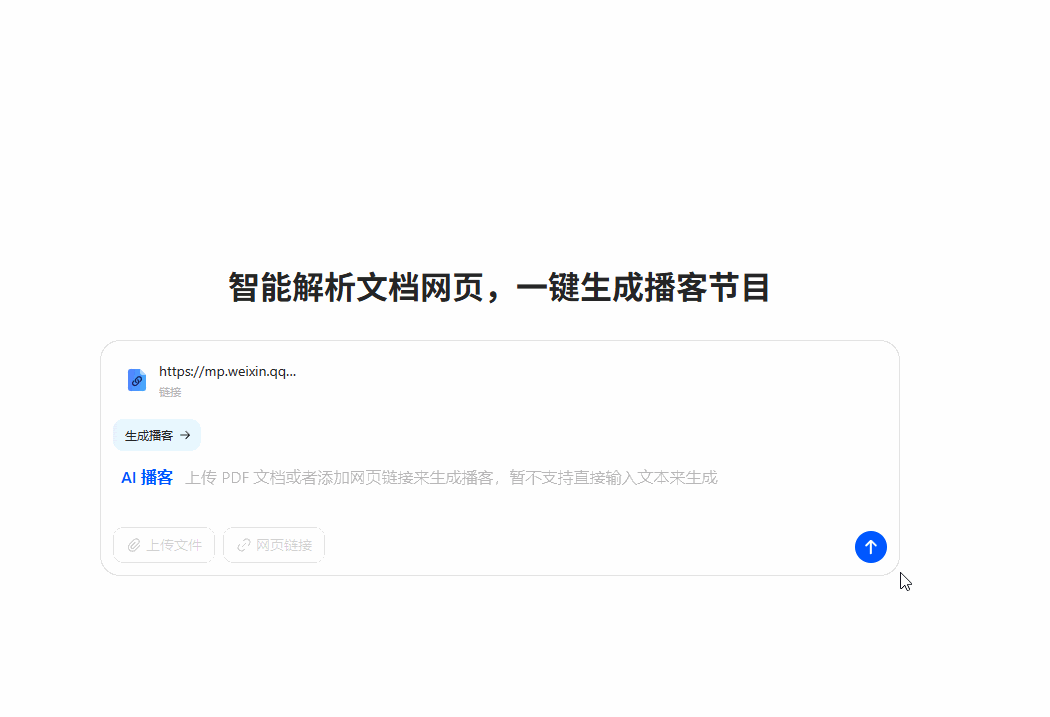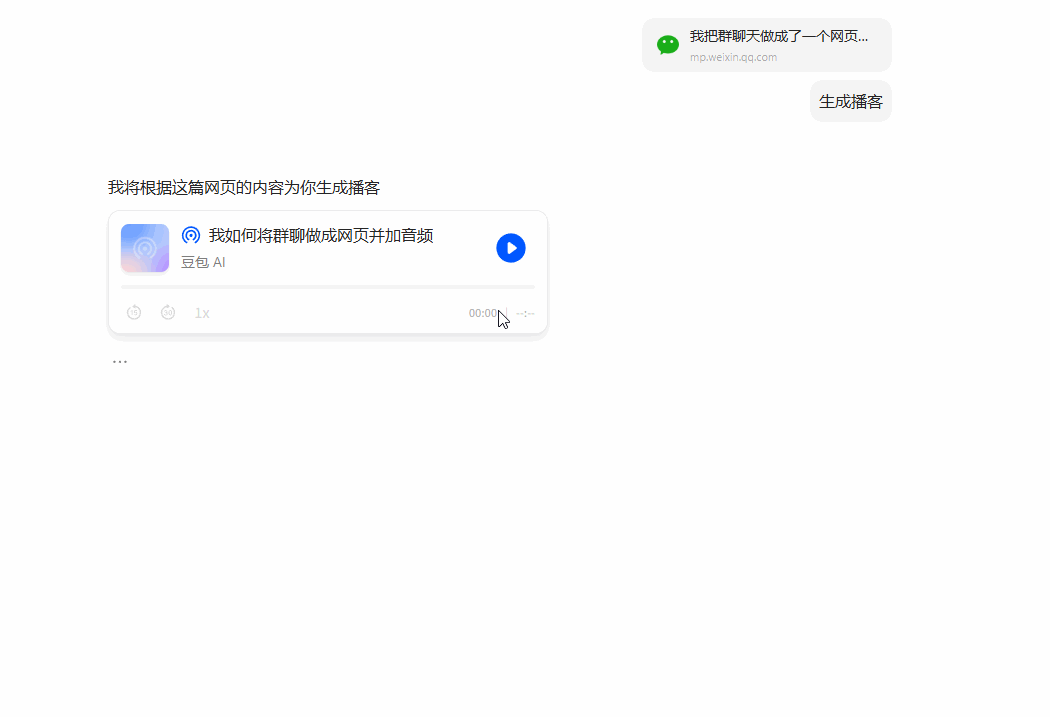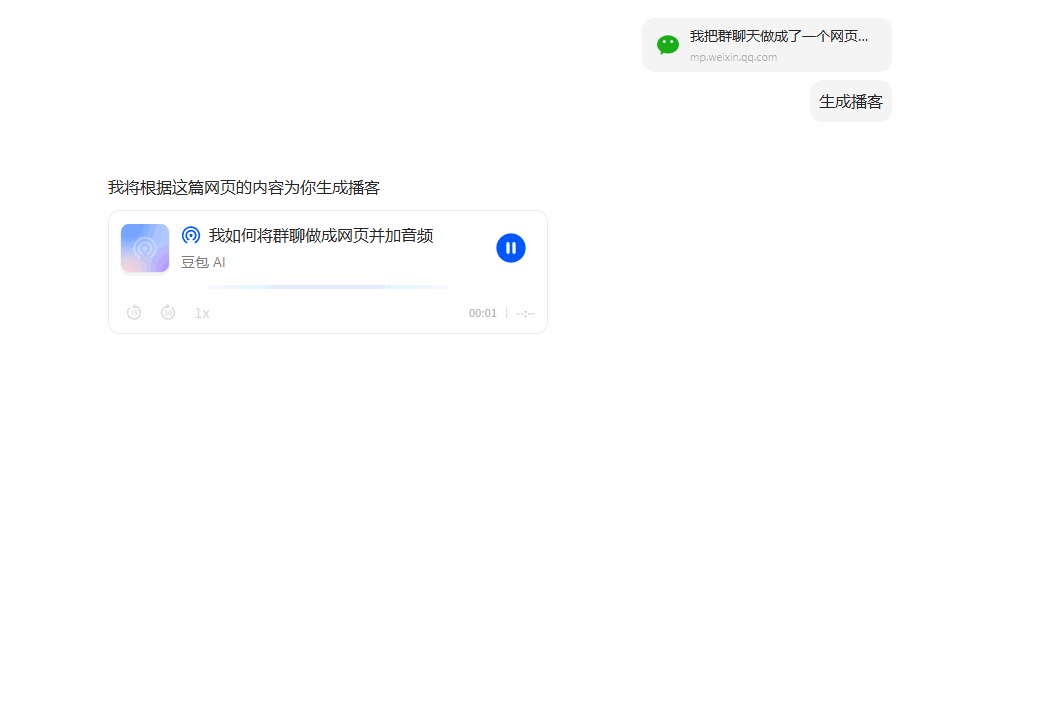
以豆包网页版为例,进入www.doubao.com后,在下方功能区选择“AI播客”。
然后,上传文件(PDF)或网页链接就可以了(暂不支持文本输入)。
上传后,不需要等待,直接马上就可以听。
这速度!这质量!真的太顶了。
上周五的文章(我把群聊天做成了一个网页),我也做了一个音频。
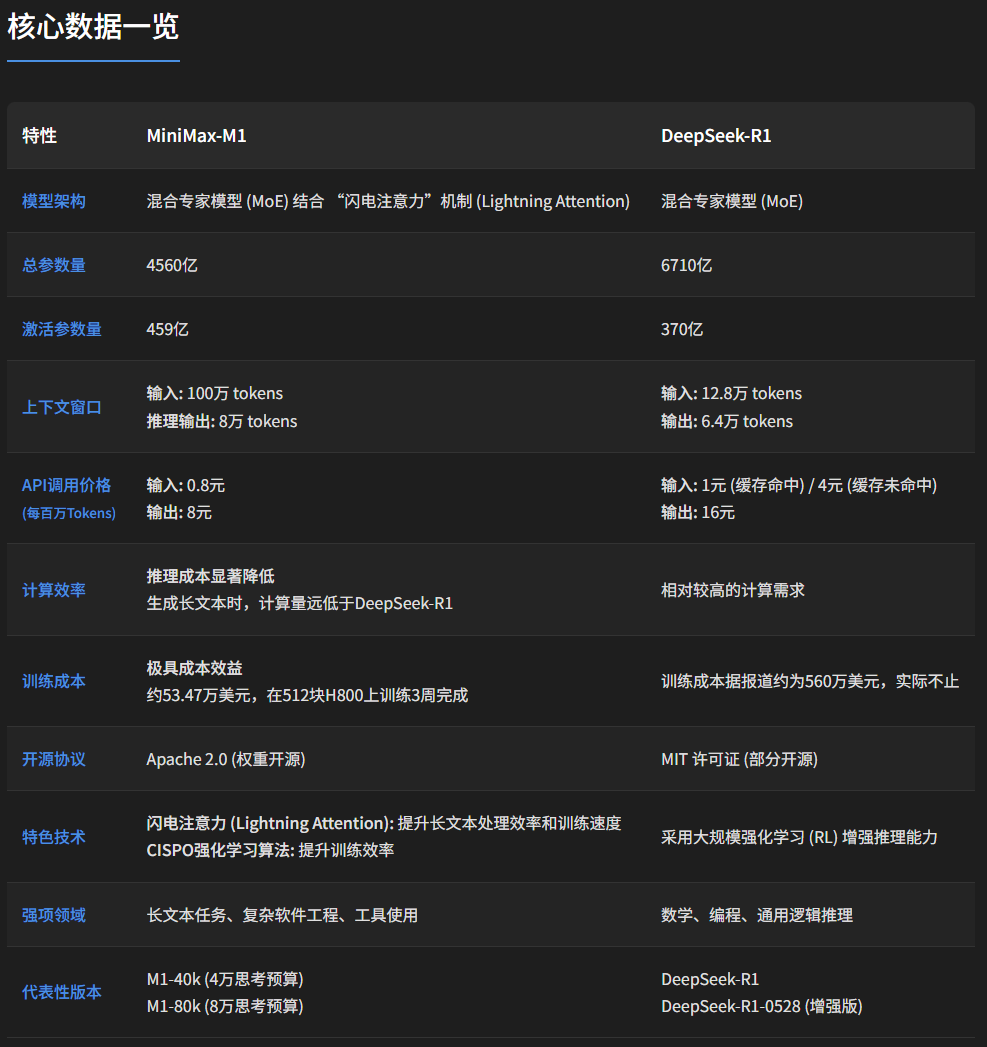
最近,MiniMax开启连续5天的发布周。昨天,他们发布并开源了全球首个大规模混合架构的推理模型MiniMax-M1。一如既往,在长上下文方面很强,输入最高支持100万token,输出支持8万token。
从训练成本到API价格,都比DeepSeek-R1降了不少。
图表by Google AI studio
我想了解M1为何这么能打,于是我把技术报告下载了下来。但是,这全英文……我根本看不懂啊。
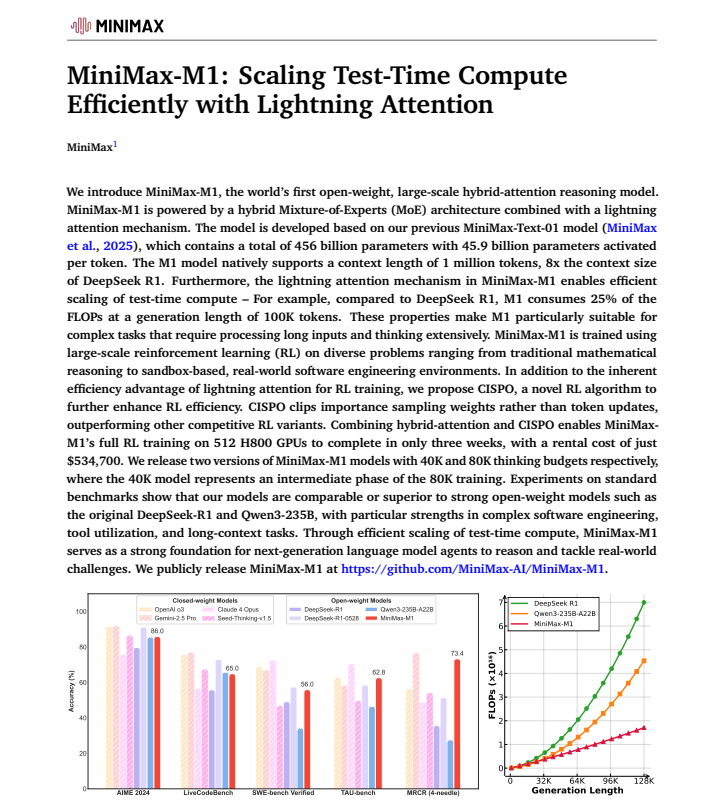
于是,我立马丢给了豆包,这回懂了。
后面,我又陆续测了10来个case。总的来说,豆包“AI播客”功能有着这些优点:
-
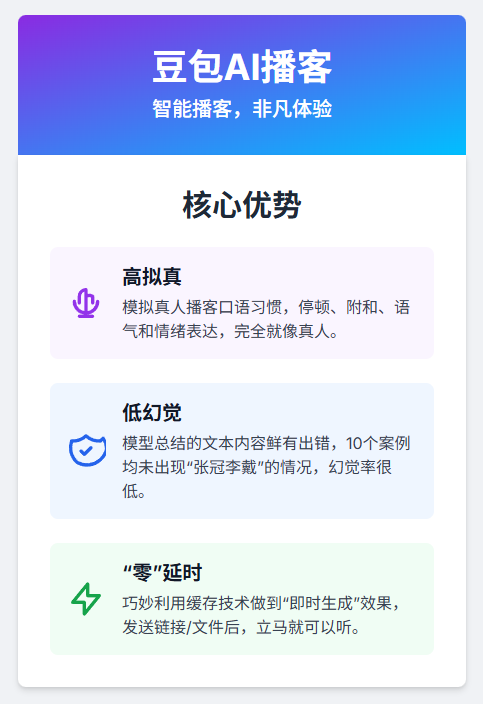
1.高拟真。模拟真人播客口语习惯,在停顿、附和、语气和情绪表达上确实没得说,完全就像是真人一样。
-
2.低幻觉。模型总结的文本内容鲜有出错,10个case里均未出现“张冠李戴”的情况,幻觉率很低。
-
3.“零”延时。巧妙利用缓存技术做到了“即时生成”的效果,发送链接/文件后,立马就可以听。
Powered by Gemini 2.5 pro正式版
如果非要挑一些缺点的话,那就是在长句生成上会出现一丢丢卡顿。当然,我们人说长句子也很难做到流畅表达,可以理解。
我上一家公司,是做知识付费的,有时候自己需要录点课程。1小时的课程,基本上我要录一整下午,而且每次都是10几分钟、10几分钟的录,后期还要靠剪辑师和修音师帮我优化。
而现在,豆包这个语音播客模型直接一键帮我搞定。
是真的一键。

模型揭秘
其实,这个语音播客模型并不新鲜。
早在5月20号,火山引擎就放出了这个模型的demo(文章详情)。
当时,我把这条消息发到沃垠AI群里,大家都说太NB,太逼真了。
简单说就是,这个模型由豆包Seed团队技术转化,它基于流式模型构建,实现了从文本创作到双人对话式播客的秒级转化,是一个精调的TTS模型,包括文本总结prompt、音色模型和音频生成workflow,一同进行了封装。
后来,这个模型上架到火山方舟里,所有开发者可以调用。
5月28号左右,扣子空间(一款通用Agent)也上线了这个模型,支持调用。
今天,豆包则直接把这个模型产品化,内置进功能区。
当然,如果你在豆包电脑版里面使用,那就更简单了,直接点击右上角的“问问豆包”就可以。
目前,生成的播客不支持下载。这里分享给大家一个小技巧,可以把播客音频下载下来。
以Chrome浏览器为例,进入豆包播客生成页面,按下F12键,打开“开发者工具”(Developer Tools),找到NetWork,点击Meida区。
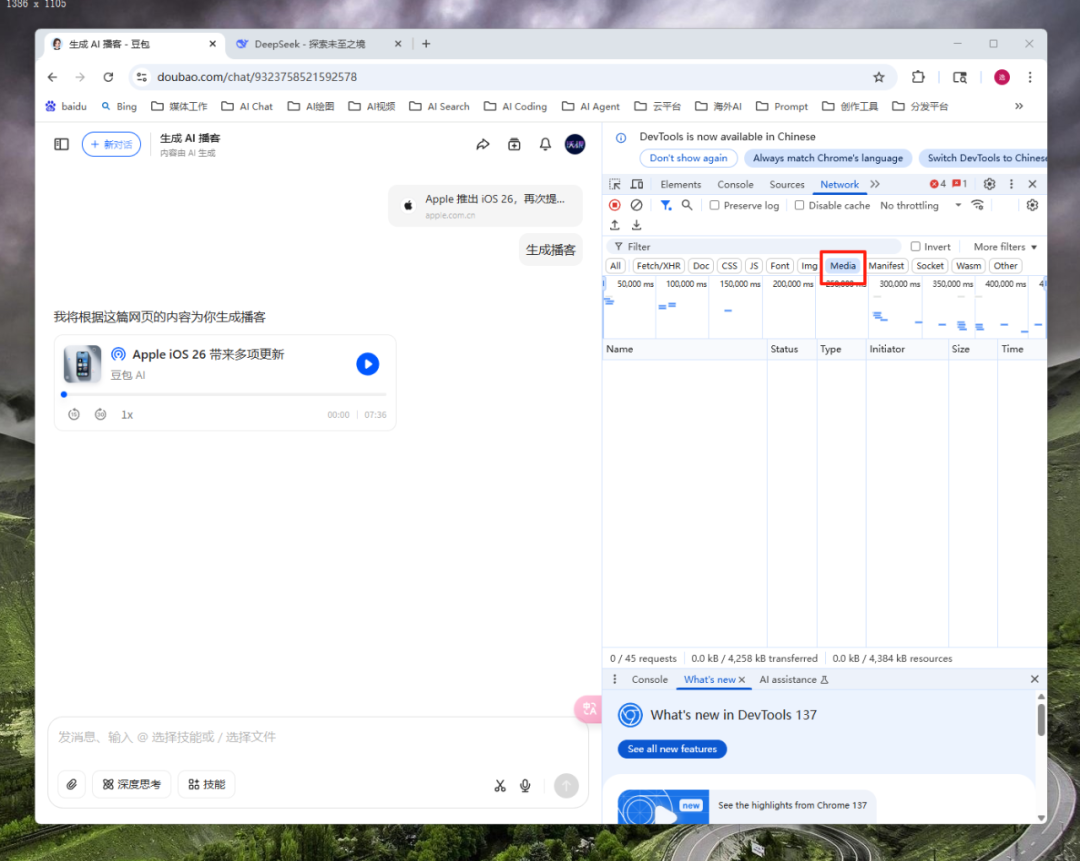
这时,再返回左侧网页,点击播放按钮,Meida区出现一个音频文件,右键音频文件,copy这个url。然后,重新打开一个浏览器窗口,粘贴上url,就可以把音频下载下来了。
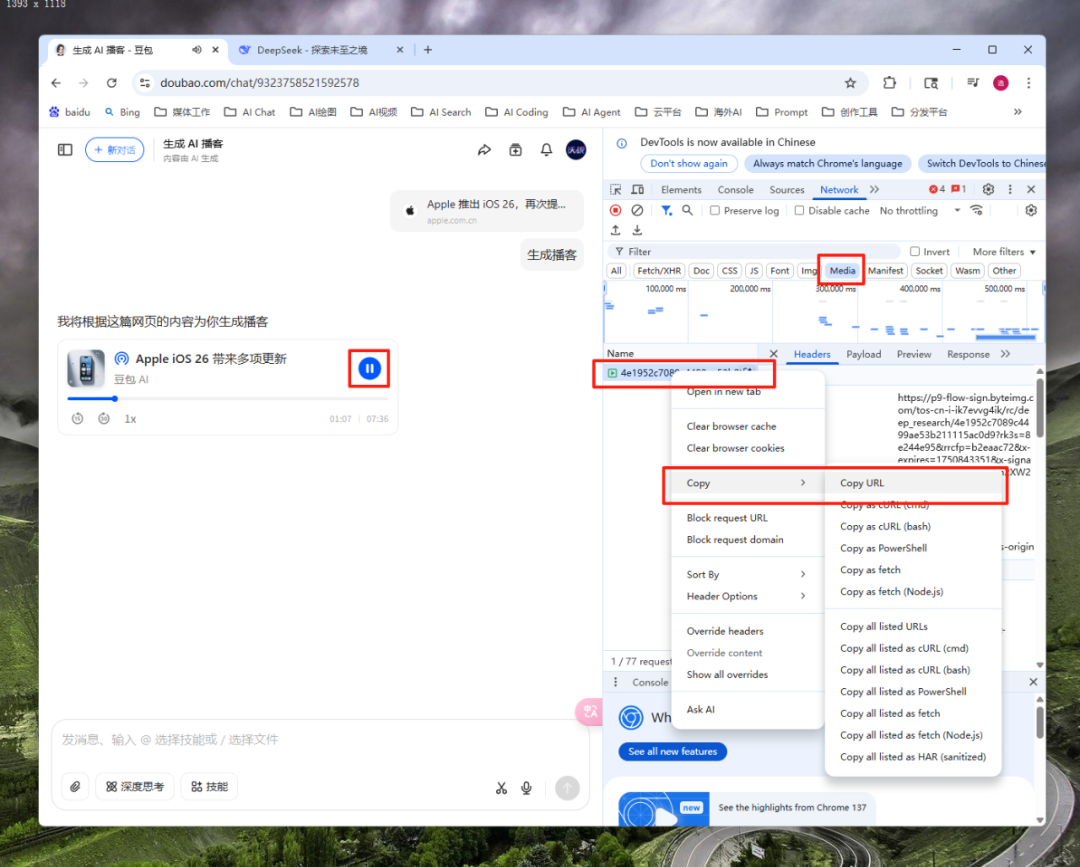
如果下载下来的音频没有格式,我们可以手动改成.mp3。

写在最后
现在,有了音频,是不是想让形式更像播客一点?
这里,我把我用R1开发的音频可视化播放器,免费开源给到大家(后台回复“播放器”下载)。
只需要把音频传上去,一个可视化的播客视频就有了。
希望这篇文章你能够喜欢,能够帮到大家。如果觉得内容不错的话,记得给我们点赞 、转发↷和推荐
、转发↷和推荐 ,感谢你的三连~
,感谢你的三连~
我们,下期见。
(文:沃垠AI)