

极市导读
南京大学、清华大学和腾讯联合研发的IBQ技术,一种用于训练可扩展视觉分词器的向量量化方法。文章详细阐述了IBQ如何通过全代码更新策略解决传统向量量化方法在扩展性上的困难,并展示了IBQ在重建和自回归视觉生成方面的优异性能。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文链接:https://arxiv.org/pdf/2412.02692
github链接:https://github.com/TencentARC/SEED-Voken

亮点直击
提出了一种简单而有效的向量量化方法,称为索引反向传播量化(Index Backpropagation Quantization,IBQ),用于训练可扩展的视觉分词器。 通过增加码本大小、编码维度和模型规模来研究IBQ的扩展特性。IBQ首次训练了一个超大码本(),具有大维度(256)和高使用率,实现了最先进的重建性能。 展示了一系列从300M到2.1B的基础自回归图像生成模型,显著超越了竞争方法,例如LlamaGen和 Open-MAGVIT2。
总结速览
解决的问题
现有的向量量化(VQ)方法在可扩展性方面存在困难,主要由于训练过程中仅部分更新的码本的不稳定性。随着利用率的降低,码本容易崩溃,因为未激活代码与视觉特征之间的分布差距逐渐扩大。
提出的方案
提出了一种新的向量量化方法,称为索引反向传播量化(Index Backpropagation Quantization,IBQ),用于码本embedding和视觉编码器的联合优化。通过在编码特征与码本之间的单热编码分类分布上应用直通估计器,确保所有代码都是可微的,并与视觉编码器保持一致的潜空间。
应用的技术
-
使用直通估计器在单热编码分类分布上进行优化,使得所有代码可微。 -
通过IBQ实现码本embedding和视觉编码器的联合优化。 -
研究了IBQ在增加码本大小、编码维度和模型规模方面的扩展特性。
达到的效果
-
IBQ使得视觉分词器的可扩展训练成为可能,首次实现了大规模码本()的高维度(256)和高利用率。 -
在标准ImageNet基准上的实验表明,IBQ在重建(1.00 rFID)和自回归视觉生成方面取得了具有竞争力的结果。 -
展示了一系列从300M到2.1B的基础自回归图像生成模型,显著超越了竞争方法,如LlamaGen和Open-MAGVIT2。
效果展示
-
下图的上半部分展示了在1024×1024分辨率下,IBQ分词器在Unsplash数据集上的测试结果。下半部分则展示了IBQ分词器在256×256分辨率下,针对Imagenet数据集的测试结果。(a)表示原始图像,(b)表示重建图像。


-
Imagenet上256×256类条件生成样本效果:


方法
我们的框架由两个阶段组成。第一阶段是通过索引反向传播量化学习一个具有高码本利用率的可扩展视觉分词器。在第二阶段,我们使用自回归变换器通过下一个标记预测进行视觉生成。
Preliminary
向量量化 ( VQ 将连续的视觉信号映射为具有固定大小码本 的离散标记, 其中 是码本的大小, 是代码维度。给定一张图像 首先利用编码器将图像投影到特征图 , 其中 是下采样比例。然后, 特征图被量化为 , 作为码本的离散表示。最后, 解码器根据量化后的特征重建图像。
对于量化,以往的方法通常计算每个视觉特征 与码本中所有代码的欧几里得距离,然后选择最近的代码作为其离散表示。由于量化中的 操作是不可微的, 他们在选定的代码上应用直通估计器, 以从解码器复制梯度, 从而同时优化编码器。量化过程如下:

其中,是停止梯度操作。
这些方法采用的部分更新策略(即仅优化选定的代码)逐渐扩大了视觉特征与未激活代码之间的分布差距。这会导致训练期间的不稳定性,因为码本崩溃会阻碍视觉分词器的可扩展性。
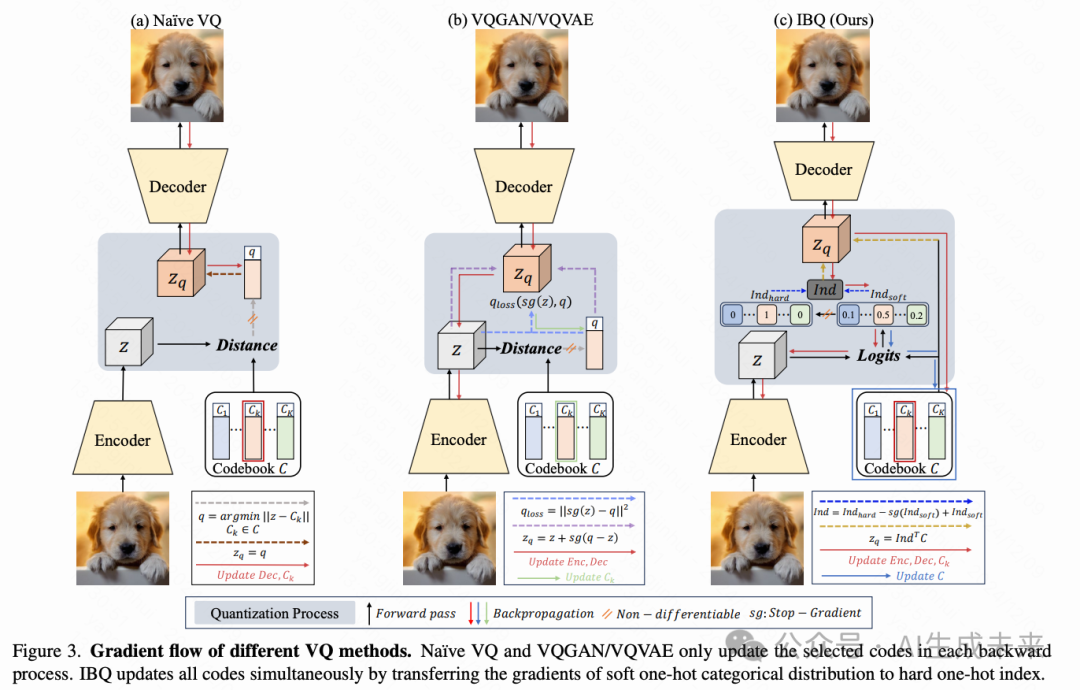
索引反向传播量化
量化。 为了确保在训练过程中码本与编码特征之间的一致分布,我们引入了一种全代码更新方法,即索引反向传播量化(Index Backpropagation Quantization, IBQ)。IBQ的核心在于将梯度反向传播到码本的所有代码,而不仅仅是选定的代码。算法1提供了IBQ的伪代码。

具体来说,我们首先对给定的视觉特征与所有代码embedding进行点积运算作为logits,并通过softmax函数获得概率(soft one-hot)。

然后我们将soft one-hot 类别分布的梯度复制到hard one-hot索引上:

给定索引,量化后的特征通过以下方式获得:

通过这种方式,我们可以通过索引将梯度传递到码本的所有代码上。通过索引反向传播量化,整个码本和编码特征的分布在整个训练过程中保持一致,从而获得较高的码本利用率。
训练损失。 与 VQGAN类似,分词器的优化由多种损失的组合完成:

其中, 是图像像素的重建损失, 是选定的代码embedding与编码特征之间的量化损失, 是来自 LPIPS 的感知损失, 是使用 PatchGAN 判别器 [10] 增强图像质量的对抗损失, 是鼓励码本利用的熵惩罚。我们进一步引入双重量化损失, 以迫使选定的代码embedding和给定的编码视觉特征相互靠近。

与其他 VQ 方法的讨论。 向量量化(VQ)将连续的视觉特征离散化为具有固定大小码本的量化代码。朴素的 VQ 选择与给定视觉特征具有最近欧氏距离的代码。由于操作是不可微的,梯度流回到编码器时被截断,只有解码器的参数和选定的代码可以被更新。受直通梯度估计器的启发,VQ-VAE 和 VQGAN 将梯度从解码器复制到编码器进行梯度近似。它们还采用量化损失来优化选定代码以接近编码特征。因此,VQ 模型可以以端到端的方式进行训练。尽管已经取得了进展,这些 VQ 方法在扩展分词器以提高表示能力方面仍然存在困难。
如下图 3 所示,现有的 VQ 方法在每次反向过程中仅优化有限数量的代码以接近编码特征。这逐渐扩大了未激活代码和编码特征之间的分布差距,最终导致码本崩溃。随着代码维度和码本大小的增加,这种情况变得更加严重。我们不是直接将直通估计器 [1] 应用于选定的代码,而是将这种参数化方法应用于视觉特征和所有码本embedding之间的分类分布,以使梯度能够反向传播到所有代码。通过这种方式,整个码本和编码特征之间的分布在整个训练过程中保持一致。因此,IBQ 实现了具有高代码维度和利用率的极大码本。
自回归Transformer
在经过分词后, 视觉特征被量化为离散表示, 并随后以光栅扫描的方式展平以进行视觉生成。给定离散的token索引序列 , 其中 ,我们利用自回归transformer通过下一个token预测来建模序列依赖性。具体来说, 优化过程是最大化对数似然:
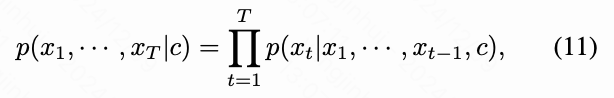
其中, 是条件, 例如类别标签。请注意, 由于我们专注于视觉分词器, 因此我们采用类似于 Llama 的自回归transformer的基础架构,并使用 AdaLN 进行视觉生成。
实验
数据集和指标
视觉分词器和自回归transformer的训练均在256×256的ImageNet上进行。对于视觉重建,采用重建-FID(记为rFID)、码本利用率和LPIPS在ImageNet 50k验证集上来衡量重建图像的质量。对于视觉生成,我们通过常用的指标FID、IS和Precision/Recall来衡量图像生成的质量。
实验细节
视觉重建设置。 我们采用了VQGAN中提出的相同模型架构。视觉分词器的训练设置如下:初始学习率为 , 采用 0.01 的多步衰减机制, 使用Adam优化器, 其参数为 , 总批量大小为 256,共330个epoch,训练过程中结合了重建损失、GAN损失、感知损失、承诺损失、摘损失、双量化损失,以及LeCAM正则化以确保训练稳定性。未特别说明时,我们默认使用 16,384 的码本大小、256的代码维度和 4 个ResBlock作为我们的分词器默认设置。
视觉生成设置。 预期简单的自回归视觉生成方法可以很好地展示我们视觉分词器设计的有效性。具体而言,我们采用基于Llama的架构,其中结合了RoPE、SwiGLU和RMSNorm 技术。我们进一步引入 AdaLN以提升视觉合成质量。类别embedding同时作为起始标记和AdaLN的条件。IBQ的宽度 、深度 和头数 遵循[24,25]中提出的缩放规则, 其公式为:
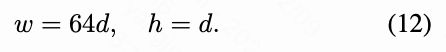
所有模型的训练设置相似:基础学习率为 , 针对每 256 的批量大小, 使用AdamW优化器 [15], 其参数为 , 权重衰减为 , 总批量大小为 768 , 训练 300 到 450 个epoch, 具体取决于模型大小,梯度裁剪为 1.0 ,输入embedding、FFN模块和条件embedding的dropout率为 0.1 。
主要结果
视觉重建。 下表1展示了IBQ与常见视觉分词器的定量重建比较。可以看到,当码本规模扩大时,现有VQ方法的码本使用率显著下降(例如,VQGAN 在1024码本规模下的使用率为44%,而在16,384码本规模下的使用率为5.9%),以及代码维度(例如,LlamaGen 在8维代码下的使用率为97%,而在256维代码下的使用率为0.29%)。因此,实际的表示能力受到码本崩溃的限制。

相比之下,对所有码本embedding和视觉编码器的联合优化确保了它们之间的一致分布,有助于稳定训练具有高利用率的大规模码本和embedding视觉分词器。具体来说,IBQ在16,384码本规模和256代码维度下实现了1.37的rFID,超过了在相同下采样率和码本规模下的其他VQ方法。通过将码本规模增加到262,144,IBQ超越了Open-MAGVIT2,实现了最先进的重建性能(1.00 rFID)。我们还在下图4中与几种具有代表性的VQ方法进行了定性比较。IBQ在复杂场景如面部和字符上表现出更好的视觉合理性。

视觉生成。 在下表7中,我们将IBQ与其他生成模型进行比较,包括扩散模型、AR模型以及AR模型的变体(VAR和MAR)在类别条件图像生成任务上的表现。借助IBQ强大的视觉分词器,我们的模型在扩大模型规模时(从300M到2.1B)表现出持续的改进,并在不同规模的模型下超越了所有之前的基础自回归模型。此外,IBQ优于基于扩散的模型DiT,并在AR模型变体中取得了可比的结果。这些AR模型变体专注于第二阶段transformer的架构设计,而我们的工作则致力于第一阶段更好的视觉分词器。因此,我们相信,借助我们更强大的分词器,AR模型及其变体可以进一步提升。

扩大 IBQ
现有的 VQ 方法在扩展时因码本崩溃而遇到困难。例如,当将 LlamaGen的代码维度从 8 增加到 256 时,其使用率和 rFID 显著下降(97% → 0.29%,2.19 rFID → 9.21 rFID),如上表 1 所示。这是由于训练期间的部分更新逐渐扩大了未激活代码与编码特征之间的分布差距。IBQ 在三个方面显示出有希望的扩展能力:
-
码本大小:如下表 4 所示,随着码本大小从 1024 扩大到 16,384,重建质量显著提高。此外,IBQ 即使在使用 262,144 个代码进行训练时,也能实现高码本利用率和视觉效果的一致提升。

-
模型大小:下表 6 显示,通过在编码器和解码器中扩展 ResBlock 的数量,可以保证重建性能的提升。

-
代码维度:有趣的是,观察到在扩展代码维度时,码本使用率显著增加。我们假设低维代码辨别力较弱,类似的代码往往会聚集在一起。这表明在我们的全局更新策略下,具有代表性的代码更有可能被选择。相比之下,高维embedding的代码在表示空间中是高度信息化的,因为它们在表示空间中是相互稀疏的。因此,这些代码在训练过程中可以被均匀选择,从而确保高利用率和更好的性能。通过以上因素,我们实现了一个拥有 262,144 个码本大小和 256 维度的超大码本,并且具有高码本使用率(84%),实现了最先进的重建性能(1.00 rFID)。为了更好地说明扩展特性,我们还在下图 5 中提供了可视化。

消融实验
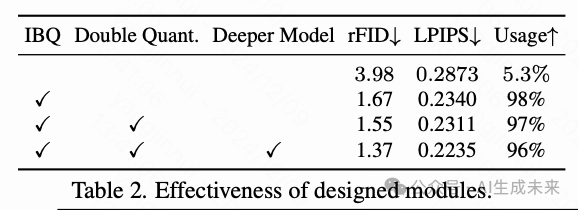
关键设计。 为了验证我们方法的有效性,对几个关键设计进行了消融研究,如下表2所示。重新实现的VQGAN性能为3.98 rFID,码本利用率为5.3%。与之前的方法不同,将VQ替换为IBQ后,通过使所有代码可微分,实现了编码特征与整个码本之间的一致分布,从而显著提高了码本的使用率(从5.3%提高到98%)和重建质量(从3.98 rFID提高到1.67 rFID)。通过引入双重量化损失来迫使选择的代码embedding和编码视觉特征相互靠近,IBQ保证了更精确的量化。按照MAGVIT-v2 的做法,我们扩大了模型规模以提高紧凑性,重建性能也相应得到了改善。
与LFQ的比较。 为了进行公平的比较,采用了具有16,384个代码的LFQ,并用我们的基础Transformer架构替换了其不对称的token分解。我们在下表5中比较了LFQ在重建和生成方面的表现,我们提出的IBQ表现更好,这表明增加代码维度可以提高视觉tokenizer的重建能力,并进一步提升视觉生成。

结论
在本文中,我们识别出了当前向量量化(VQ)方法中部分更新策略导致的tokenizer扩展瓶颈,这种策略逐渐加大了编码特征与未激活代码之间的分布差距,最终导致码本崩溃。为了解决这一挑战,提出了一种简单而有效的向量量化方法,称为索引反向传播量化(IBQ),用于可扩展的tokenizer训练。该方法通过在视觉特征与所有码本embedding之间的分类分布上应用直通估计器来更新所有代码,从而保持整个码本与编码特征之间的一致分布。ImageNet上的实验表明,IBQ实现了高利用率的大规模视觉tokenizer,在重建(1.00 rFID)和生成(2.05 gFID)方面的性能有所提高,验证了我们方法的可扩展性和有效性。
参考文献
[1] Taming Scalable Visual Tokenizer for Autoregressive Image Generation

(文:极市干货)