

Datawhale干货
作者:王晓亮,Datawhale成员
目录
作为一个程序员,我一直期望可以追踪 GitHub 的 Trending 项目,但是每次都要去 GitHub 上手动查看并挨个浏览 GitHub 仓库内容,非常麻烦。
在接触到 n8n 之后,我萌生一个想法,利用 n8n 自动化进行 GitHub Trending 项目的追踪, 并生成邮件通知,甚至自动化发布到我的博客站点中。通过周末两天时间完成该工作流的搭建,并成功运行。以下是 n8n 相关介绍及工作流搭建过程,分享给大家。
n8n 初识:一个自动化超级英雄

n8n 是 nodemation 的简称,是一个开源的、高度可扩展的工作流自动化工具。GitHub 仓库为 https://github.com/n8n-io/n8n ,当前 Star 数已经达到 108K。它允许你通过一个直观的可视化界面,将不同的应用、服务和数据连接起来,创建复杂的自动化流程,从而提升效率、减少重复性工作。
核心特点:
-
可视化工作流编辑器:n8n 提供一个直观的拖拽式界面,让你可以轻松地构建和管理复杂的自动化流程,即使是没有任何编程背景的用户也能快速上手。
-
丰富的节点库:拥有庞大的预构建节点库,支持连接几乎所有主流的应用和服务,包括各种 API、数据库(如 Supabase)、SaaS 平台(如 GitHub、Slack)、以及自定义 Webhooks 等。这使得数据流转和任务协同变得异常简单。
-
高度灵活性:支持各种复杂的逻辑控制,如条件分支(if/else)、循环(loop)、并行执行等, 你可以根据业务需求构建出高度定制化的自动化流程。
-
自托管/云服务选项:n8n 提供极大的部署灵活性。你可以选择将其私有部署在自己的服务器上, 完全掌控数据安全和隐私;同时,n8n 也提供云服务选项,方便快速启动和管理。
-
低代码/无代码特性:n8n 巧妙地平衡了易用性和功能性。对于非技术人员,它提供无代码的拖拽操作,实现快速自动化;而对于开发者,它允许在工作流中嵌入自定义代码(如 JavaScript),实现更高级、更个性化的功能扩展。
相较于市面上其他自动化工具,n8n 的核心优势在于其开源的本质和卓越的可扩展性。开源意味着透明、社区驱动的快速发展,并且可以根据你的具体需求进行深度定制。而其强大的节点系统和灵活的编程能力, 使得它不仅能满足日常的简单自动化需求,更能应对复杂的企业级工作流挑战,真正成为“自动化超级英雄”。
部署 n8n 环境:开启自动化之旅
n8n 提供多种自托管部署方式,且官方提供参考仓库 https://github.com/n8n-io/n8n-hosting 。
这里我使用 docker compose 部署,同时为了后期 OAuth 相关认证支持,还需要准备一个子域名用作 n8n 服务的域名。需提前将域名解析指向 n8n 服务的公网地址。
mkdir n8n-compose && cd n8n-composedocker-compose.yml 与 init-data.sh.env(更改下列配置项为实际值)POSTGRES_USER=changeUser
POSTGRES_PASSWORD=changePassword
POSTGRES_DB=n8n
POSTGRES_NON_ROOT_USER=changeUser
POSTGRES_NON_ROOT_PASSWORD=changePassword
ENCRYPTION_KEY=changeEncryptionKey
N8N_EDITOR_BASE_URL=https://n8n.example.com
WEBHOOK_URL=https://n8n.example.comdiff --git a/docker-compose/withPostgresAndWorker/docker-compose.yml b/docker-compose/withPostgresAndWorker/docker-compose.yml
index b5b2de6..2d8cdfc 100644
--- a/docker-compose/withPostgresAndWorker/docker-compose.yml
+++ b/docker-compose/withPostgresAndWorker/docker-compose.yml
@@ -19,6 +19,8 @@ x-shared: &shared
- QUEUE_BULL_REDIS_HOST=redis
- QUEUE_HEALTH_CHECK_ACTIVE=true
- N8N_ENCRYPTION_KEY=${ENCRYPTION_KEY}
+ - N8N_EDITOR_BASE_URL=${N8N_EDITOR_BASE_URL}
+ - WEBHOOK_URL=${WEBHOOK_URL}
links:
- postgres
- redisdocker-compose up -ddocker-compose ps,可以得到如下输出NAME COMMAND SERVICE STATUS PORTSn8n-compose-n8n-1 "tini -- /docker-ent…" n8n running 0.0.0.0:5678->5678/tcp, :::5678->5678/tcpn8n-compose-n8n-worker-1 "tini -- /docker-ent…" n8n-worker running 5678/tcpn8n-compose-postgres-1 "docker-entrypoint.s…" postgres running (healthy) 5432/tcpn8n-compose-redis-1 "docker-entrypoint.s…" redis running (healthy) 6379/tcpn8n.example.com
7. 配置反向代理服务,如 Caddyserver 可以添加如下配置至 /etc/caddy/Caddyfile
n8n.example.com {
reverse_proxy localhost:5678
}
经过如上配置,访问
https://n8n.example.com 就可以访问 n8n 的 UI 了。第一次访问需要配置管理员账号密码。
实现 GitHub Trending 每日追踪
接下来到了工作流搭建过程。先规划整体工作流运转流程:
-
定时获取 GitHub Trending 项目列表并存储 -
基于存储的项目列表,选择合适的项目进行 git 仓库信息获取,主要为项目 README 内容等 -
使用 LLM 对获取的信息进行文本总结,输出 Markdown 格式内容 -
将输出内容进行邮件发送或者存储至博客系统中
数据存储我使用 Supabase 的数据库,博客系统为我个人博客主站,使用 hugo 搭建并由 GitHub Actions 自动部署。整个过程中使用的核心 node 有
-
HTTP Request(https://docs.n8n.io/integrations/builtin/core-nodes/n8n-nodes-base.httprequest/) -
GitHub(https://docs.n8n.io/integrations/builtin/app-nodes/n8n-nodes-base.github/) -
Supabase(https://docs.n8n.io/integrations/builtin/app-nodes/n8n-nodes-base.supabase/) -
Code(https://docs.n8n.io/integrations/builtin/core-nodes/n8n-nodes-base.code/) -
Basic LLM Chain(https://docs.n8n.io/integrations/builtin/cluster-nodes/root-nodes/n8n-nodes-langchain.chainllm/)
获取 GitHub Trending 项目列表与信息总结、内容发布有不同的时间周期,我将其分为两个不同的工作流。
工作流 1 – 获取 GitHub Trending 项目列表并存储

由于 GitHub Trending 项目列表是动态的,且 GitHub 官方不提供 API。为此我写了一个 Python 脚本获取 GitHub Trending 项目列表,并包装成本地服务提供 API 供工作流使用,当然绝大部分代码由 LLM 生成。该服务已经开源,地址为https://github.com/tomowang/github-trending 。
为了让 n8n 节点可以访问该服务,我们需要将其运行在 n8n docker compose 对应的 network 中, 使用如下命令启动服务(其中n8n-compose_default为 n8n 所在的 docker-compose 的网络名称):
docker run -d \ -p 18000:8000 \ --name github-trending \ --restart always \ --network n8n-compose_default \ ghcr.io/tomowang/github-trending:latest在 n8n 中使用 HTTP Request 节点访问本地服务,配置如下(注意其中的 URL 部分,使用 docker 网络中的 service 作为域名):
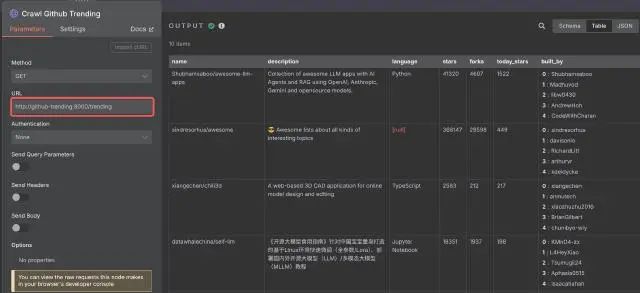
后续 Code 节点填充额外的时间、当前列表排名等信息,最后数据使用 Supabase 节点进行存储。Supabase 表结构如下:
create table public.trending_repos (
id bigint generated by default as identity not null,
name character varying not null default ''::character varying,
description text null default ''::text,
language character varying null default ''::charactervarying,
stars integer null,
forks integer null,
today_stars integer null,
built_by text[] null,
date timestamp without time zone null,
rank smallint null,
constraint trending_repos_pkey primarykey(id)
)TABLESPACEpg_default;使用 Supabase 需要我们添加 Supabase 的认证信息
-
获取 Supabase Project URL 信息:Project Settings -> Data API -> Project URL 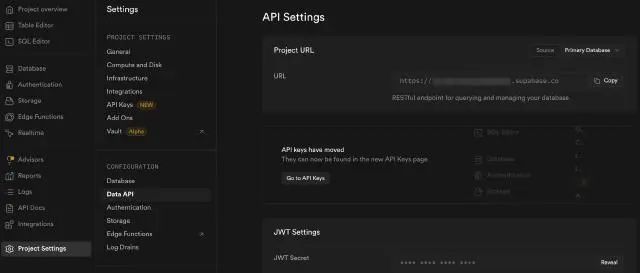
-
获取 Supabase Project API Key 信息:Project Settings -> API Keys -> service_role 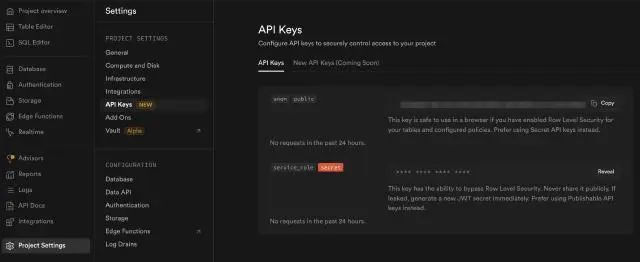
详细参考官方文档:
https://docs.n8n.io/integrations/builtin/credentials/supabase/ 。
运行工作流,我们可以在 Supabase 控制台看到数据
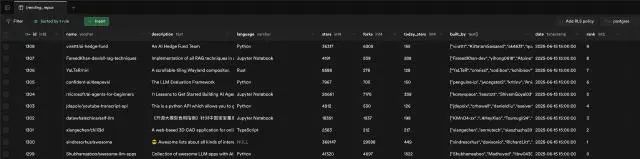
至此该工作流就创建完成了,我们可以将工作流状态设置为 active,通过定时触发器,每小时获取获取一次数据并进行存储,作为后续工作流的数据源。
工作流 2 – GitHub Trending 项目 AI 总结与自动化发布
有了每小时的 GitHub Trending 项目列表数据,我们就可以开始进行项目信息总结了。我们需要规划下整个工作流运转流程,有几个需求需要提前梳理:
-
由于我们每小时抓取一次 GitHub Trending 项目列表,因此我们需要一些策略来挑选我们最终用 AI 进行总结项目 -
对于已经总结以及推送过的项目,需要避免重复推送 -
项目的信息需要从 GitHub 获取,特别是项目的 README 信息
关于第二点,存储已经推送过的项目,我们同样可以使用Supabase的数据库进行存储,表结构如下:
create table public.pushed_repos (
id integer generated by default as identity not null,
pushed_at timestamp with time zone not null default now(),
name character varying not null,
constraint pushed_repos_pkey primary key(id)
) TABLESPACEpg_default;所以整体流程大概如下:
-
从之前存储的 Supabase 中获取项目列表 -
剔除其中已经推送的项目 -
通过一定策略挑选需要推送的项目 -
获取项目信息,主要为 README -
使用大语言模型针,结合项目信息以及 README 信息,进行总结 -
使用 Email 节点推送总结 -
将总结通过 GitHub 节点发布到博客系统 -
将推送的项目信息存储到 Supabase 中
完成后的 n8n 工作流如下:
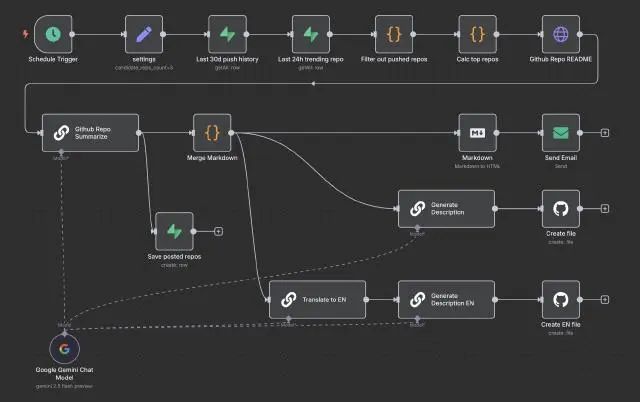
接下来我们对其中的一些关键节点及流程进行说明。
Code Node & Built-in methods and variables
首先是我们的第一个代码节点Filter out pushed repos
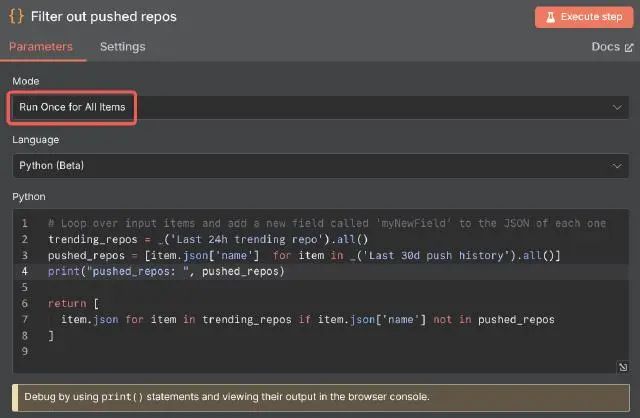
n8n 支持两种语言的代码节点,JavaScript & Python,其中 Python 使用Pyodide 提供支持。在示例中,我们使用 Python 节点。在 n8n 中,节点默认对工作流中传递的数据进行 循环调用(https://docs.n8n.io/flow-logic/looping/)。但是我们期望针对获取到的 GitHub 项目信息进行统一处理,所以在示例中的代码节点我们配置其运行模式为Run Once for All Items。
官方文档提示:The Code node takes longer to process Python than JavaScript. This is due to the extra compilation steps. 所以如果追求极致的性能,可以尽量使用 JavaScript 代码节点
在代码中,我们需要使用内置的方法及变量来获取上游节点传递的数据。JavaScript 以及 Python 使用不同的命名方式进行变量获取。
|
|
|
|
|---|---|---|
$input.item |
_input.item |
|
$input.all() |
_input.all() |
|
$json |
_json |
$input.item.json
_input.item.json 的快速访问 |
$("<node-name>").all() |
_("<node-name>").all() |
|
当我们对数据进行处理后,需要返回数据给下游节点进行后续处理。在 n8n 中,节点中的数据传输使用 对象数组(https://docs.n8n.io/data/data-structure/) ,其结构如下
[
{
// For most data:
// Wrap each item in another object, with the key 'json'
"json":{
// Example data
"apple":"beets",
"carrot":{
"dill":1
}
},
// For binary data:
// Wrap each item in another object, with the key 'binary'
"binary":{
// Example data
"apple-picture":{
"data":"....",// Base64 encoded binary data (required)
"mimeType":"image/png",// Best practice to set if possible (optional)
"fileExtension":"png",// Best practice to set if possible (optional)
"fileName":"example.png"// Best practice to set if possible (optional)
}
}
}
]所有在示例的代码节点中,最后返回过滤后的item.json数组,完整的代码如下:
# Loop over input items and add a new field called 'myNewField' to the JSON of each one
trending_repos=_('Last 24h trending repo').all()
pushed_repos=[item.json['name']foritemin_('Last 30d push history').all()]
print("pushed_repos: ",pushed_repos)
return[
item.jsonforitemintrending_reposifitem.json['name']notinpushed_repos
]另外,如果需要对代码进行调试,可以使用console.log 及 print(),相关的调试结果会输出在浏览器的调试控制台中。
1. HTTP Request Node
由于原生的 GitHub 节点不支持获取项目的 README 信息,我们使用 HTTP Request 节点来进行自定义 API 调用,这同样也适用于其他提供 HTTP 接口但是没有节点支持的系统。
GitHub 仓库的 README 信息可以通过GET /repos/{owner}/{repo}/readme API 获取,具体 API 文档可以参考:https://docs.github.com/en/rest/repos/contents?apiVersion=2022-11-28#get-a-repository-readme。
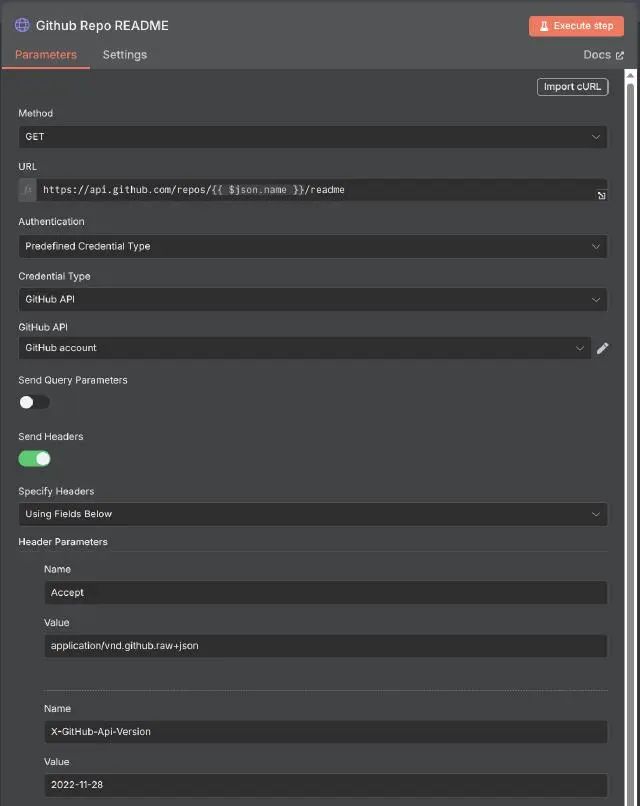
在示例中,我们使用 GET 方法,并设置 Accept 为application/vnd.github.raw+json,以获取原始的 README 内容。
对于请求的 URL,我们使用{{ $json.name }}来获取上游节点传递的项目名称信息(在这种情况下只支持 JavaScript 代码,并使用{{ }}运行 表达式(https://docs.n8n.io/code/expressions/ )。
对于请求的认证 Authentication 部分,n8n 建议在可用时使用预定义凭证类型选项。这里我们通过预定义凭证类型 GitHub API 来进行认证。
2. LLM Chain Node
n8n 提供丰富的 LLM 相关的节点,隶属于集群节点 Cluster Nodes(https://docs.n8n.io/integrations/builtin/cluster-nodes/), 集群节点是一起工作的节点组,包含一个根节点以及多个子节点。
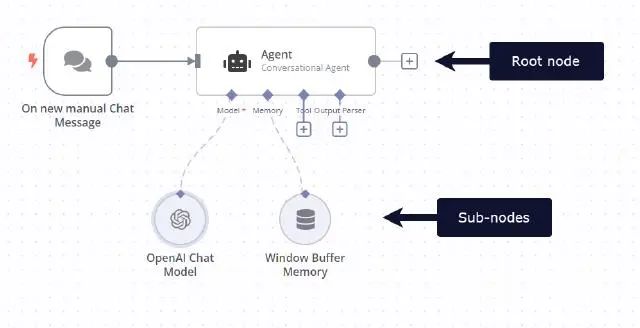
在示例中,我们使用Basic LLM Chain节点对项目信息进行总结,其包含一个根节点以及一个大模型子节点。
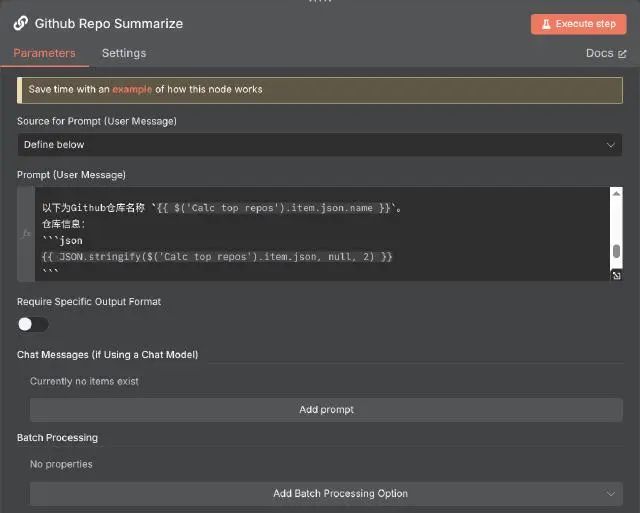
对于提示词,我们使用预设模式。在提示词中,通过表达式获取之前节点获取的 GitHub 项目信息以及 README 信息,提示词中相关片段如下:
以下为Github仓库名称 `{{ $('Calc top repos').item.json.name }}`。
仓库信息:
```json
{{ JSON.stringify($('Calc top repos').item.json, null, 2) }}
```
仓库原始README信息:
```markdown
{{ $json.data }}
```Basic LLM Chain 需要绑定一个大语言模型,n8n 提供了多个大语言模型节点,如 OpenAI、Hugging Face 等。
示例中我们使用 Google Gemini Chat Model,选择该类型节点后,添加对应的鉴权信息(API Key 可以通过 https://aistudio.google.com/app/apikey 创建),并选择模型版本, 如 gemini-2.5-flash-preview-05-20,这样 Basic LLM Chain 节点就具有了大模型能力,能够根据提示词信息进行文本生成工作。
展望
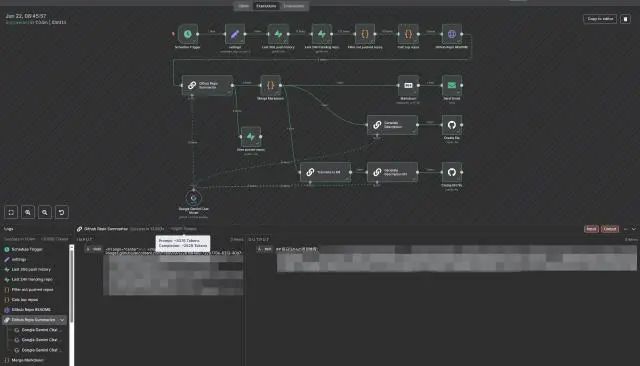
基于上述的工作流,我们能够实现 GitHub 项目信息自动抓取、过滤、总结,并自动发送邮件以及发布至博客中。通过 Execution 面板,我们可以观测工作流的运转过程,并看到每个节点实际的输入输出数据,甚至预估的 Token 数。
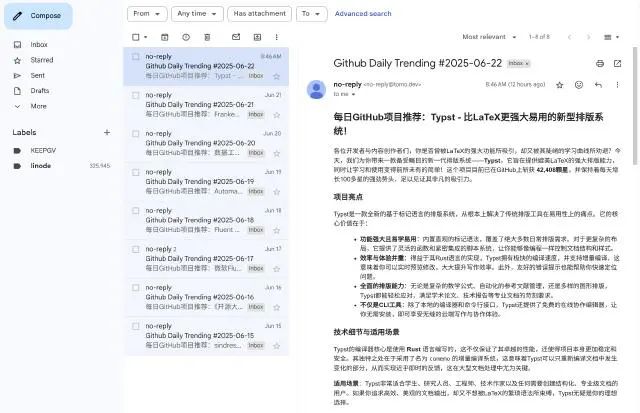
最终自动发布的博客地址为 https://tomo.dev/aigc/ ,自动发送的邮件如下:
该工作流展示了 n8n 强大的集成能力,以及灵活的节点配置方式。通过类似的方法,我们可以拓展更多数据源获取、处理以及大语言模型解读等场景,实现更多自动化工作。
最后附上工作流文件,方便大家参考。
https://tomo.dev/posts/n8n-workflow-for-daily-github-trending-auto-posting/

(文:Datawhale)