

2个多月前,我给Kimi的朋友提了条建议:将Kimi探索版重新“捡”起来。

老Kimi人应该知道,输入“/”可以调用Kimi探索版,擅长解复杂的搜索问题。kimi探索版,我认为是世界上第一个DeepSearch(深度搜索),比“御三家”的Gemini、ChatGPT和Claude都要早。
最近,我的反馈有结果了。
上周五深夜(AI圈咋都喜欢熬夜 ),Kimi正式推出了他们的第一个Agent——Kimi-Researcher(深度研究),最近正开启小范围内测。
),Kimi正式推出了他们的第一个Agent——Kimi-Researcher(深度研究),最近正开启小范围内测。
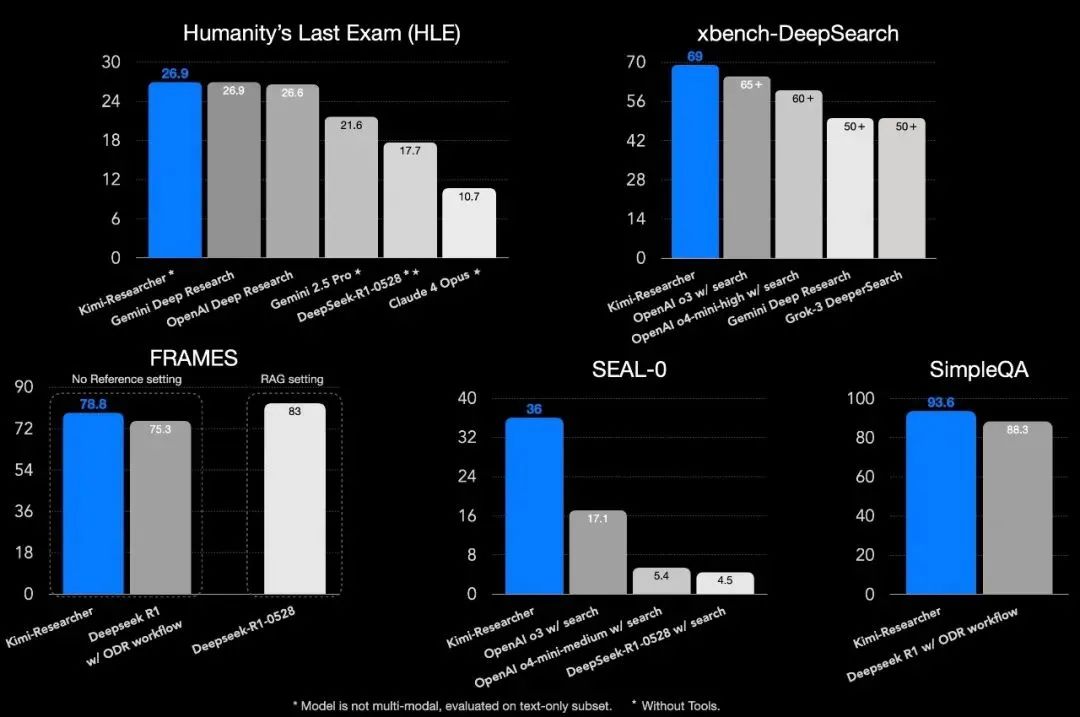
无论是红杉中国的xbengch还是Humanity’s Last Exam,Kimi-Researcher都表现优秀。
据介绍,这是一款基于端到端自主强化学习(end-to-end agentic RL)技术训练的Agent模型,专为深度研究任务而生。
目前,所有人可以在官网kimi.com申请体验。

一手实测Kimi-Researcher
收到kimi的内测邀请,这几天,我接连跑了10多个case。所有任务,它都会交付2样东西给我。
一份信息详实、可溯源的深度研究报告。
一个可交互、可分享的动态可视化网页。
下面,给大家看几个我跑的case。
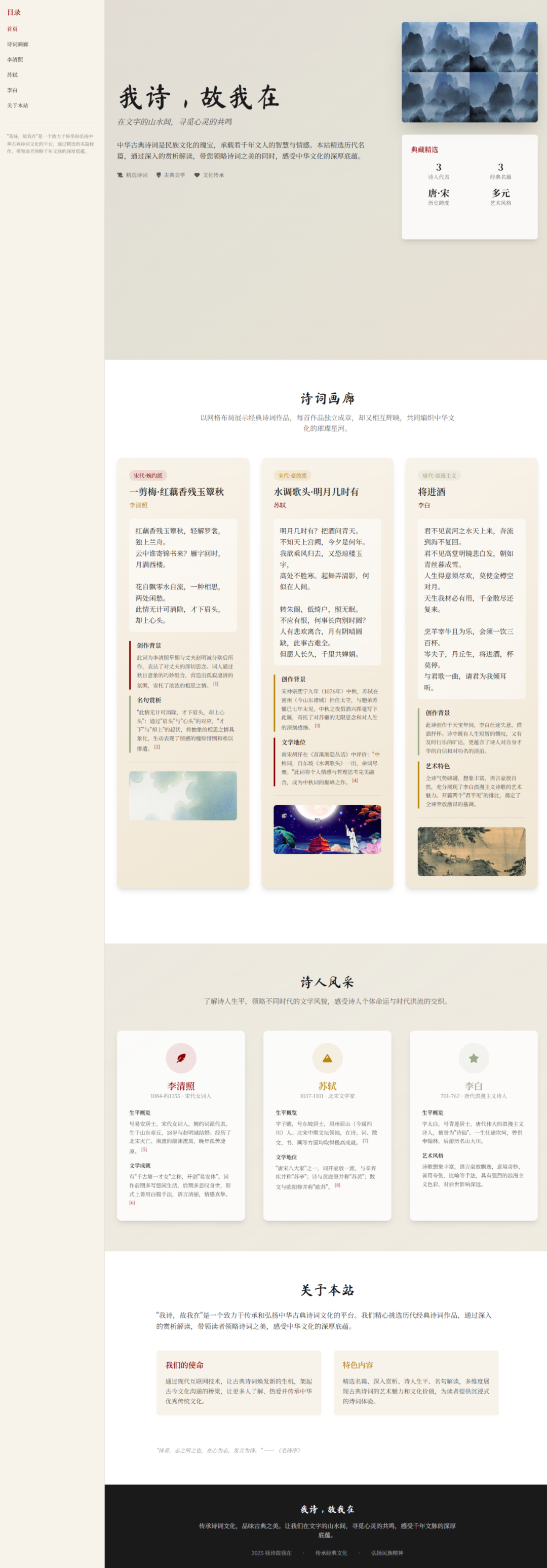
1)我诗故我在
Prompt:帮我生成一个叫“我诗,故我在”的网站,将多位诗人的经典诗词作品并列展示,包括作品介绍、作品插画、作者介绍和名句赏析,网页要有艺术感。
(可上下滑动,查看全图)
完成度挺高。采用了类似画廊的布局,来展示每个作品,有诗词、作者、插画和创作背景。
整体vi色采用的是传统色,如墨黑、朱红、茶褐、赭石等,背景则用浅米黄、月白或仿古宣纸的色调,字体用具有书法韵味的行书和宋体,整体都很搭,有一种简洁而内敛的中国传统美。
尤其是色彩和字体这块,我很喜欢。
2)《2001太空漫游》电影赏析
Prompt:帮我生成一个《2001太空漫游》电影赏析的网页。

(可上下滑动,查看全图)
这个交付,我是真喜欢,风格太对味了。深蓝色打底,标题用粉黄搭配,非常符合《2001太空漫游》的审美。
内容方面,结构化的介绍了电影、剧情、制作背景、电影风格、后世影响和获奖情况等,它还用Mermaid代码生成了剧情流程图。
体验链接:
https://www.kimi.com/preview/d1d9u5cc75r8i3i3h450?blockId=70
同类主题,我还跑了一个case。
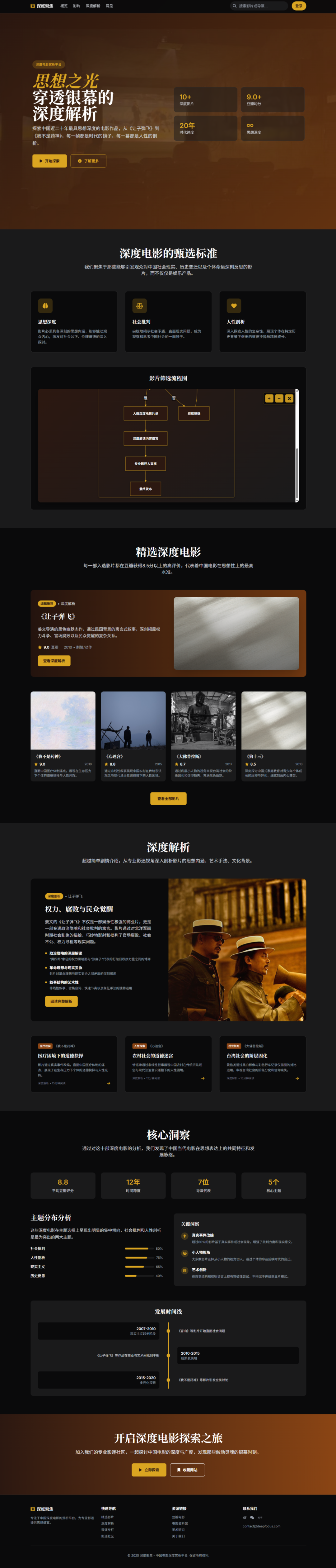
Prompt:整理中国近 20 年来最有思想深度的 10 部电影,创建一个电影赏析网页。
(可上下滑动,查看全图)
难度在于,Prompt没有给任何配色或设计提示,要靠模型自己理解内容和视觉风格。
但结果却非常惊艳,跟豆瓣网的年度电影专题,完全不相上下。不得不说,Kimi模型的编程能力,真的被大大低估了。
3)10款Agent分析
Prompt:对这10款AI Agent(Manus、Genspark、Lovart、Flowith Neo、MiniMax Agent、Skywork、AutoGLM、心响、扣子空间、Medeo)进行深度分析,按照下面结构写一份研究报告:
1、Agent的定义与技术架构
2、Agent与DeepSearch、DeepResearch的区别;
3、10款Agent简介(上线时间、研发公司和产品定位等);
4、10款Agent功能对比分析;
5、10款Agent定价、用户数量及收入情况;
6、舆论对10款Agent的评价情况;
7、一句话总结10款Agent,并附上使用网址;
注意:1.只搜索2025年的信息;2.为了让搜索结果精准权威,请使用高级搜索技巧生成搜索关键词。

(可上下滑动,查看全部网页)

(可上下滑动,查看完整报告)
这个任务的难点在于:产品名、buzz word是真的多,大模型在处理这类任务时,很难不出现幻觉。
很多Agent在遇到我这个任务时,基本都会GG。要么是对各款Agent的介绍混乱,要么是无法完成7个任务。
Kimi是少有的能够完成这个任务的Agent。
体验链接:
https://www.kimi.com/preview/d1d9ubfhq49jqm5rqi5g?blockId=108
4)《西游记》妖怪图鉴
Prompt:搭建一个网站,对《西游记》里的20个妖怪进行交互演示,要有图片介绍,也有文字说明。
妖怪和介绍,全对。有点缺陷的是,没有给妖怪配图。
5)《长安的荔枝》文化品析
Prompt:制作一个关于《长安的荔枝》文化解析的网站,用于课堂展示,尽量通俗。

(可上下滑动,查看完整报告)
文化细节解构到位,重点和细节都在,让人秒懂那段历史。
有意思的是,它的所有引用都内嵌在正文中,点击即可跳转到内容源,便于随时验证与追溯。
6)多平台热搜聚合播客
Prompt:汇总今天抖音、B站、知乎、微博、微信指数上的前5条热搜内容,生成一个播客网页。
难度在于,Kimi是真的去搜了这5个平台的内容。全部是用的browser-use(浏览器使用)工具,这样大大确保了信息的真实性。
7)川西5日游攻略
Prompt:帮我规划一份川西5日自驾游的行程,电车,住宿尽量低海拔。

(可上下滑动,查看全部网页)

(可上下滑动,查看完整报告)
我把这个结果给了旅行社的朋友,她说这份攻略的含金量很高,差不多可以直接拿着它出发。

8)Perplexity收购
Prompt:整理“收购Perplexity”的信息,梳理Perplexity的发展历程,生成一个深色主题的网页。中文版:
英文版:

(可上下滑动,查看全图)
这也是一个搜索量很大的任务,很考验模型的检索质量。从结果来看,Kimi的中英文检索能力都很高。
它是怎么确保检索质量的呢?在它的思考过程中,我看到了一个关键点:交叉验证。
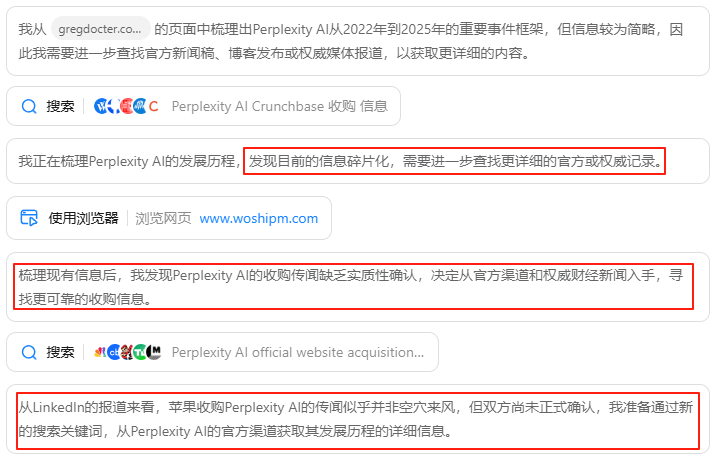
当面对互相矛盾的信息来源时,它会尝试提出假设、反复比对,并主动修正推理路径。即使是看似直接的问题,它也会倾向于多查几遍,做交叉验证。

拆解Kimi-Researcher
从实测来看:Kimi-Researcher很擅长搜索,几乎没什么幻觉,交付的研究报告质量很高,而且所有引用均支持溯源。
我们知道,国内的互联网内容环境很糟糕。好的内容封闭(比如公众号、小红书),无法被检索;而可以被公开检索的平台(如百家号、csdn、搜狐、新浪等),又充斥着大量的劣质信息(营销号文章实在太多)。
国内的AI产品,无论是AI Search还是AI Agent要想从这种背景下脱颖而出,非常不易。而Kimi的Search能力,我认为一直都做得不错。
Kimi-Researcher,则进一步将它的Search能力做到更好。
它是怎么做的呢?有四个关键点:
-
1.澄清问题(clarification)。用户发送任务prompt后,Kimi会主动反问,与用户确认细节,构建更清晰的问题空间。

-
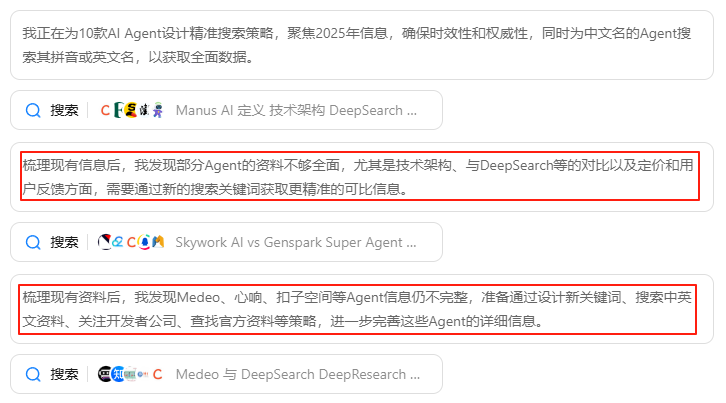
2.深入思考。每个任务,Kimi会进行20步以上的推理,自主梳理并解决需求。
-
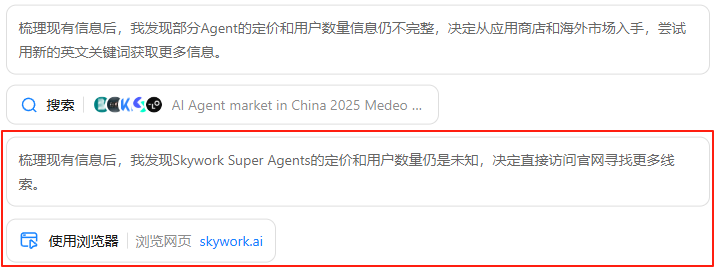
3.主动搜索。每个任务,Kimi会规划一套高级关键词来进行搜索,如果没有搜到想要的结果,它会变换思路,再次主动搜索。
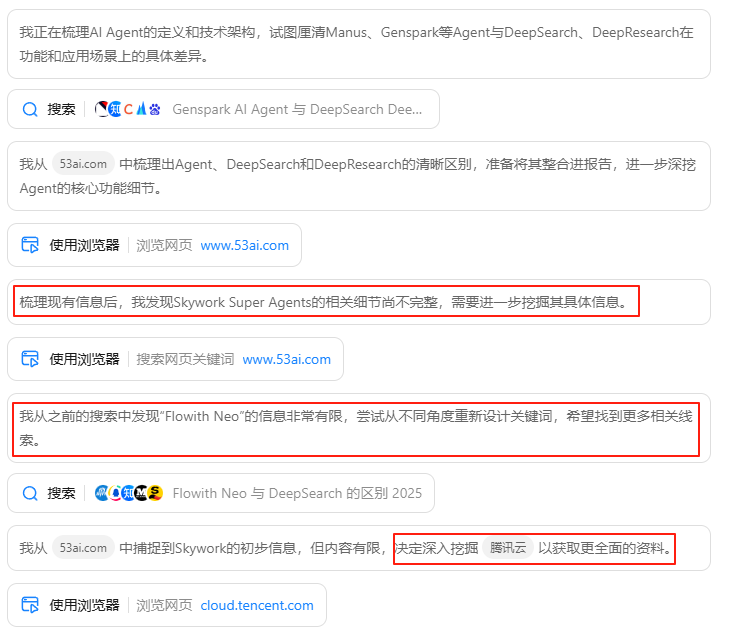
-
对于搜回来的信息,它会自主判断并筛选出信息质量最高的前3.2%内容,剔除冗余、低质信息。
-
4.调用工具。模型会自主调用浏览器进行搜索,解决内容壁垒的问题。
最终,交付给用户的,是一份高质量的深度研究报告。

以及一个可交互、可分享的可视化网页。

在网站审美和效果这块,Kimi-Researcher一点不弱,基本处于国内第一梯队。
现在,有了Kimi-Researcher,那些被轻易略过的话题、难以解答的难题和偏门小众的问题,都值得被重新看待一次。

写在最后
在春节R1火了后,Kimi遭到不少非议。“去年叫人家小甜甜,现在喊我牛夫人?”
对此,Kimi果断调整了激进的市场投放策略,转而一门心思地扑向了技术研发。

过去这3个月里,Kimi发了很多技术成果:
-
4月,先后发布并开源数学模型Kimina-Prover、视觉模型Kimi-VL,小参数达到SOTA级别;
-
同时,还与财新网合作,补齐财经领域短板。
-
5月,发布并开源音频模型Kimi-Audio,又一款SOTA模型;
-
6月,Kimi悄悄上线学术搜索,还统一了域名:kimi.com;
-
上周一,发布并开源编程模型Kimi-Dev,Huggingface下载量近万;
-
上周五,推出第一款Agent模型Kimi-Researcher,并将继续开源。
从第一代Kimi到Kimi-Researcher,那个懂用户、有人味儿的kimi一直都没有离开我们,而是在长大。
成长,注定不会一帆风顺,反而磕磕绊绊的旅程才是真。
我知道,我的朋友们,亲爱的、可爱的你,很多都是因为Kimi,我们第一次在这里结识。
谢谢你一直陪伴着我们,也谢谢Kimi给我们带来的这趟神奇之旅。
AI未来路还很长,让我们一起去探索,去创造吧。
(文:沃垠AI)