


作者:李栋 & 椰椰
编辑:李宝珠
转载请联系本公众号获得授权,并标明来源
近日,清华长庚医院医学数据科学中心主任李栋教授在 2025 北京智源大会中,就「智慧医疗时代下如何应用医疗数据开展创新研究」进行了专题分享,介绍了大模型在智慧医疗时代带来的创新。本文为李栋教授的分享精华实录。
随着人工智能技术的不断深入成熟,AI 也赋予了医疗领域一场深刻的变革——通过整合多源数据与智能算法,为医疗行业的效率提升、精准诊断都提供了全新解决方案。医疗数据作为大模型的「燃料」,也是医疗决策的核心载体,它的角色至关重要,尤其是在中国医疗体系加速数字化转型的背景下,从数据角度解析医疗模型更是创新的必经途径。
近日,在 2025 北京智源大会中,清华长庚医院医学数据科学中心主任李栋教授在「AI+理工&医学」专题论坛中,以「智慧医疗时代下如何应用医疗数据开展创新研究」为题,结合清华长庚医院的实践经验,从数据角度对大模型的落地模式、技术局限、资源重构、以及应用探索等多个维度进行了分享。

李栋教授演讲现场
HyperAI超神经在不违原意的前提下,对李栋教授的深度分享进行了整理汇总,以下为演讲实录。
大模型在医疗场景中的应用与挑战
「本地部署+定制开发+断网使用」模式应用
DeepSeek 作为一款近年来火爆出圈的大模型,它在医疗场景中的适用模式主要有 3 种使用方式:手机端轻量使用模式、云端接入模式,以及「本地部署+定制开发+断网使用」。
在这 3 种接入方式中,「本地部署+定制开发+断网使用」成为实践最优解。云端模式因「数据不能离院」政策限制,无法利用真实数据训练模型,导致其成为「静态模板」;而手机端轻量应用仅能处理简单咨询,无法触及医疗核心需求。「本地部署+定制开发+断网使用」虽能规避数据泄露与污染风险(如外源性幻觉数据混入),但也意味着医院需独立承担高昂的算力成本。
大模型医疗中面临的挑战
在医院落地大模型的过程中,面临着诸多挑战,例如算法硬伤、幻觉问题、算力陷阱、AI 公平性等等。
* 算法硬伤:DeepSeek 之所以备受青睐归因于开源和低价,其依托的「混合专家模式(MoE)」通过拆分神经网络降低算力门槛,却在医疗场景暴露局限性:其一,无法支持多模式会诊,面对复杂病例时「单专家决策」易漏诊;其二,为维持算力会在线随机释放数据,可能导致关键信息(如过敏史、手术史)丢失,埋下诊疗隐患。
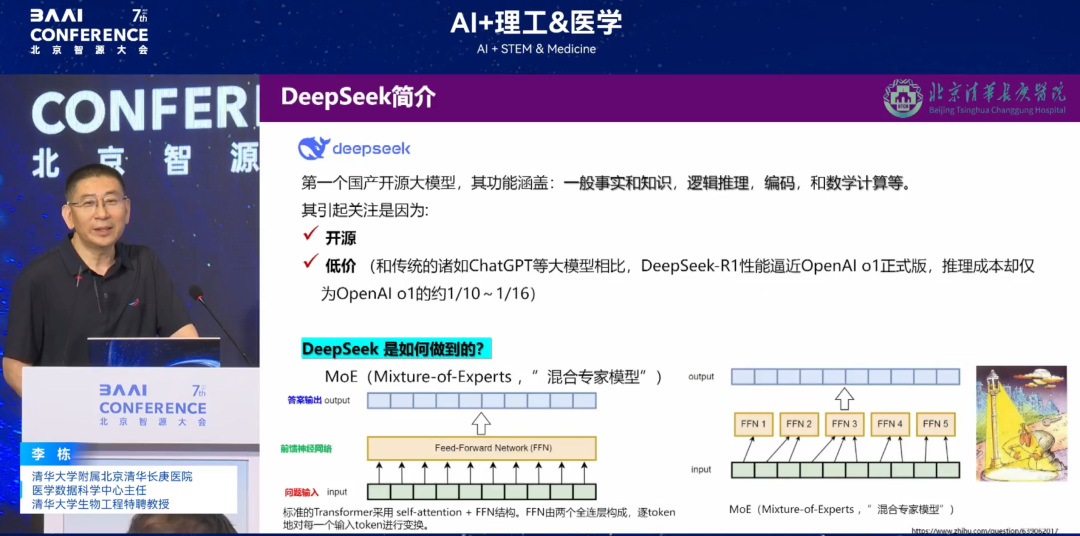
MoE 模式工作流程
* 幻觉问题:DeepSeek 当前版本的幻觉率最高达 50%,虽新版本预计降至 20% 以下,但在医疗场景中仍需警惕。我们通过「三重验证机制」(算法初筛+医生复核+知识库比对)降低风险,但增加了诊疗的时间成本。
* 算力陷阱:小型算力中心的电力消耗已令人咋舌,而训练更复杂的医疗大模型需持续投入。
* AI 公平性:头部医院凭借资源优势垄断先进模型,可能加剧「数字鸿沟」。
医疗评判标准重构:从「三甲标准」到「六要素竞争」
在医疗领域部署大模型,远比想象中复杂。国家卫健委原本希望通过 AI 缓解医疗资源不平衡的问题,但我们部署三个月后发现,结果适得其反 —— 大模型不但没有改善医疗资源不平衡,反而正在重塑三甲医院的竞争格局。
传统三甲医院的评价标准是「名医、设备、硬件环境」,但大模型时代新增了三大门槛:
首先是强大的算力。长庚医院曾以北京市医疗口第二的算力规模,仍难以支撑长期训练。启动小型算力中心时,甚至会导致半栋楼停电;
其次是一流的数据治理工程师。医疗数据涉及电子病历、影像、检验等多类型,需清洗、标注、结构化处理。我们一轮数据治理投入 500 万,效果却不显著;
最后是一流的算法工程师。需根据医疗场景定制算法,解决「黑箱」问题与「幻觉」识别。
智慧医疗:数据驱动的医疗模式革新
如下图所示,自 1950 年以来,每 10 亿美元研发投入获得批准的新药数量几乎每 9 年减少一半,该趋势在 60 年间非常稳定,这一现象被称为制药行业的反摩尔定律(Eroom’s Law)。新药的开发成本越来越高,药物研发面临着严重的生产力危机。
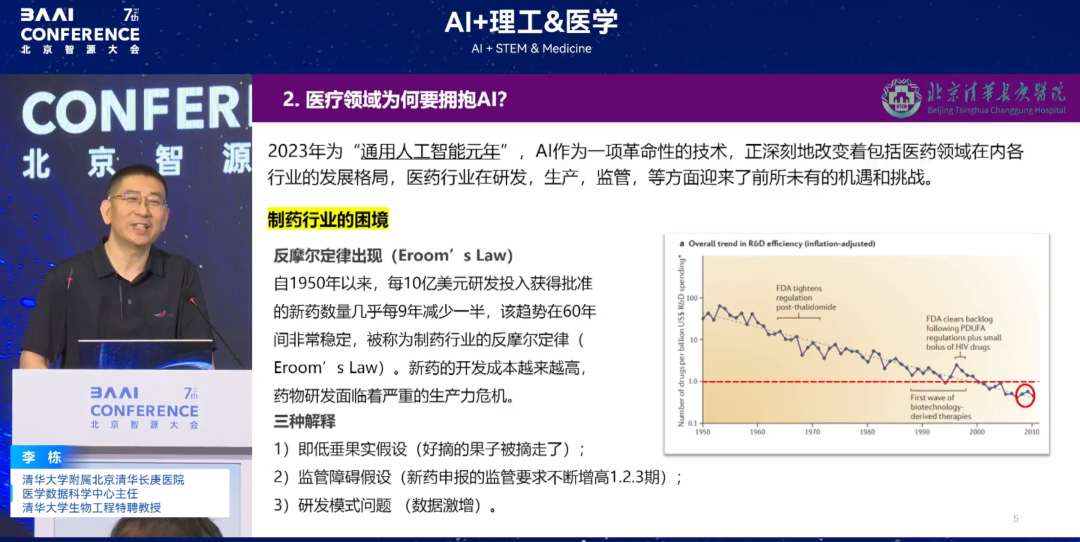
制药行业趋势
并非制药行业,整个医疗行业亦是如此。如下图所示,据 2018 年统计,中国三甲医院数量占全国的 7.63%,但却承担着全国 50.97% 的门诊量。医疗资源分配不均、诊疗效率低、人口老龄化带来的疾病谱变化压力等一系列问题显现,所以在智慧医疗时代,AI 加速医疗变革刻不容缓。
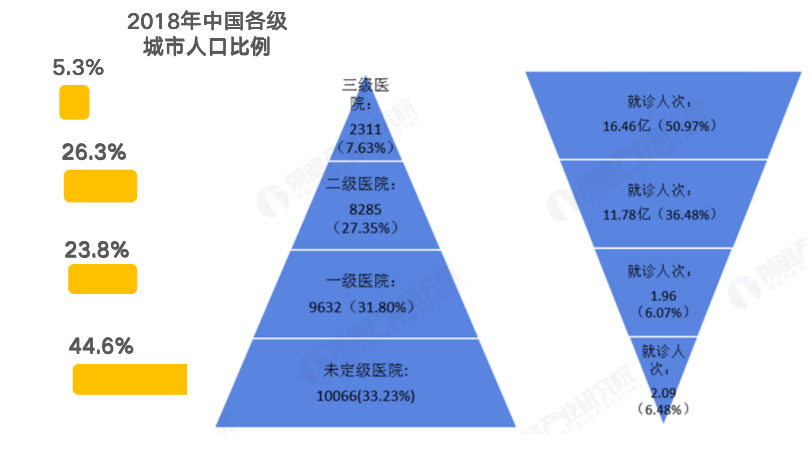
2018 年我国医疗资源与诊断需求情况
(单位:家, 亿人,%),来源:国家卫健委(前瞻产业研究院整理)
传统逻辑回归转向算法为基准
在临床和制药领域拥抱 AI 的趋势下,传统逻辑回归虽能用于临床科研但存在显著不足。以定量评估长期空气污染与心肌纤维化相关性研究为例,传统方法通常收集社会人口学特征、生物标记物及影像学报告(非影像组学),将 PM2.5、PM10 等变量纳入模型,分析其与疾病(如形体纤维化)的相关性。
然而,这类上世纪 70 年代以来的相关分析存在根本性缺陷:医学研究需要探寻因果性,而传统方法仅能发现预设变量的相关性,无法找到未被预先筛选进模型的新危险因素,陷入「鸡与蛋」的循环悖论。此外,传统相关性分析难以处理变量交互作用,通常只能分析两三个因素的交互,无法容纳成百上千的变量,也无法直接接入影像数据。
与之对比,算法分析具备显著优势:既能处理多变量交互,又能纳入海量数据(包括影像),且通过对 Token 的反复训练(运行 1 万次甚至 1 亿次),若某危险因素持续出现,即可视为「因果性」,更接近医学研究所需的因果关系。
医疗 AI 的 4 要素重构:场景优先的资源分配
智慧医疗即利用现代信息技术来改善和提升医疗服务和管理的一种新型医疗模式,旨在提高医疗效率、降低医疗成本,并改善患者的就医体验。其核心基座由大数据、云计算、物联网、AI 构成。
在传统认知中,人工智能的三要素是算法、算力、数据,但在医疗场景中,我们提出「四要素理论」即算法、算力、数据、应用场景,各自所占比重分别为 10%、30%、40%、20%。由于算法国内外差距不大,且大部分开源,所以其在医疗 AI 要素中占比最低;算力方面可通过云算力租赁缓解压力;应用场景作为辅助,提供语义将临床需求转化为模型可理解的「任务」。由此我们发现「数据」才是决定性因素。中国医疗数据量全球领先,但电子化率低,反而成为「未开采的金矿」。预计到 2028 年,全球传统结构化医疗数据的增长将难以满足大模型需求(数据采集始于1550 年),而中国因历史数据未完全信息化,将成为全球医疗研发的核心数据基地。
医疗数据训练的两条途径
许多人对大模型的训练存在疑问,比如是否能直接拿医院数据进行训练,而根据经验,这种做法是不可行的。大模型的训练需要走两条途径。
首先大模型对数据的要求程度远超临床科研。虽然医院若能将数据治理到可用于临床科研的程度已属不易,但大模型训练对数据的要求更高。这是因为大模型虽具备无监督学习能力,但单纯依靠无监督学习如同医生自然成长为主任医师,速度太慢,无法满足实际需求。若想加快训练速度,就需要为其配备医生的决策树,所以不能只是简单地将数据输入大模型,而是要对数据进行更深入的处理和优化。
其次,医院若想直接使用大模型训练,必须走通「库+专科库+专病库+专项库」的数据治理模式。这一模式是在融合了天坛医院等几家医院的实践探索后得出的,被认为是目前比较适合大模型训练的数据模式。这种分层级的数据治理结构,能够更有针对性地为大模型提供高质量、系统化的数据,从而提升大模型训练的效果和效率。

专库建设示例图
心血管与糖尿病研究:数据驱动的创新范本
最后浅谈一下我们基于智慧医疗所做的 2 个研究。
心血管 AI:从「可穿戴设备」到「全心脏模型」
根据 Statista 预计的 2025 年全球智慧医疗市场规模分布显示,心血管领域占据四分之一,是最大的细分市场。数字化贯穿心血管疾病的急性期和康复期始终。
第一代 Apple Watch 推出后,其单导联就实现了超越十二导联的精准预测,能够识别佩戴者的心房颤动(AFib)及其他类型的心律不齐,实现了基层医疗创新。基于这一启发,我们团队提出猜想「既然基于可穿戴设备的心电图(ECG)波形可以早期预测心律失常,是否其他没有 ECG 功能的可穿戴设备仅通过心率也可达到同样效果?」经过一系列验证,我们发现其他设备也能达到同样效果,且准确率高达 99.67%。我们团队收集了普通运动手环的 24 小时内每分钟心跳次数来预测心率失常时长。
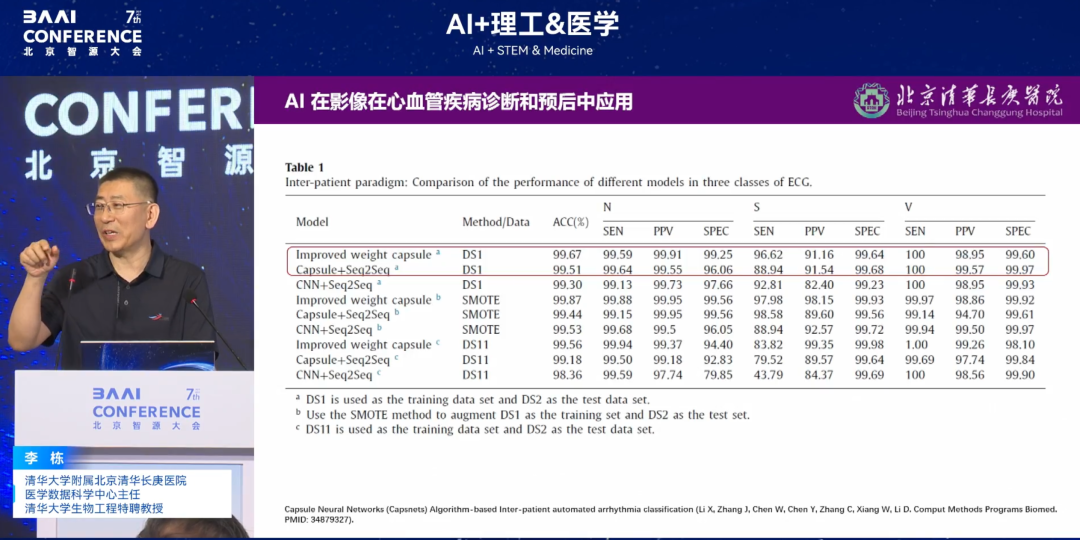
不同模型基于 3 种 ECG 的对比
更进一步,我们提出了第二个猜想「除了 ECG 波形和心率之外可以早期预测心律失常,心脏的 4 个腔室的收缩/舒张是否参与了心律失常,如果有,是否可以预测?」经过我们再次验证,整合了心脏血管、神经、肌肉等多维度数据的「全心脏模型」,可通过算法「打包」心脏。最终结果表明,整合所有心脏功能数据预测心律失常风险,可实现最长 15 年的发病风险精确预测,相关成果发表于 JACC 子刊(影响因子 24+)。
* 论文名称:AI-Enabled CT Cardiac Chamber Volumetry Predicts Atrial Fibrillation and Stroke Comparable to MRI
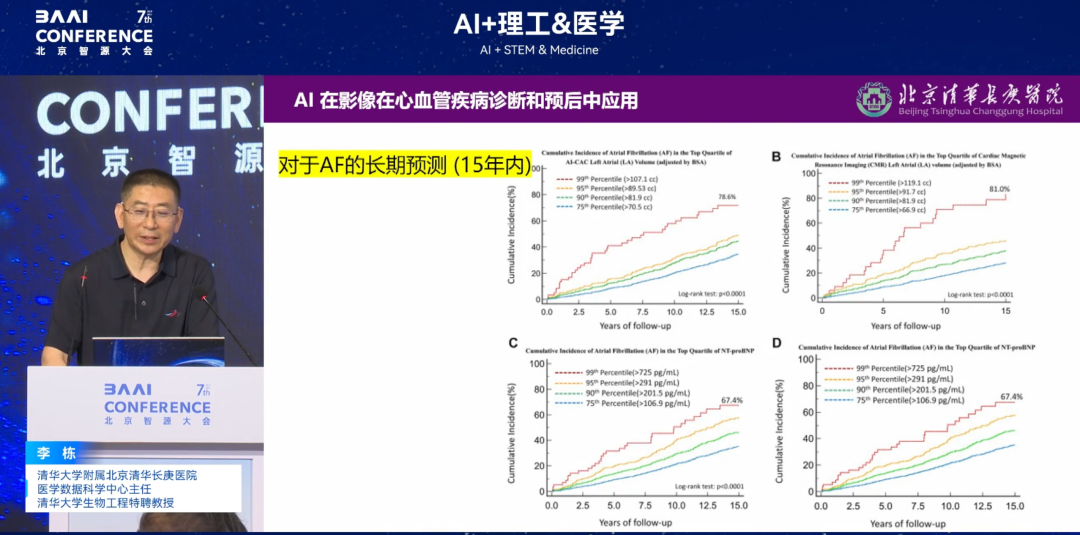
对于心房颤动(AF)的长期预测 (15 年内)
糖尿病研究:从「并发症谱」到「因果机制」
另一个研究是基于大模型做的疾病网络分析。此前人们认为早发性糖尿病(40 岁前发病)病情比正常发病更轻,比如 20 岁发病者 30 岁时可能血压、血脂正常且无并发症,而 40 岁发病者 50 岁时可能指标异常并伴有其他疾病。但通过对全身系统的糖尿病并发症谱系研究发现,早发性糖尿病的并发症系统交互作用更密集,存在向量通路关联,这与人们的固有认知不同。
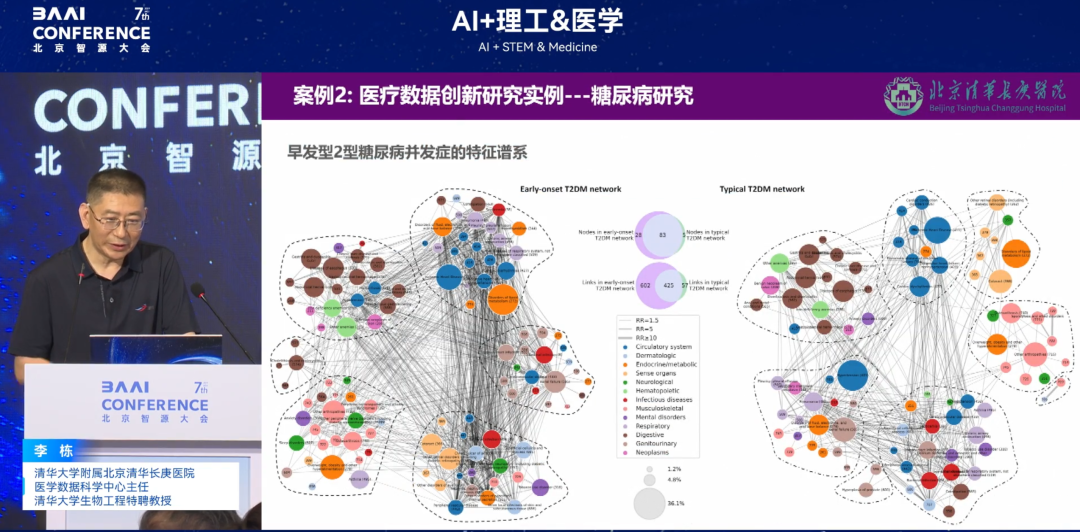
早发型 2 型糖尿病并发症的特征谱系
(左:早发性糖尿病;右:正常发现糖尿病;每个不同颜色的小圈代表不同的系统)
未来展望:数据智能时代的医疗新范式
近年来,中国医疗 AI 正处在提速阶段。正如李国杰院士所言「现在人类处于信息时代的智能化阶段,正在向智能时代迈进,智能化科研范式顺应而生,可以成为「第五科研范式」。对时代的认识不能犯错误,错过时代转变机遇将遭受历史性的降维打击」。
在未来,我们需要在以下方向发力:
* 医生层面:未来数据是必然趋势,跨学科合作(医工结合)是用数据开展创新研究的必要条件,培养「医疗+数据」两栖人才是重中之重。医生需掌握一定的 AI 知识(如模型评估、数据解读),以便更好地与算法工程师,数据科学家之间的合作,提高 AI 在医疗保健的应用效果。
* 算法层面:如今数据驱动面临着训练费用高昂这一大困境。未来我们期望能够研发更贴合医疗场景的轻量级模型,降低算力门槛,并且提高算法的临床应用的可解释性及信任度,特别是增加医生和患者对 AI 的接受度,让 AI 融入医疗。
* 医院层面:当没有好的研究思路,对创新性一筹莫展之际,不妨从数据入手,并善用最新信息科学研究手段,所以医院应鼓励并给予大力支持,科研数据机房要配备相应的计算、存储、网络、安全等基础设施建设,为数据层面的医疗创新提供关键服务。
大模型虽不是万能药,但其背后的数据思维正在重塑医疗本质。当我们真正学会用数据讲故事,用算法找答案之时,将「数据智能+医疗本质」深度融合,才能在医疗创新中占据先机,让智慧医疗真正服务患者、回馈社会。
关于李栋教授
李栋教授,医学博士,国际知名的医学数据科学专家,现任清华大学附属北京清华长庚医院医学数据科学中心主任、清华大学生物工程特聘教授。李栋教授曾在加州大学洛杉矶分校 Harbor 医疗中心担任首位华裔临床研究中心主任,并曾受聘为四川大学华西医院特聘教授。

李栋教授于国际顶尖学术期刊上发表了 100 余篇 SCI 论文,据统计在过去 5 年内总被引用近 4 千次,他还发表 220 余篇学术会议摘要。此外,他曾应邀进行过 40 余次学术讲座,参与编写了 4 本学术专著,并拥有 2 项发明专利。
其研究领域涵盖广泛,主要负责包括临床研究设计,衡量与评价,建模分析、医疗数据挖掘,以及人工智能在医疗中的应用。他在领导临床科研团队进行医疗大数据挖掘和开发智能医疗决策分析系统方面拥有丰富的经验,是该领域公认的权威。



戳“阅读原文”,免费获取海量数据集资源!
(文:HyperAI超神经)