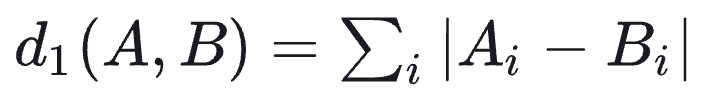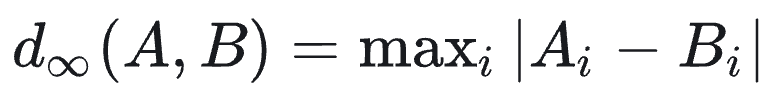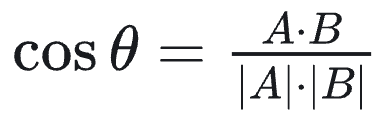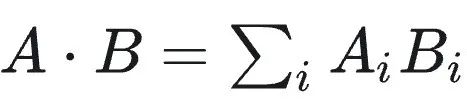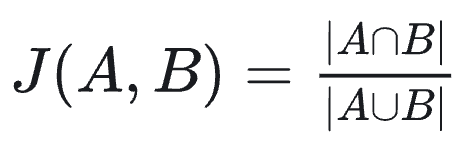太长不看 & 通俗易懂版: 向量数据库通过类似超市货架的分区陈列,把代表文本、图像等内容的高维向量有序地归档到特定索引结构中,使系统在接到查询向量时能快速返回最相似结果——这一能力源于层次图 HNSW、量化 IVF-PQ 及 DiskANN 等近似最近邻算法对“快”和“准”的兼顾。在大模型时代前, 向量检索 就已支撑 人脸识别 、 推荐排序 、 异常检测 等场景;如今,大模型需要用向量回溯长上下文或私有知识,进一步促进了向量数据库领域的发展。与传统键值库相比,这类系统不仅要管理嵌入生成、索引构建及查询调度,还必须在工程层面解决混合稠密-稀疏检索等复杂挑战,以确保在海量数据和持续写入下依旧保持高吞吐与一致性。
推荐阅读:
Building LLM Applications: Vector Database ( https://medium.com/@vipra_singh/building-llm-applications-vector-database-part-4-2bb29e7c798d )
Faiss: The Missing Manual | Pinecone( https://www.pinecone.io/learn/series/faiss/ )
Vector Database Management Techniques and Systems( https://dbgroup.cs.tsinghua.edu.cn/ligl/papers/vdbms-tutorial-clean.pdf )
也谈LLM-Based Agent——规划&推理、记忆、工具使用与多Agent系统( https://zhuanlan.zhihu.com/p/13905150871 )
《向量数据库:大模型驱动的智能检索与应用》,梁楠 著,清华大学出版社
一、向量数据库的概念起源与背景 第一次听说向量数据库,应该是在2年前和一位从事AI Infra创业的前辈吃饭时听过,当时也十分好奇什么是向量数据库。后来我也在“也谈LLM-Based Agent——规划&推理、记忆、工具使用与多Agent系统”一文中简单提过,但也不曾深入探索。这次将更系统 、 更全面 地介绍下 向量数据库的前世今生 。
与人类类似的,可分为 感官记忆(Sensory Memory,原始输入) 、 短期记忆(Short-Term Memory,对话交互) 、 长期记忆(Long-Term Memory,外部存储数据) 。常见的技术如RAG技术,涉及的技术栈: 数据库检索、向量数据库、embedding 等。 外部存储可缓解有限注意力跨度的限制,一定程度上避免模型输出带有幻觉的答案。一种常见的做法是将信息的嵌入表示保存到向量数据库中,该数据库能够支持快速的最大内积搜索。常见的选择是最近邻算法以返回最接近的k个最近邻:LSH(Locality-Sensitive Hashing): 引入Hash函数,使得相似的输入以高概率被映射到相同的桶中,桶的数量远小于输入的数量;ANNOY(Approximate Nearest Neighbors Oh Yeah): 通过构造二叉树快速查询相似信息;HNSW (Hierarchical Navigable Small World)等。 尽管这是一个近年来才逐渐“火”起来的技术术语,但其核心理念—— 向量化表示 存在已久。向量数据库本质上是一种专门用于存储 向量化表示 的系统。这些向量通常来源于图像、文本、音频等多模态数据,经过嵌入模型(embedding)处理后被映射到统一的高维向量空间中,从而实现统一表示、快速检索与相似性计算。
在现实世界中,我们的信息可以通过图像、视频(即大量图像序列)、文本、音频等形式存在;而在计算机世界中,这些信息最终都必须被转化为二进制数据(0 与 1)。如何在计算机语言中有效表示现实世界中的文本与图像信息,早在深度学习时代前就已是人工智能领域的核心议题。在整理本篇内容的过程中,笔者意外翻阅了《2016年中国中文信息学会中文信息处理发展报告》,其中对“语言表示”研究的核心问题有着清晰表述:
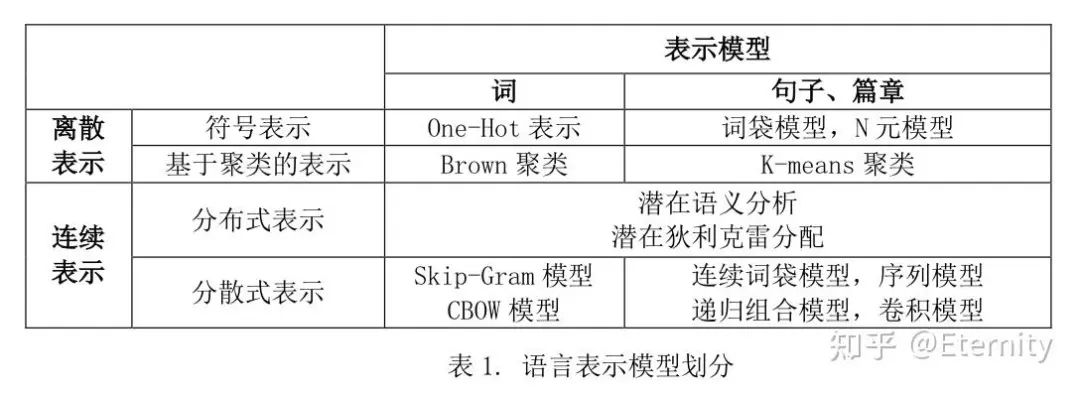
语言表示的研究内容可定义为,如何设计一种计算机内部的数据结构表示语言以及语言与该表示的转换机制。早期的语言表示方法是符号化的离散表示(如独热编码、ti-idf词袋模型),但这些词之间没有距离的概念,比如“计算机”和“电脑”被认为是两个完全不同的词,继而引入了人工知识库,如同义词词典。
2016年中国中文信息学会中文信息处理发展报告
An embedding is a representation of a data object (e.g., a word, image, or user) in a vector space, where each dimension of the vector corresponds to a particular feature or property of the object. For example, in NLP, word embeddings are commonly used to represent words as dense vectors of fixed length, where each dimension of the vector represents a semantic or syntactic property of the word.
文本向量化表示 早期文本表示以 词袋模型 (Bag-of-Words)为主,将文档表示为词频向量,但忽略词序和上下文信息。经典改进是 TF–IDF (Term Frequency–Inverse Document Frequency),即将词频与逆文档频率相结合衡量词在语料中的重要性,能够在一定程度上抑制高频无关词的影响。此类方法易于实现、效果稳定,被广泛应用于信息检索和文本分类等任务,但其表示只捕捉词语统计信息,无法体现词义和语法结构。
为克服词袋模型的局限,引入了 分布式词向量 。
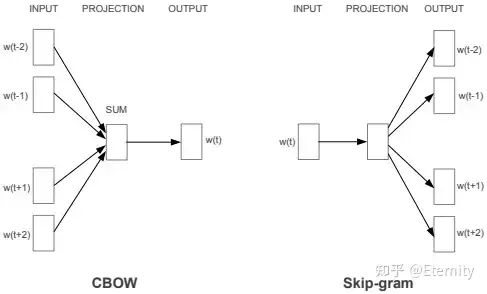
Word2Vec(2013):由Mikolov等提出,包括 连续词袋模型(CBOW) 和 Skip-gram 两种网络结构。CBOW以上下文词预测中心词(如图所示),而Skip-gram则反向以上下文预测目标词。Word2Vec训练出的词向量维度低、训练高效,能够捕捉到词语的语义相似性(如“国王–皇后”)和逻辑关系,但词向量是静态的、不随上下文变化,无法区分词义歧义。
GloVe(2014):由斯坦福团队提出,是一种 全局词共现矩阵 分解方法。GloVe 将词与词在整个语料中的共现概率联系起来,通过优化目标使得词向量能够反映统计规律。GloVe 结合了矩阵分解和上下文窗口的优点,对数计数方式提高了训练效率,但仍属于静态词向量方法。
<span leaf=””><span leaf="">&lt;span leaf=""&gt;&amp;lt;span leaf=&amp;quot;&amp;quot;&amp;gt;&amp;amp;lt;span leaf=&amp;quot;&amp;quot;&amp;amp;gt;&amp;amp;amp;lt;span leaf=&amp;amp;amp;quot;&amp;amp;amp;quot;&amp;amp;amp;gt;&amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;quot;&amp;amp;amp;amp;quot;&amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot; style=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;font-size: 15px&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;span leaf=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;img data-imgfileid=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;100224893&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot; data-src=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;https://mmbiz.qpic.cn/sz_mmbiz_jpg/vI9nYe94fsEuibvMCicStTR3icJnMBvkd8f9nG0abIpcibwkf1ibpJwibicghF9ywFRy3yTVn5RULFJ9nC9rh3hDF4Tiaw/640?wx_fmt=jpeg&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;from=appmsg&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot; data-type=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;jpeg&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot; width=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;487&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;/&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;lt;/span&amp;amp;amp;amp;gt;&amp;amp;amp;lt;/span&amp;amp;amp;gt;&amp;amp;lt;/span&amp;amp;gt;&amp;lt;/span&amp;gt;&lt;/span&gt;</span></span> Word2Vec
代表性特点: 词向量模型使得每个词对应一个紧凑的向量,在许多下游任务中被用作输入特征。它们能捕获词语间的相似性(例如共同出现在相似上下文中的词具有近似向量),且计算效率高。但缺点是每个词仅有一个向量表示,无法根据具体上下文调整含义。
结构原理: 以CBOW为例(见上图),网络输入为上下文词的独热编码,经过嵌入层求和得到上下文向量,再通过全连接层预测中心词。Skip-gram则采用逆向结构:输入目标词,预测其多个上下文词。
优缺点: 优点是模型简单易训练,可通过大量无标注文本学习丰富语义知识;缺点是忽略上下文依赖,对于多义词和上下文敏感度低。
2017年提出的 Transformer 架构通过多头自注意力机制一次性考虑整个句子上下文,彻底取代了传统RNN在并行化和长距离依赖建模上的劣势。基于Transformer的预训练语言模型进一步推动了文本表示能力的跃升:
BERT(2018):Devlin等提出的双向Transformer预训练模型,通过对输入文本进行随机遮蔽(Mask)任务来学习上下文相关的词表示。在大量语料上预训练后,BERT在各类NLP任务中都取得了当时最优结果。其优点是充分利用双向上下文信息,但需要大规模计算资源和训练语料。
GPT系列(2018-至今):OpenAI推出的GPT模型使用堆叠的Transformer解码器,以自回归方式(仅利用左侧上下文)进行语言建模。GPT-1/2/3逐步增加模型规模,并在生成、对话等任务中表现出强大能力。最新的GPT-4等多模态版本已能处理图像输入,实现视觉-语言任务。
如果你想详细学习文本向量化表示,这里推荐:
Datawhale: 一文详尽之Embedding(向量表示)
@JayJay nlp中的词向量对比:word2vec/glove/fastText/elmo/GPT/bert ( https://zhuanlan.zhihu.com/p/56382372 )
图像向量化表示 经典手工特征(SIFT等) 在深度学习普及之前,图像表示主要依赖 局部特征描述符 。如SIFT(尺度不变特征变换)算法通过检测并描述图像中的关键点,使得特征对平移、旋转和尺度变化具有不变性。SIFT为图像匹配和物体识别提供了鲁棒的特征表示,但属于低层次特征,仅反映局部纹理和边缘信息。类似地,HOG(方向梯度直方图)等手工特征也在早期视觉任务中得到广泛应用。这些方法的优点是理论成熟、计算简单,但对全局结构和语义信息刻画不足。
经典手工特征示意图
卷积神经网络时代(AlexNet、VGG、ResNet 等) 2012年AlexNet发表后,深度卷积神经网络(CNN)引爆了计算机视觉革命。
AlexNet(2012):Krizhevsky等设计的8层CNN,以ReLU激活和Dropout正则化著称,在ImageNet竞赛中大幅超越传统方法。AlexNet证明了深层网络和GPU并行训练的重要性,开启了深度学习在视觉领域的广泛应用。
VGGNet(2014):Simonyan等提出的非常深的CNN结构(常见16层或19层),使用小卷积核和更多层来提升模型表达能力,极大地提高了分类准确率。
ResNet(2015):He等提出的残差网络引入了 残差连接, 这种跳跃连接有效缓解了网络加深时的退化问题,使网络层数能够扩展到数百层。ResNet凭借其优秀的训练稳定性和准确率赢得了2015年ImageNet竞赛。
代表性特点: 深度CNN通过卷积层自动学习多层次的图像特征,从边缘到纹理再到高级语义逐层抽象,大大优于手工特征。上述经典网络推动了视觉特征提取的飞跃。它们的优点是对图像平移不变且擅长捕捉局部模式;缺点是计算量大,且只能处理固定大小的输入,需要大量标注数据预训练。
视觉Transformer(ViT等) 近期,视觉Transformer(ViT)将Transformer引入图像领域。Dosovitskiy等(2020)提出将图像划分为若干小块(patch),并将每个patch视作序列输入到Transformer模型中进行处理。
此外,随着 对比学习、多模态融合与对齐 等技术的发展。如 CLIP、 ALIGN 、 BLIP 等预训练模型使视觉和语言表征联合在同一嵌入空间。 CLIP(2021) :由OpenAI提出的Contrastive Language-Image Pretraining模型。CLIP使用一个图像编码器和一个文本编码器,将图像和其对应文本映射到同一向量空间,并通过对比损失将匹配的图文对靠近。
音频向量化表示 经典语音特征(MFCC等) 语音信号的传统特征提取方法包括MFCC(梅尔倒谱系数)、PLP等,用于描述语音的频谱包络信息。这些特征设计依据生理听觉模型,在ASR、情感识别等任务中长期有效。但它们仍属浅层特征,无法自动学习更高阶的语言和语音信息,对说话人和环境的鲁棒性有限,通常需配合复杂模型来提高性能。
梅尔倒谱系数特征示意图
自监督语音模型(Wav2Vec、HuBERT等) 近年来,语音领域也借鉴了文本与视觉的自监督预训练思想: Wav2Vec(2019) :Schneider等提出了第一个Wav2Vec模型。该模型使用双层卷积网络编码原始音频,通过噪声对比学习(NCE)任务来预测未来音频帧。Wav2Vec的优点是无需文本标签即可从大量无标注音频学习特征,但早期模型仍依赖ConvNet结构,有一定的表达局限。 Wav2Vec 2.0(2020) :Baevski等改进了Wav2Vec,引入了Transformer编码器和向量量化,将输入划分为离散音频单元,并对其进行Masked Prediction预训练。Wav2Vec 2.0在LibriSpeech等标准基准上达到了超越以往方法的性能,进一步推动了无监督语音表征发展。
一些思考与题外话 好的特征能够在很多任务中起到非常重要的作用,比如对于 行人重识别任务 ,好的特征能够捕捉到行人本体特征,即使跨镜换装也能被准确识别。笔者曾经在五六年前研究过向量表示的一些性质,试图解耦其中的语义表示,也对“流形”、“语义表示”如痴如醉,有兴趣的朋友可参考:
1. 时至今日,深度学习领域有哪些值得追踪的前沿研究? ( https://www.zhihu.com/question/385326992/answer/1138155479)
2. 大话深度学习之XXX-invariant Feature (https://zhuanlan.zhihu.com/p/419769117)
三、为什么需要向量数据库? 关系型与键值数据库依赖 B-tree / Hash 索引,以 键→值 的方式进行精确查找或范围过滤,擅长处理字段式结构化数据(如“姓名-学号-语文成绩”)。当查询目标变成“含义相似”或“外观接近”——例如“找出和这张图片最像的 10 张图”“找出与这段描述语义最贴近的文档”,传统数据库可能就无能为力。
在大模型时代前,向量检索就已经被用于 人脸识别 (摄像头抓拍的人脸特征向量与库中上亿人脸向量比对,要求亚毫秒延迟与高召回率)、 个性化推荐 (Spotify 最早用 Annoy 树搜索做歌曲向量检索,如今升级到基于 HNSW 的 Voyager 库以提升召回与并发)、 商品搜索 (将用户自然语言查询向量化后与商品向量匹配,提高转化率)、 异常检测 等领域。
随着大语言模型等技术的发展,训练时使用的数据已经无法满足一些应用场景的需求(模型的数据只能停留在某个时候,比如Claude提示词就明确显式表示了时效性),这一部分知识就需要通过工具或者记忆模块,并且以提示词的形式告诉大语言模型。对于一些特定领域的知识,如企业内部数据,无法以训练的方式“注入”大模型,这也催生了检索增强生成领域的发展。
此外,今天的大型语言模型在“能看多长文字”这件事上,既受工程层面(显存、计算量、价格)限制,也受模型机制(注意力矩阵是 n² 、训练分布偏短、递归“遗忘”效应)限制——上下文一旦太长,就会变得更慢、更贵、更占显存,甚至更爱“忘”和“胡编”。因此很多应用会先把长文本压缩成向量,再让模型按需取用(取较为相关的内容)可以有效减少上下文长度。
这里有一篇来自Percy Liang老师组的ACL 24 工作 Lost in the Middle: How Language Models Use Long Contexts( https://arxiv.org/abs/2307.03172?utm_source=chatgpt.com )揭示了长上下文中的信息并不会成比例有效利用,后续有机会单独解读下。
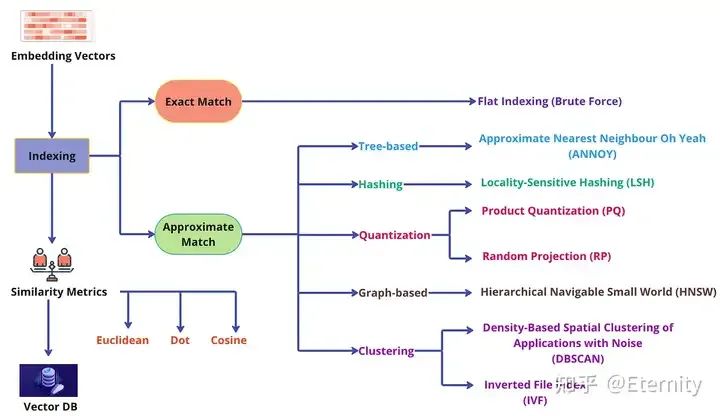
四、什么是向量数据库? 向量数据库的工作方式是使用算法对向量嵌入建立 索引 和进行 查询 。这些算法通过哈希、量化或基于图表的搜索来实现 近似最近邻 (ANN) 搜索 ,整体流程包括:预处理、索引、相似度查询、后处理。
来源:Building LLM Applications: Vector Database
Indexing 索引 使用 哈希 、 量化 或 基于图表 的技术,向量数据库通过将向量映射到给定的数据结构为向量建立索引,实现更快的搜索速度。本质上, 向量索引 是一种面向计算机科学与信息检索的专用数据结构,旨在高效存储与检索高维向量数据,使得“最近邻”搜索与相似性查询得以快速完成。
平面索引(Flat Indexing) :Flat 索引将所有向量按固定维度直接存储为原始编码数组(例如 ntotal × code_size 字节),不构建任何加速结构。在查询阶段,系统会将查询向量与索引中的每一个向量逐一计算相似度,然后选出相似度最低的 K 个向量作为返回结果。这种方式的优势是实现简单、原理直观,并且能提供 100%精确召回 ,被认为是 “暴力检索” 的代表。但它的主要缺点也显而易见: 速度慢 。每次查询都需要遍历整个向量集合,因此只适合用于小规模数据集,或对检索精度要求极高、可以容忍一定响应时间的场景。
基于树的索引: 例如 KD-Tree、Vantage-Point Tree 等,它们通过递归划分空间构建树结构。在低维度向量上效果不错,但维度一旦升高会迅速失效(即“维度诅咒”问题)。
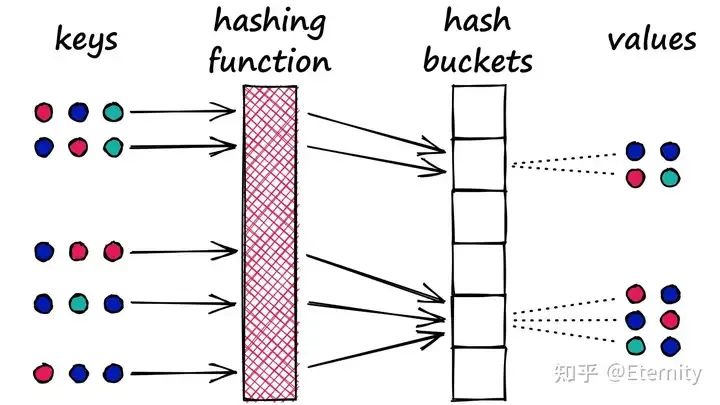
基于哈希的索引: 典型方法是 局部敏感哈希(LSH) ,通过巧妙设计哈希函数将相似向量以较高概率映射到相同的桶。这样查询时只需比较落在同一桶中的向量,大幅减少比较次数。这类方法支持接近亚线性的查询时间,但为了保证召回率往往需要构建多个哈希表,增加内存开销。
来源:Locality Sensitive Hashing (LSH): The Illustrated Guide
基于量化的索引: 通过向量量化来压缩和聚类向量,典型代表是倒排文件(IVF) + 乘积量化(PQ) 。该方法先将向量聚类到多个簇中心(IVF),查询时只搜索距离查询向量最近的几个簇,从而减少候选集合;然后对候选向量用PQ压缩编码计算近似距离排序。IVF-PQ能够显著降低内存占用并加快检索,在略微牺牲精度的情况下实现查询速度和准确率的平衡。
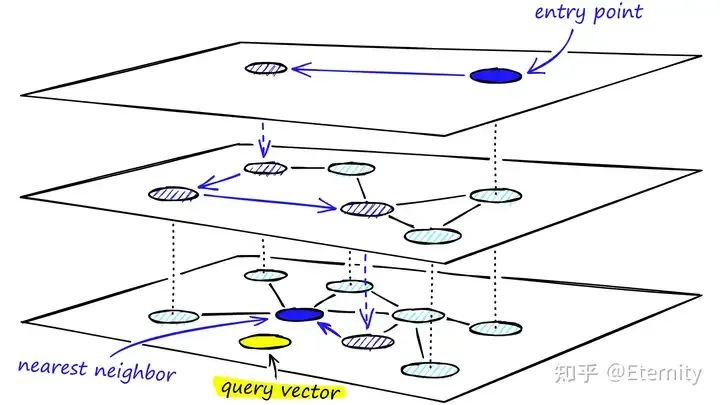
基于图的索引: 构建“近邻图”,让每个向量节点连接若干近邻向量。当前业界最先进的是 分层可导航小世界图(HNSW)。 HNSW构建多层图结构,高层节点数量少且连接长距离“跳跃”边,低层节点连接局部邻居,从而实现粗略定位后逐层精细搜索。查询时先从最高层的入口点出发,逐层贪心跳转到更接近查询向量的节点,最终在底层找到最邻近的若干向量。HNSW在实际基准中以 毫秒级 速度提供了优异的召回效果,大幅优于暴力搜索,是当前主流向量数据库广泛采用的索引方法。其缺点是索引构建相对复杂,占用内存较大,且动态更新(如删除向量)时需要维护图结构,操作难度较高。
来源:Hierarchical Navigable Small Worlds (HNSW)
强烈推荐阅读 : Faiss: The Missing Manual | Pinecone
强烈推荐阅读 : Faiss: The Missing Manual | Pinecone
强烈推荐阅读 : Faiss: The Missing Manual | Pinecone
(重要的事情说 三遍!地址: https://www.pinecone.io/learn/series/faiss/ )
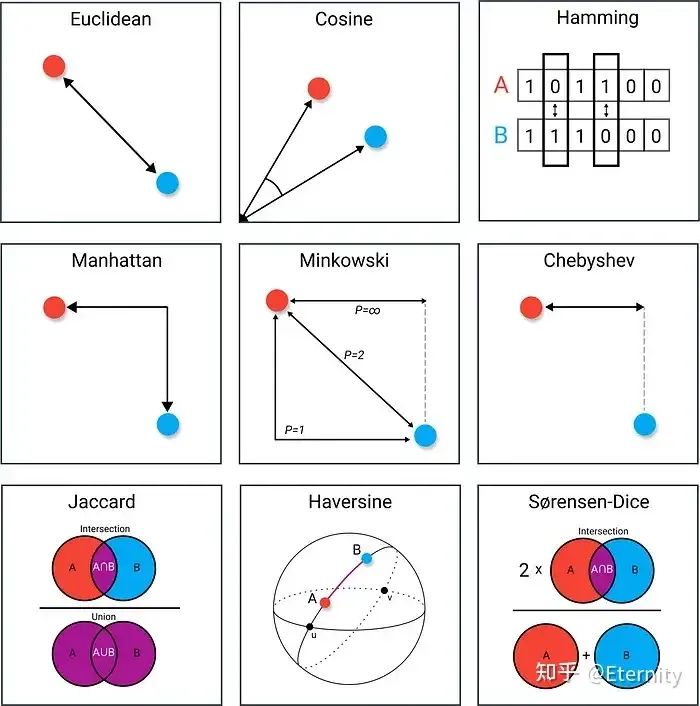
Similarity Metric 相似性度量 有了索引结构,向量数据库需要定义怎样衡量两个向量“相似”。常见的相似度或距离度量包括:
欧氏距离(L2 距离) :两点间的“直线”距离,也是最直观的度量方式。计算公式为:
值越小表示向量越接近,如果距离为0则表示两个向量完全相同。欧氏距离是连续数值向量最常用的度量,反映向量在空间位置上的直线距离。 曼哈顿距离(L1 距离) :也称绝对值距离,定义为各维度差值绝对值之和:
可以理解为在二维平面上只能沿垂直/水平方向移动时,两点间的路径长度。L1距离对异常值不如L2敏感,常用于某些强调稀疏差异的场景。 切比雪夫距离(L∞ 距离) :定义为各维度差值的最大值:
它等价于国际象棋中国王一步走棋可达的距离(八个方向均可移动一步)。切比雪夫距离关注坐标最大差异,在某些需要“阈值内相似”判定的情形下会用到。 余弦相似度 :衡量两个向量方向上的相似度,其值等于二者夹角的余弦值,计算公式为:
范围为[-1,1],1表示两个向量同向(完全相似),0表示正交无相关,-1表示方向相反。在向量检索中我们通常关注向量夹角大小而忽略长度影响,因此 余弦相似度 非常常用,特别适合衡量文本等归一化向量的语义相似性。当使用余弦度量时,数据库往往会存储标准化后的单位向量,使得余弦相似度与点积成正比,计算更高效。
内积(点积) :即不对向量归一化,直接计算
作为相似度分数。内积没有固定范围,但在许多机器学习场景下,模型直接以最大化内积作为目标(如矩阵分解推荐、某些embedding模型),因此在相似搜索时直接使用点积更符合模型的意义。需要注意如果不做归一化,向量长度会影响点积值大小。因此实际应用中,如果想体现纯粹方向相似,一般选择余弦相似度;而在已调过模型、embedding长度蕴含某种权重时,可以使用内积作为相似度。
汉明距离 :针对二进制向量(仅由0/1组成)的度量,等于对应位不同的数量。也就是两个0/1串的异或结果中1的个数。汉明距离适用于感知哈希、二值量化等生成的向量,值越小表示两向量二进制表示越相似。比如在某些图像识别中,将图像哈希成位串后,用汉明距离判断相似图片。
杰卡德相似度 :衡量两个集合的相似度,定义为
,即交集占并集的比例。如果将向量视作元素集合(或0/1特征向量),杰卡德相似度反映二者共有特征的比例,值越接近1表示重合度越高。杰卡德相似度常用于推荐系统中用户兴趣集合的相似性计算、文本的关键词集合相似度等(注:对于0/1向量也可用杰卡德相似度衡量,其与汉明距离存在一定关系)。由于杰卡德不考虑共同缺失的特征,只关注共同拥有的特征,在衡量稀疏二元属性相似度时很有意义。
来源:Building LLM Applications: Vector Database 以上度量各有适用范围。向量数据库通常会支持多种距离公式,用户可根据数据特点选择。例如Milvus支持欧氏、余弦、内积外,还支持汉明、杰卡德等用于二值向量的度量。不同度量在不同数据库中的支持程度不一,如有的引擎只支持欧氏和余弦,有的还支持更复杂度量。选择合适的相似度度量,对检索效果和性能至关重要。
预处理与后处理 预处理与后处理 是向量检索流程中容易被忽略但很重要的环节。
检索前的预处理主要包括数据向量化和索引构建 。在引入数据时,需要先通过Embedding模型将原始文本、图像、音频等数据转换为向量表示并进行必要归一化或降维处理。例如,为了降低向量维数、减少计算量,可能先对embedding结果做PCA降维或使用产品量化将向量编码压缩。在索引建立阶段,可能还需要对数据进行 清洗和去重 (确保不要存储大量近似重复的向量)。另外,在查询阶段的预处理还包括对用户查询进行同样的向量化,将检索词或查询内容转成查询向量。如果有元数据(如向量对应文本的标签、类别),查询时也会解析附加过滤条件用于后续筛选。
检索后的后处理是取得初步结果后进行的结果精 refinement 和过滤操作 (也有些处理管线会将过滤操作放置于预处理步骤) 。 由于多数ANN算法得到的近似最近邻集合可能包含少量误差排序,常见做法是对候选结果再做一次精确距离计算重新排序,提高最终准确率。比如在IVF-PQ中,查询首先找到若干最近的簇中心,然后在这些簇内用PQ码找出若干候选向量,最后对这些候选的原始向量计算真实距离并排序得到Top K结果。这种“两阶段检索+精排”的后处理能显著提升结果精度。另外,如果应用有 过滤条件 (如只需要类别相同的向量),在得到候选集后也会根据元数据执行过滤。有些向量数据库支持对结果向量再进行 多样性重排 或结合其它信号排序(例如结合文本相关度二次排序),以满足应用的特定需求。
向量数据库通过 建立高效索引 、 使用合理的相似度度量 以及 配套的前后处理 ,实现了在海量高维向量中快速检索相似项的能力。在实际部署中,不同算法和策略常常组合使用:如对向量先降维或规范化(预处理),通过HNSW快速找近邻,再精确计算欧氏距离排序(后处理),这样既保证速度又兼顾准确率。
五、主流向量数据库对比 目前业界有众多向量数据库解决方案,从底层库到云服务,各具特色。以下列出几种具有代表性的方案,并简要比较它们在架构设计、性能表现及易用性等方面的差异。
来源:Choosing a Vector Database for Your Gen AI Stack
Faiss :由Facebook AI Research开源的向量相似检索库(C++实现)。Faiss更像是一个 库/工具包 而非完整数据库——它提供了丰富的索引算法(Flat、IVF、HNSW、PQ等)的实现和优化,支持GPU加速,在单机环境下追求极致性能。Faiss的优势是 查询速度快、算法灵活 ,常作为其他向量库的底层引擎或基准参考。但Faiss并不包含分布式存储、持久化、权限控制等数据库功能,通常需要开发者自行集成到应用或包装为服务。因此,Faiss适合嵌入式使用或搭建自定义向量服务,对于希望即装即用的用户来说门槛较高。此外,Faiss支持多种距离度量(L2、IP、余弦等),但 不直接支持过滤和复杂查询 (这些需在应用层配合实现)。
Chroma :近年来随着大模型应用兴起而流行的开源向量数据库。Chroma最早是为对接GPT等LLM的语义存储而设计,特色是 内置简单 、 针对开发者友好 。它用Python实现,支持轻量级的嵌入存储和检索,提供直观的API(pip安装即可用,几行代码完成向量存储/查询)。Chroma在LangChain等LLM应用框架中被广泛使用,作为默认的存储后端。非常适合作为 本地嵌入式数据库 :开发者在笔记本或小型服务中快速存取向量。当前Chroma不支持真正的分布式扩展,数据量大时可能需要借助外部存储或分片手动管理。另外,其检索算法相对简单(基于Faiss或Annoy封装)且主要在内存中操作,大数据集下性能和内存开销是瓶颈。Chroma的优势在于 上手容易、集成方便 ,非常适合原型开发、实验或中小规模应用;如果后期数据规模扩大,可能需要迁移到更重型的向量数据库。
笔者曾经简单使用过这两个向量检索库/数据库,它们相对上手容易,方便集成。除此以外,还有 Milvus 、 Weaviate 、 Pinecone 、 Qdrant ,它们中有的提供了从向量导入、索引构建到查询的全套解决方案,适合企业级部署;有的注重性能极致,适合对延迟要求苛刻的场景。目前向量数据库领域呈现“ 群雄逐鹿 ”的态势,不同产品在架构(是否分布式、存算分离)、接口(SQL/REST/客户端SDK/GraphQL)、生态(与ML工具集成程度)上各有侧重。用户应根据 数据规模、查询延迟要求、开发运维能力 来选型,感兴趣的读者可以参考以下内容进一步了解:
Vector Databases in Document Retrieval and RAG Applications ( https://www.rohan-paul.com/p/vector-databases-in-document-retrieval )
Choosing a Vector Database for Your Gen AI Stack ( https://www.singlestore.com/blog/choosing-a-vector-database-for-your-gen-ai-stack/ )
六、向量数据库的系统优化与未来趋势 回顾全文,虽然笔者介绍了 向量化表示 、 索引构建 和 相似度查询 等核心技术,但这些技术本身并不足以构成一个“向量数据库”。真正的向量数据库,是 围绕向量数据设计的一整套数据库管理系统 ,不仅包含一项或多项高效的向量索引算法,更包括数据持久化、复制扩展机制、安全策略、查询接口以及与主流开发框架的集成能力。将向量索引简单嵌入传统数据库,并不能自然地形成一个健壮、高性能的系统。高效的向量数据库往往面向 低延迟 、 高吞吐 、 高召回率 的检索场景,并支持实时更新和便捷运维,这需要在系统层面进行专门的设计和深度优化。
在 算法层面 ,虽然如 HNSW 等近似最近邻(ANN)算法已广泛应用并取得良好效果,但研究并未止步。为了应对超高维数据、极端内存受限场景或高频动态更新等挑战,更多新型算法不断涌现。例如,Facebook 推出的 IVFADC,Google 的 ScaNN 则结合了可学习压缩和树结构优化,分别在精度、延迟与资源占用之间取得平衡。其中一个明显趋势是 量化技术的深入发展 :除了传统的 PQ / OPQ,越来越多工作开始探索更高效的向量压缩与解码策略,以进一步降低索引规模。
同时, 硬件加速的兴起 也正在重塑向量搜索技术栈。一方面,GPU 在大规模并行计算上提供天然优势;另一方面,FPGA、ASIC 等专用芯片也有望为核心向量计算逻辑提供“烧入式”加速能力,从而实现超低延迟和更低功耗的专用解决方案。
在 系统架构层面 ,向量数据库也面临新的工程挑战:
写在最后 虽然本行还是计算机图形学,但每个人在大模型时代或多或少地要与时俱进,一直想催促自己多看点LLM相关的内容,也多写写笔记。笔者仔细阅读了《向量数据库:大模型驱动的智能检索与应用》一书的大部分章节,值得推荐。
本文成文比较“仓促”,文章整体轮廓、部分文字皆成型于万米高空。文中如有错误,欢迎批评指教。
参考 1.《向量数据库:大模型驱动的智能检索与应用》,梁楠 著,清华大学出版社 2.Datawhale: 一文详尽之Embedding(向量表示) 3.@JayJay nlp中的词向量对比:word2vec/glove/fastText/elmo/GPT/bert
4.@无易 Wav2vec 系列:从原始音频中学习语音的结构
5.Highlights from the Claude 4 system prompt 6.Vector Databases in Document Retrieval and RAG Applications 7.Vector Databases for Generative AI and beyond 8.What Are Vector Databases? The Secret Sauce Behind AI and LLMs 9.[ACL 2024] Lost in the Middle: How Language Models Use Long Contexts 10.How to choose a vector database 12.When Large Language Models Meet Vector Databases: A Survey 13.Pinecone: Great Algorithms Are Not Enough 14.Pinecone: Hierarchical Navigable Small Worlds (HNSW) 15.Pinecone: Locality Sensitive Hashing (LSH) 16.Survey of Vector Database Management Systems 17.Unleashing the Power of Vectors: Embeddings and Vector Databases 18.Choosing a Document Store 19.Choosing a Vector Database for Your Gen AI Stack 20.Building LLM Applications: Vector Database 21.@Zilliz 论文赏析:十亿级别单机向量检索方案 DiskAnn
22.理解 Product Quantization 算法 23.Vector Database Management Techniques and Systems
作者:Eternity,Datawhale成员
2.完整解读:从DeepSeek Janus到Janus-Pro! https://www.zhihu.com/people/AlbertRen
(文:Datawhale)