
AI Agent 的开发路径通常是这样的:我们可以在一到两天内快速构建一个原型应用,然后接着为了满足更多需求以及达到生产可用的要求,系统很快变得复杂难以维护。
比如: 一个模糊的用户指令,到底该交给哪个 Agent 处理?如何将自然语言稳定地转换为对外部 API 的调用?当任务在不同 Agent 间流转时,上下文如何不丢失?
这时候,应用已不再是单一功能的玩具,开发者也从快速实现一个原型产品的兴奋感陷入到维护混乱Pipeline,处理各种与业务关系不大的脏活累活的沮丧中,比如配置管理,多任务路由、多个大模型组合、上下文管理、限流均衡,甚至是安全防护等。
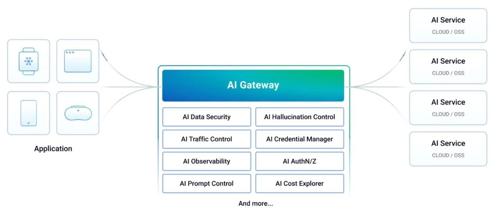
那么,这些与业务关系不大的共性的问题能不能有一种统一的手段解决呢?借鉴云原生gateway和service mesh的思路,将一些公共逻辑从应用逻辑剥离出来交给基础设施统一解决。因此,原本的一些云原生产品快速迭代,聚焦解决大模型应用的一些特有问题,朝着AI gateway进化,典型的就有Higress,Traefik,Kong等。
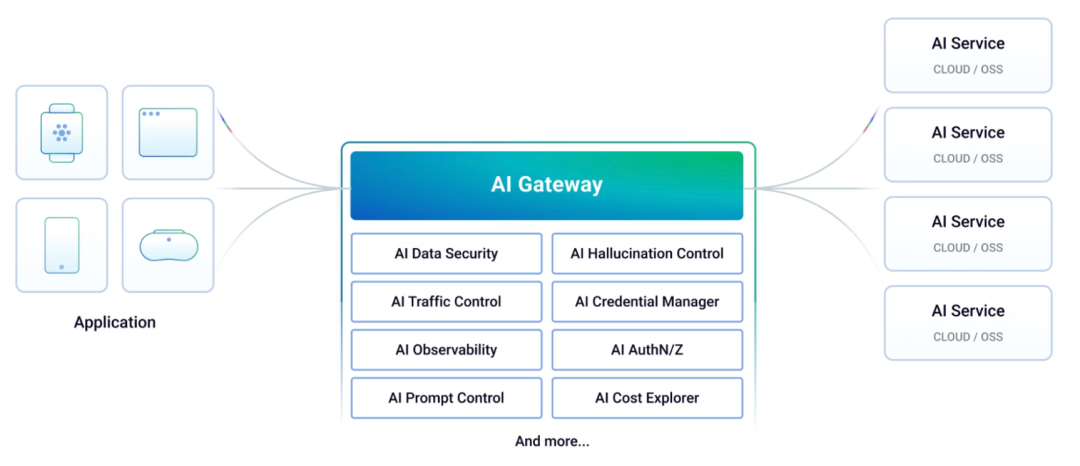
今天,介绍一款开源的完全新设计的AI原生gateway项目-Arch Gateway,它定位为 AI 应用的智能数据平面与通用代理层,一个 AI 时代的 Envoy Proxy。它认为,用户的 Prompt 本质上是一种新型的、充满不确定性的“请求”,理应像处理 HTTP 请求一样,在应用逻辑之外,由一个强大的代理层来负责路由、解析、安全和观测。
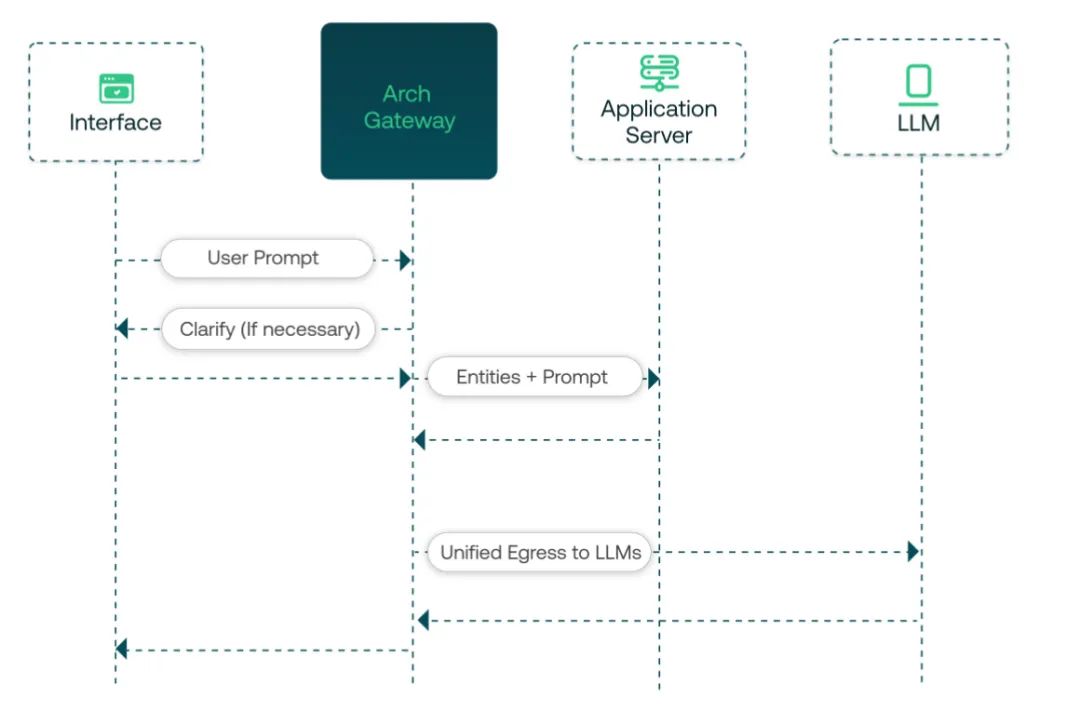
智能路由与工具调用
Arch 的核心能力,体现在它如何通过一份声明式的 arch_config.yaml 文件,在代理层将用户意图转化为具体的模型服务分发或者工具调用。整个过程对上游的应用完全透明。应用层只需发起一个简单的聊天请求,而复杂的意图识别、参数提取和工具调用,都由 Arch 在网络层面代理完成。
以一个外汇查询 Agent 为例,其关键配置在于 prompt_targets:
prompt_targets:
-name:currency_exchange
description:GetcurrencyexchangeratefromUSDtoothercurrencies# (1) 描述,用于意图匹配
parameters:
-name:currency_symbol
description:thecurrencythatneedsconversion
required:true
type:str # (2) 参数定义
endpoint:
name:frankfurther_api
path:/v1/latest?base=USD&symbols={currency_symbol} # (3) 目标 API
当一个请求 {"messages": [{"role": "user","content": "what is exchange rate for gbp"}]} 到达 Arch 时,其内部处理流程如下:
-
意图路由:Arch 内置的、为该场景特训的轻量级 LLM(响应 < 100ms)读取请求内容,并与 prompt_targets中所有条目的description字段进行语义匹配,精准判断出用户的意图是currency_exchange。 -
参数提取:确定目标后,Arch 按照 parameters的定义,从用户内容中提取出currency_symbol的值为 “gbp”。 -
API 调用:Arch 构造出最终的 API 请求路径 /v1/latest?base=USD&symbols=gbp,并调用在endpoints中定义的frankfurther_api。 -
上下文注入与最终生成:Arch 获取 API 的 JSON 响应,然后将其连同原始问题,一并作为上下文,发送给在 llm_providers中定义的通用大模型(如gpt-4o),生成最终给用户的自然语言回答。
统一的 LLM 访问网关
在多模型策略中,Arch 扮演着 LLM 流量路由器的角色作为大模型流量的唯一入口,将模型管理的复杂性从应用代码中剥离。
开发者可以在 arch_config.yaml 中定义多个 llm_providers,每个都有自己的模型名和密钥。
llm_providers:
-name:gpt-4o
access_key:$OPENAI_API_KEY
provider:openai
model:gpt-4o
default:true
-name:ministral-3b
access_key:$MISTRAL_API_KEY
provider:openai
model:ministral-3b-latest
应用代码的集成因此变得极为干净。例如,使用 OpenAI 的 Python 客户端时,只需将 base_url 指向 Arch,真正的密钥则由 Arch 集中管理:
from openai import OpenAI
client = OpenAI(
api_key = '--', # 密钥由 Arch 统一管理
base_url = "http://127.0.0.1:12000/v1" # 所有请求指向 Arch
)
默认所有请求会路由到 default: true 的模型。若需为特定请求(如 A/B 测试)切换模型,只需在 HTTP 请求中加入一个 Header 即可:x-arch-llm-provider-hint: ministral-3b。模型选择的控制权下放到了基础设施层,应用代码无需任何变更。
同时,它具备安全护栏功能,避免模型攻击。
系统调试与可观测性
Arch 基于 Envoy 构建,继承了其优秀的日志和追踪能力,为诊断 AI 系统的“黑盒”行为提供了关键数据。当 archgw up --foreground 运行时,日志清晰地记录了执行路径:
...[info] prompt_gateway: on_http_call_response: dispatching api call to endpoint: frankfurther_api...
...[info] prompt_gateway: on_http_call_response: developer api call response received: status code: 200
...[info] llm_gateway: on_http_response_body: time to first token: 1468ms
...[info] llm_gateway: on_http_response_body: request latency: 3183ms
这些日志将性能问题从“感觉很慢”变成了可度量的分析:你可以精确看到 API 调用是否成功、外部服务响应了多久、LLM 生成首token 的延迟(TTFT)是多少。

小结
云原生的成功实践,在大模型时代仍然有用,服务分层,职责分离的设计原则是系统复杂度增加后的必然选择。Arch Gateway这样的产品也正是在这样的背景下产生,它提供了一种清晰的架构分离,将 AI 应用中可复用的、与基础设施相关的部分(路由、工具调用、模型访问、观测)沉淀下来,让开发者可以更专注于实现核心的、具有业务价值的 Agent 逻辑,从而更快、更可靠地构建出强大的 AI 应用。
项目地址:https://github.com/katanemo/archgw
公众号回复“进群”入群讨论。
(文:AI工程化)