

金磊 克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
今年,AI大厂采购GPU的投入又双叒疯狂加码——
马斯克xAI打算把自家的10万卡超算扩增10倍,Meta也计划投资100亿建设一个130万卡规模的数据中心……
GPU的数量,已经成为了互联网企业AI实力的直接代表。
的确,建设AI算力,这种堆卡模式是最简单粗暴的,但实际上,AI集群却并非是卡越多就越好用。
GPU虽然计算性能好,但是在集群化的模式下依然有很多挑战,即便强如英伟达,也面临通信瓶颈、内存碎片化、资源利用率波动等问题。
简单说就是,由于通信等原因的限制,GPU的功力没办法完全发挥出来。
所以,建设AI时代的云数据中心,不是把卡堆到机柜里就能一劳永逸,现有数据中心的不足,需要用架构的创新才能解决。
最近,华为发布了一篇60页的重磅论文,提出了他们的下一代AI数据中心架构设计构想——Huawei CloudMatrix,以及该构想的第一代产品化的实现CloudMatrix384。相对于简单的“堆卡”,华为CloudMatrix给出的架构设计原则是,高带宽全对等互连和细粒度资源解耦。
这篇论文干货满满,不仅展示了CloudMatrix384的详细硬件设计,并介绍了基于CloudMatrix384进行DeepSeek推理的最佳实践方案——CloudMatrix-Infer。

那么,华为提出的CloudMatrix384到底有多强?简单地说,可以概括成三个方面——
-
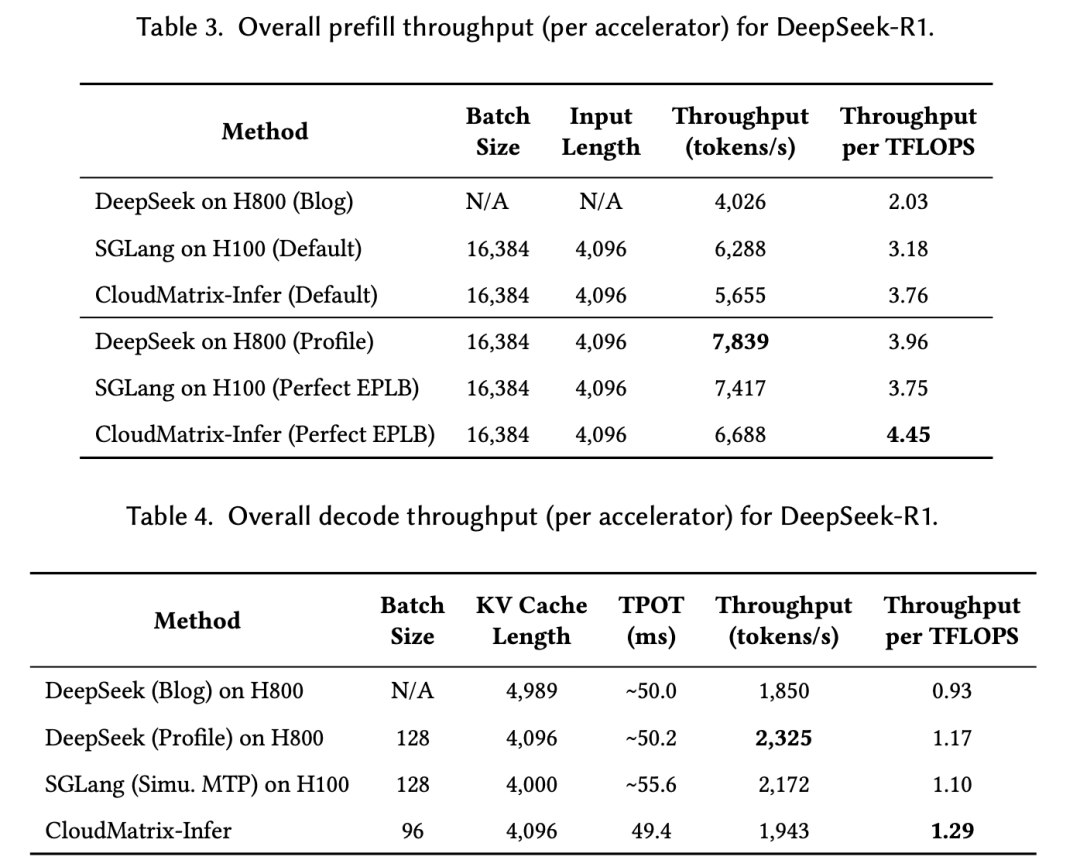
够高效:预填充吞吐量达6688 token/s/NPU,解码阶段1943 token/s/NPU;计算效率方面,预填充达4.45 token/s/TFLOPS,解码阶段1.29 token/s/TFLOPS,均超过业绩在NVIDIA H100/H800上实现的性能; -
够准确:DeepSeek-R1模型在昇腾NPU上INT8量化的基准测试精度与官方API一致; -
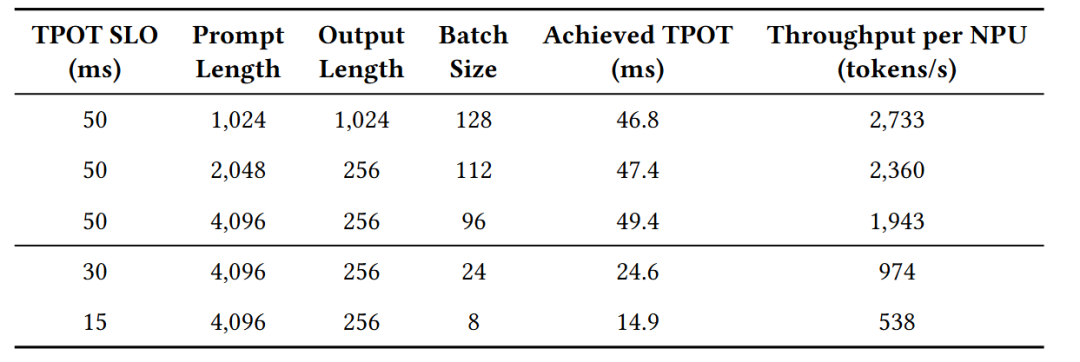
够灵活:支持动态调整推理时延SLO,在15ms严格延迟约束下仍维持538 token/s解码吞吐量。
AI数据中心架构,华为云提前迈出了一步
在深入剖析这篇重磅论文之前,我们有必要先来了解一下“Why we need CloudMatrix384”。
若是一句话来概括,就是满足不了当下AI发展的算力需求。
因为传统的AI集群,它内部运行的过程更像是“分散的小作坊”,每个服务器(节点)有种各玩各的感觉;算力、内存和网络资源等等,都是被固定分配的。
在这种传统模式下,AI集群一旦遇到超大规模的模型,就会出现各种问题,例如算力不够、内存带宽卡脖子、节点间通信慢如蜗牛等等。
而华为在这篇论文中要做的事情,就是提出一种新的模式,把这种“小作坊”改成“超级算力工厂”——
以CloudMatrix(首个生产级实现CloudMatrix384)为代表的华为云下一代AI数据中心架构。

它最鲜明的一大特点就是,所有的资源是可以统一调度的:CloudMatrix384把384个NPU、192个CPU以及其它硬件都集成到了一个超级节点当中。
因此在这里,像刚才提到的算力、内存、网络资源等等,会像工厂里的流水线一样被统一管理起来,哪里需要就调哪里。
并且数据在CloudMatrix384里,就像是搭乘了工厂里的高速传送带,因为所有芯片的连接都是由超高带宽、低延迟的统一总线(UB)网络完成,数据在芯片之间是“全对等”直接传输,这就避免了传统网络“堵车”的问题。
也正因如此,无论CloudMatrix384是遇到多大参数规模的大模型,亦或是需要频繁访问缓存的推理任务,都能通过动态分配资源,高效完成计算。
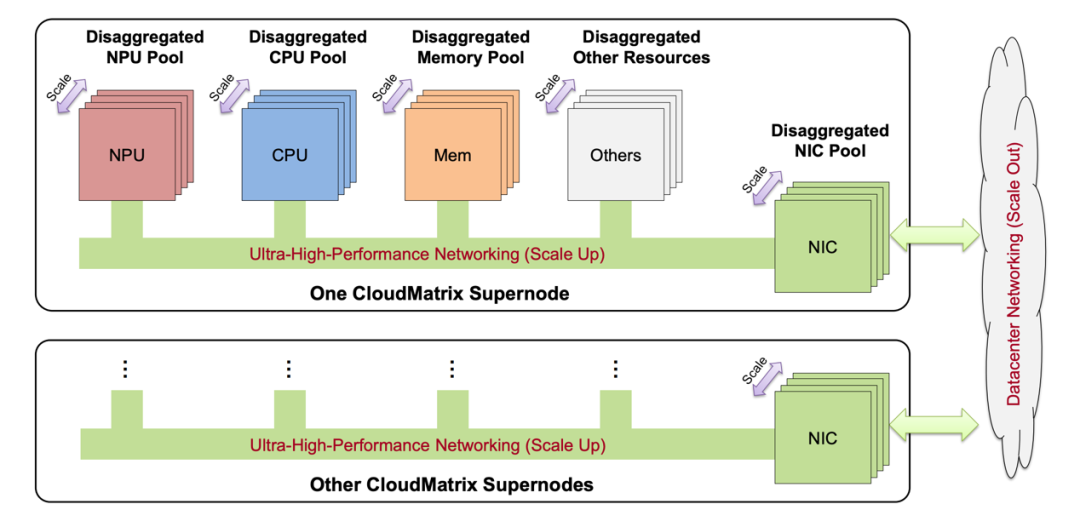
△华为CloudMatrix架构愿景
在了解完下一代AI数据中心的设计愿景之后,我们继续深扒一下细节创新技术和独特优势。
全对等互联:华为提前迈出的重要的一步
全对等互联(Peer-to-Peer),可以说是CloudMatrix384在硬件架构设计上的一大创新之处。
因为传统的AI集群中,CPU相当于扮演一个“领导”的角色,NPU等其它硬件更像是“下属”,数据传输的过程中就需要CPU“审批签字”,效率自然就会大打折扣。
尤其是在处理大规模模型的时候,通信开销甚至可以占整体任务时长的40%!
但在CloudMatrix384中,情况就截然不同了。
CPU和NPU等硬件更像是一个“扁平化管理的团队”,它们之间的地位比较平等,直接通过UB网络通信,省去了“领导传话”的时间。
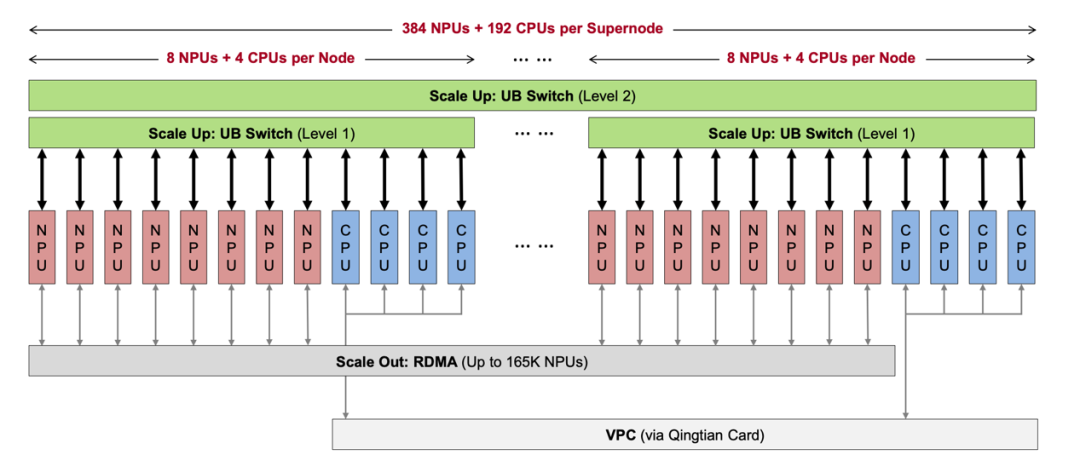
△CloudMatrix384全对等互联硬件架构设计
而实现如此“扁平化管理团队”的关键,就是我们刚才提到的UB网络,是一种无阻塞全连接拓扑。
它采用Clos架构设计,16个机架中的L1/L2交换机形成多层级无阻塞网络,可以确保任意两个NPU/CPU间通信带宽恒定。
而在传统集群中,节点间是通过RoCE网络来通信,带宽通常仅为200Gbps(约25GB/s),并且还存在 “南北向带宽瓶颈”(如数据中心核心交换机负载过高)。
但在UB网络的加持下,每个NPU可以提供392GB/s的单向带宽,相当于每秒能传48部1080P电影,数据传输又快又稳。
除此之外,传统NPU之间通信还依赖SDMA引擎(类似 “快递中转站”),它的缺点就是启动延迟比较高(约10微秒)。
为此,全对等互联引入了AIV直连(AIV-Direct)的机制,它可以直接通过UB网络写入远程NPU内存,跳过SDMA的中转,传输启动延迟从10微秒降至1微秒以内。
这个机制就非常适合MoE中token分发等高频通信的场景,把单次通信耗时缩短70%以上。
但除了硬件上的设计之外,软件层面的加持对于CloudMatrix384的高效率也是起到了功不可没的作用。
例如UB网络通过结合内存池化技术,实现了CloudMatrix384的“全局内存视图”,即所有NPU/CPU可直接访问跨节点内存,无需关心数据物理位置。
解码阶段的NPU可直接读取预填充阶段NPU生成的KV缓存,不用再通过CPU中转或磁盘存储,数据访问延迟从毫秒级降至微秒级,缓存命中率提升至56%以上。
再以671B的DeepSeek-R1为例,通过FusedDispatch融合算子与AIV直连,token分发延迟从800微秒降至300微秒。预填充计算效率提升4.45 token/秒/TFLOPS,超越了英伟达H100的3.75 token/秒/TFLOPS。
并且在TPOT<50ms的约束下,解码吞吐量达到了1943 token/秒/每NPU,即使收紧至TPOT<15ms,仍能维持538 token/秒,这就验证了全对等互联在严苛延迟场景下的稳定性。
因为云原生:不用关心硬件细节,华为云上开箱即用
除了“全对等互联”之外,这篇重磅论文的第二个技术关键词,非“云”莫属了。
简单来说,这是一套面向云的基础设施软件栈,它就像一个“智能管家团队”,可以把复杂的硬件设备变成人人能用的 “云端算力超市”。
值得一提的是,早在CloudMatrix384问世之前,华为云团队早早地就敲定下一代AI数据中心要以“面向云”为基础,这就体现了华为在技术战略布局上的前瞻性。
并且团队通过两年多时间的打磨,已经让部署CloudMatrix384这事变成“零门槛”,用户无需关心硬件细节直接可以部署。
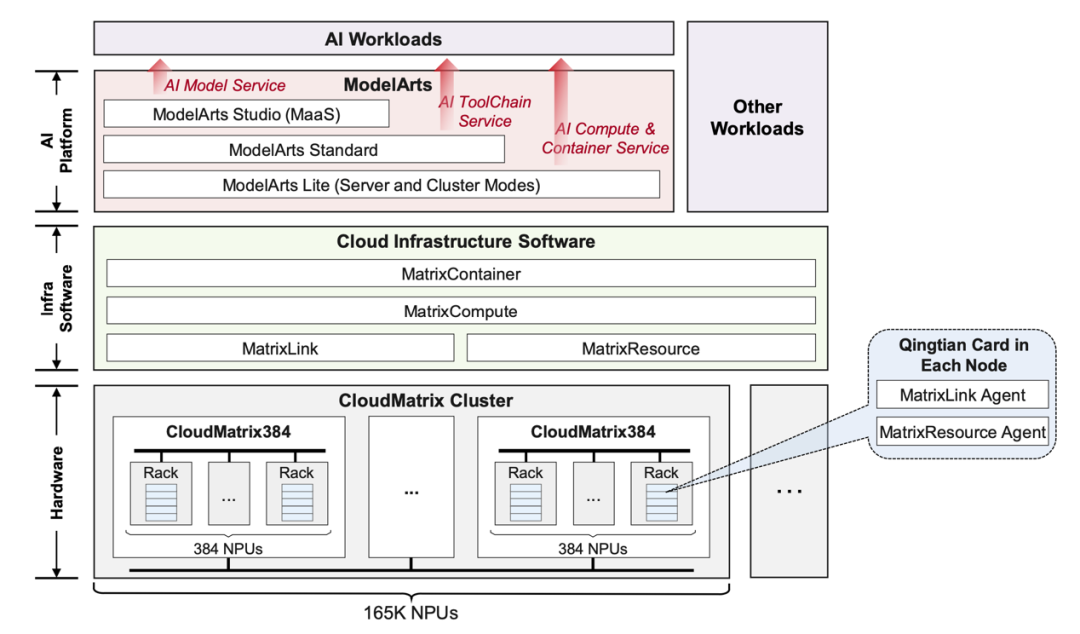
△部署CloudMatrix384的华为云基础设施软件栈
整体来看,这套面向云的基础设施软件栈主要包含以下几大模块:MatrixResource、MatrixLink、MatrixCompute、MatrixContainer,以及顶层的ModelArts平台,它们之间可以说是分工明确且相互协作。
首先我们来看下MatrixResource。
它在软件栈中起到的是“资源分配管家”的作用,主要负责超级节点内物理资源的供应,包括基于拓扑感知的计算实例分配。
通过运行在每个计算节点擎天卡上的MatrixResource代理,动态管理NPU、CPU等硬件资源的分配,确保资源按拓扑结构高效调度,避免跨节点通信瓶颈。
MatrixLink则是一位“网络通信管家”。
它为UB和RDMA网络提供服务化功能,支持QoS保障、动态路由及网络感知的工作负载放置。可以优化超节点内384个NPU及跨节点间的通信效率,例如在推理场景中通过并行传输和多路径负载均衡技术,辅助提升推理效率20%。
MatrixCompute的角色像是“逻辑超节点管家”。
它的任务是管理超节点的 “生老病死”,从开机启动到故障修复全负责,包括裸金属供应、自动扩缩容、故障恢复等。
具体实现的方式是跨物理节点编排资源,将分散的硬件组件构建为紧密耦合的逻辑超级节点实例,实现资源的弹性扩展和高可用性。
MatrixContainer是“容器部署管家”。
它的作用是让用户的AI应用能像 “快递包裹” 一样轻松部署到超节点上:基于Kubernetes容器技术,把复杂的AI程序打包成标准化容器,用户只需“点击部署”,它就会自动安排到合适的硬件上运行。
最后,就是ModelArts这位“AI全流程管家”了。
它位于整个软件栈的顶层,提供从模型开发、训练到部署的全流程服务,包括ModelArts Lite(裸金属/容器化硬件访问)、ModelArts Standard(完整MLOps流水线)、ModelArts Studio(模型即服务,MaaS)。
新手可以用ModelArts Lite直接调用硬件算力;进阶用户可以用ModelArts Standard管理训练、优化、部署全流程;企业用户则可以用ModelArts Studio把模型变成API服务(如聊天机器人),一键发布。
由此可见,在CloudMatrix384本身高效的基础上,面向云的基础设施软件栈起到了“如虎添翼”的作用,使得部署这件事变得更加便捷。
软硬一体:高效、便捷的同时,也够灵活
除了“全对等互联”和“云原生”这两个关键词,论文中也还涉及到了二者“软硬一体”结合下,在灵活性上体现出来的优势。
例如刚才我们提到的“用户无需关注底层硬件细节,只需调用API”这方面,具体而言,是华为云EMS(弹性内存服务)通过内存池化技术,将CPU连接的DRAM聚合为共享内存池,NPU可直接访问远程内存,实现KV缓存复用,使首Token时延降低 80%,同时减少NPU购买量约50%。
以及MatrixCompute支持超节点实例的自动扩缩容,例如根据工作负载动态调整预填充/解码集群的NPU数量,在严苛的15ms TPOT约束下仍能维持538 token/秒的解码吞吐量。
通过确定性运维服务和昇腾云脑技术,还可以实现万卡集群故障10分钟内恢复,HBM和网络链路故障场景下恢复时间挑战30秒,例如光模块故障影响降低96%,保障训练/推理任务的连续性。
软件栈还支持超节点资源的多租户切分,不同用户可共享硬件资源但逻辑隔离,例如通过命名空间隔离不同模型的缓存数据,确保数据安全与资源公平分配。
通过智能化调度实现“朝推夜训”,白天运行推理任务,夜间利用闲置算力进行模型训练,节点在训练/推理间切换<5分钟,提升算力利用率。
据了解,CloudMatrix384已经在华为云乌兰察布、和林格尔、贵安、芜湖四大节点上线,用户可按需开通算力,无需自行搭建硬件环境,10毫秒时延圈覆盖全国19个城市群,支持低延迟访问。
并且CloudMatrix384还提供全栈智能运维的能力,例如昇腾云脑的故障知识库已经覆盖了95%的常见场景,一键诊断的准确率达到了80%、网络故障诊断<10分钟,可以说是把运维的门槛也打了下去。
打破“不可能三角”
看到这里,我们可以做个简单总结了。
华为的CloudMatrix384通过“全对等架构+软硬协同”的模式,打破了传统上算力、延迟和成本之间的“不可能三角”。
硬件层面,它的全对等UB总线实现392GB/s卡间带宽,让384张NPU能够高效协同工作,在EP320专家并行模式下,token分发延迟控制在100微秒以内。
软件层面的CloudMatrix-Infer采用全对等推理架构、大EP并行、昇腾定制融合算子、UB驱动的分离式内存池等,最大化发挥硬件效率。
这种设计让高算力、低延迟、可控成本同时成为可能,总之有了CloudMatrix384,云端的大模型部署方案变得更香了。
云端可以在数据中心级别进行统一规划,构建专门的高速网络拓扑,突破单一企业的物理限制。
更关键的是,云端支持弹性扩缩容,企业可以根据业务需求动态调整资源规模,从几十张卡扩展到数百张卡,而无需对物理设施进行改动。

而且,选择云也意味着不需要用户自己找专业团队去处理模型优化、分布式训练、故障处理等复杂问题。
CloudMatrix384的运维自动化设计更是将故障影响降低96%,万卡集群故障恢复时间控制在5分钟以内,这种专业化运维能力是大部分企业无法自建的。
更重要的,CloudMatrix384代表的云端AI服务模式为中国企业提供了一个更现实的AI落地路径。
比如DeepSeek-R1从模型迁移到上线仅用72小时,相比传统方案的2周时间,效率提升显著。
这种成本和效率优势让更多企业能够尝试AI应用,而不需要承担巨额的基础设施投入风险。
CloudMatrix384证明了国产云端方案不只是“能用”,更是在性能和成本效益上都具备竞争优势。
AI基础设施正在重新被定义
CloudMatrix384代表的不只是一台更强的AI超算,还是对“什么是AI基础设施”的重新定义。
技术上,它通过UB颠覆了过往以CPU为中心的层级式设计,将整个超级节点变成了一个统一的计算实体。
面向未来,华为论文中也给出了两条发展路径——一方面继续扩大节点规模,另一方面进行更强力的解耦。
扩大规模容易理解,未来LLM参数规模更大,需要更紧密耦合的计算资源。
而解耦,可以分别从资源和应用两个维度来看。
资源上,CPU和NPU资源物理将分离为专用资源池,从逻辑解耦将走向物理解耦,实现更好的资源利用率。

应用中,大模型的推理过程中内存密集型注意力计算将从解码路径解耦,注意力和专家组件也会分离为独立执行服务。
总之,作者描绘了一个完全解耦、自适应、异构的AI数据中心架构,这种架构将进一步提升可扩展性、灵活性、效率和性能。
未来,计算资源将不再是固定的物理设备,而是可以动态编排的抽象能力。
通过CloudMatrix384和其未来畅想,我们正在见证又一次新的技术迭代,也在见证整个AI数据中心范式的深刻变革。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
🌟 点亮星标 🌟
(文:量子位)