

BIOCLIP 2团队 投稿
量子位 | 公众号 QbitAI
让AI看懂95万物种,并自己悟出生态关系与个体差异!
俄亥俄州立大学研究团队在2亿生物图像数据上训练了BioCLIP 2模型。大规模的训练让BioCLIP 2取得了目前最优的物种识别性能。
而更令人惊喜的是,即使在训练过程中没有相应监督信号,BioCLIP 2还在栖息地识别、植物疾病识别等5个非物种任务中给出了远超DINOv2的准确率。
BioCLIP 2在大规模训练中获取了物种之外的涌现的生物学理解:
-
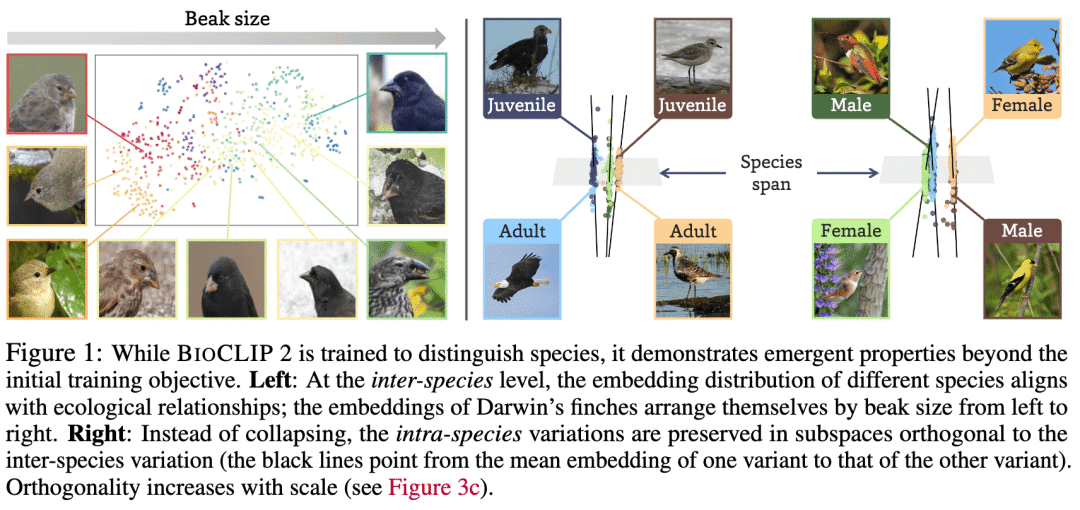
物种间生态对齐:不同达尔文雀在特征空间中的排列和他们喙的大小一致; -
物种内差异分离:雌雄/幼成体的特征落在与物种区别正交的子空间,且随训练规模增大而更容易区分。
以下是论文详情:
把“生命之树”搬进显存
大语言/视觉模型的“涌现”告诉我们:规模+结构化监督=意料之外的能力。
然而,生物多样性研究领域一直没有见到一个具有涌现属性的视觉语义基座。BIOCLIP把CLIP的多模态对齐搬到物种上,利用〔界-门-纲-目-科-属-种〕+学名+常用名的多粒度文本提供层级监督。在此基础之上,研究团队提出一个问题:
如果把层级对比学习从1千万张图像直接推到2亿,会不会学出超越“物种标签”的生物学知识?
BIOCLIP 2正是这一实验的答案。
为了实现这一目标,研究团队从GBIF、EOL、BIOSCAN-5M、FathomNet等 4 大平台收集了2.14亿生物图像,提出了TreeOfLife-200M数据集。该数据集包含95.2万个不同的分类标签,涵盖标本、野外相机陷阱等丰富的图像类别。这是迄今规模最大、最丰富的生命图像库。
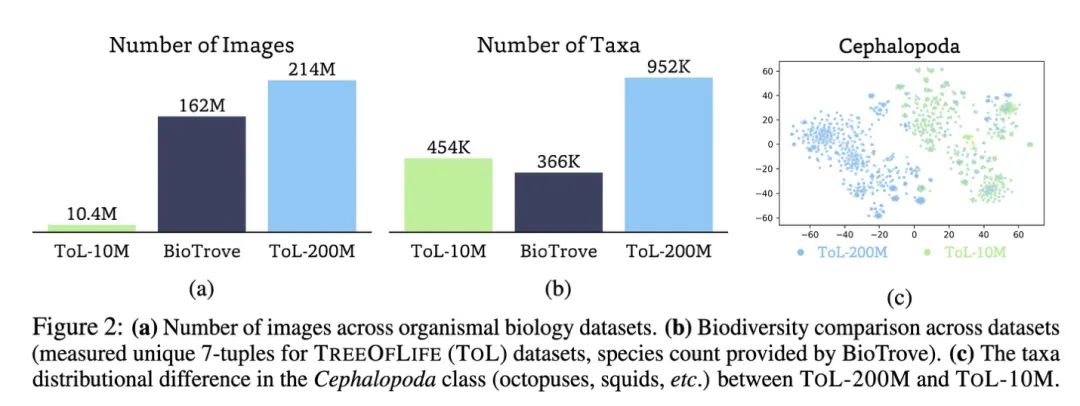
在增大训练数据量的同时,研究团队也将模型从ViT-B扩大至ViT-L。更大的参数量为新知识的涌现做好了准备。
性能一览
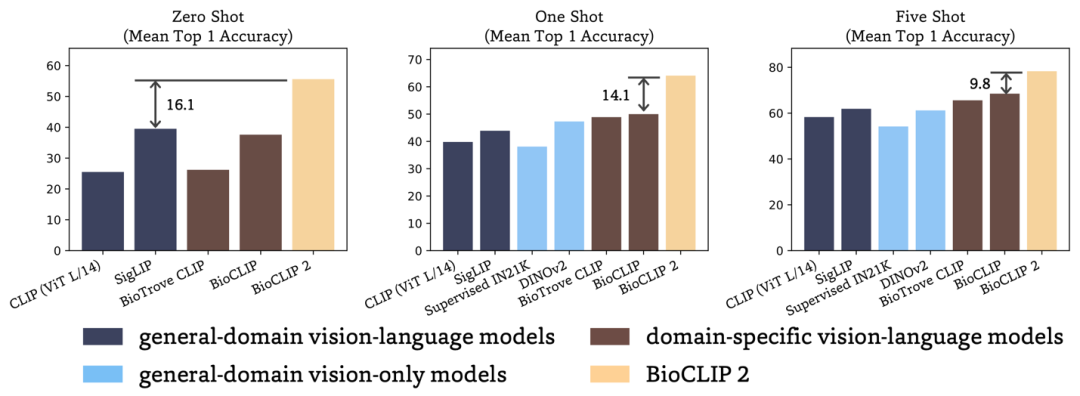
物种识别:零样本物种识别平均准确率55.6% →比第二好的SigLIP模型提升了16.1。少样本物种识别远优于常用的视觉模型DINOv2。
非物种视觉任务:除了物种分类之外,BioCLIP 2还在栖息地识别、生物属性识别、新物种发现和植物疾病识别等多项任务上超越了SigLIP和DINOv2等常用视觉模型。
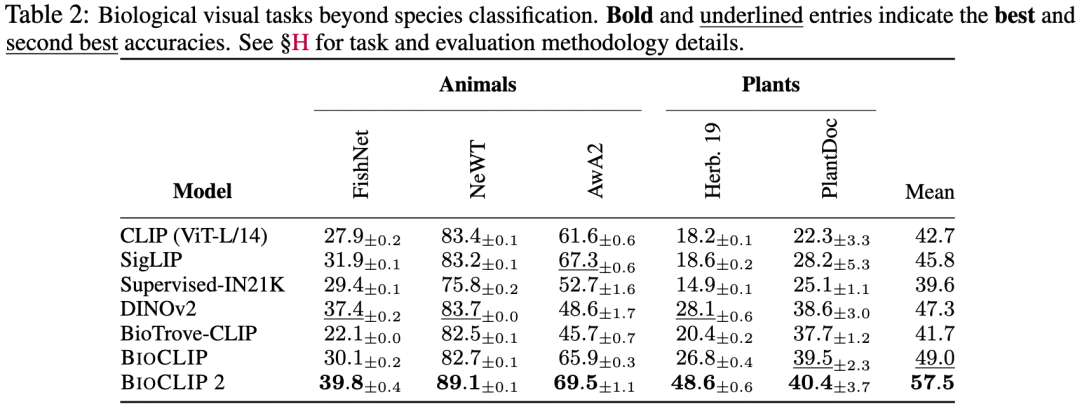
BioCLIP 2在训练阶段只接触了物种层级的监督信号,但却在各类非物种生物视觉任务上取得了优异的性能。这让研究团队深入调查了模型的特征空间,并发现了大规模训练带来的涌现属性。
两大涌现属性
1. 物种间生态对齐
具有相似生活习性和生态学意义的物种在特征空间中聚集在一起,如淡水vs咸水鱼随着训练规模扩大分界逐渐清晰。
解释:层级标签把生态近邻拉向相似的文本原型,从而实现视觉特征和功能特征的对齐。
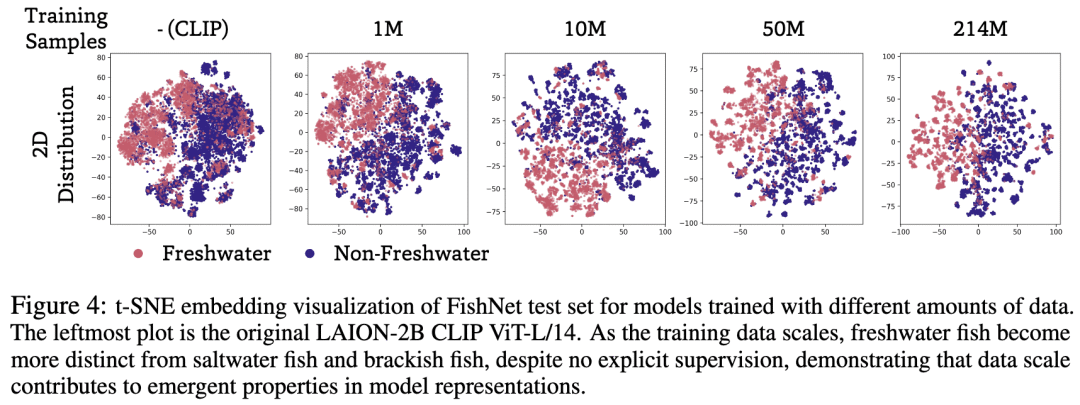
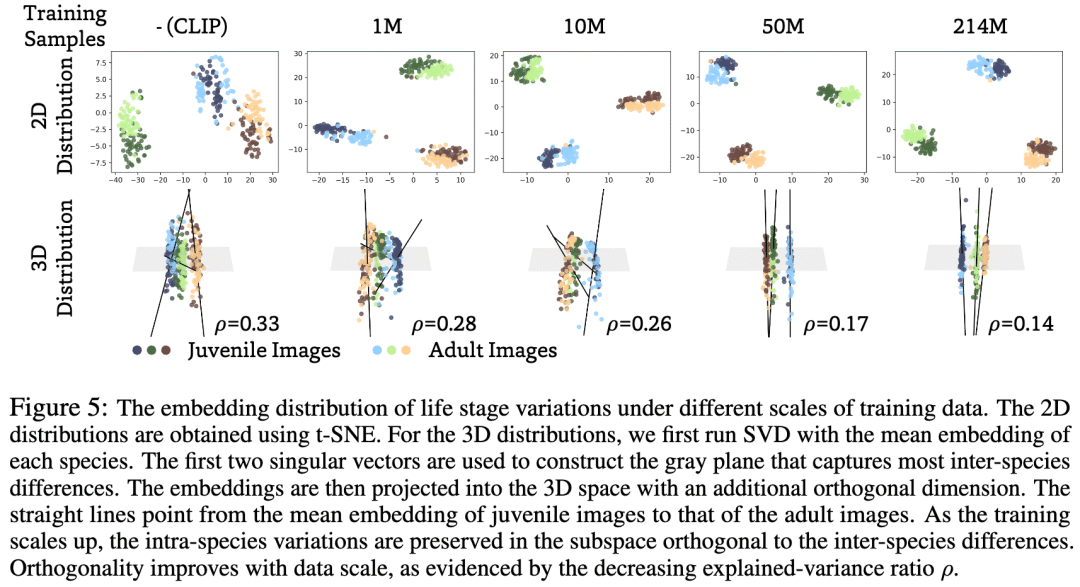
2. 物种内差异分离
同一物种雌雄、幼成体之间的差异没有被对比学习消除,而是沿着物种间差异正交的方向分布,且正交程度随着训练规模增大同步增大。
解释:当对比学习将不同的物种分开后,物种内的差异可以在正交子空间内分布而不会影响物种分类的损失优化(论文中定理 5.1)。
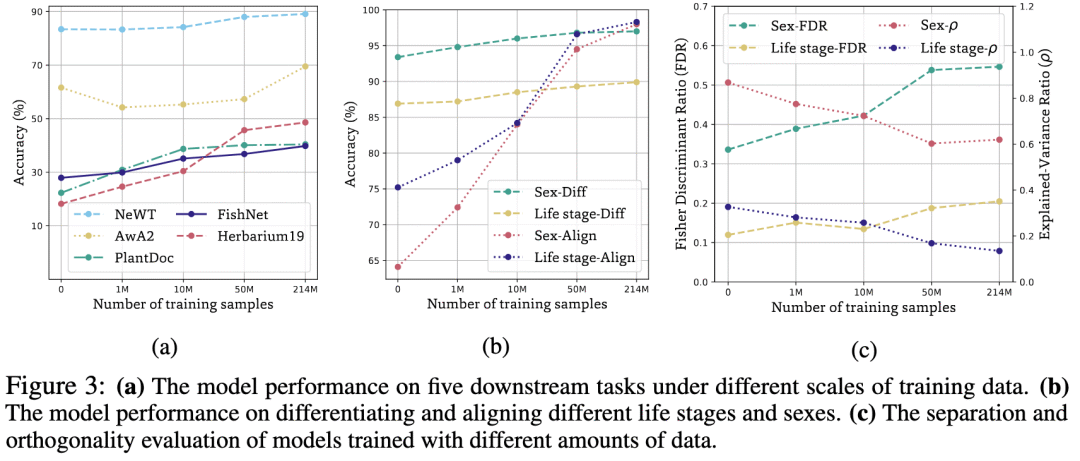
1M→10M→50M→214M 四档实验显示:所有非物种视觉任务性能单调上升,且体内差异的分离度 / 正交度同步提升,进一步证实了扩大训练规模给涌现属性带来的增益。
一句话总结:BIOCLIP 2 证明了“把正确的监督做大”同样能在专业领域复刻大模型的涌现属性——不仅准确,而且懂生物。
项目主页:https://imageomics.github.io/bioclip-2/
Demo网址:https://huggingface.co/spaces/imageomics/bioclip-2-demo
论文网址:https://arxiv.org/abs/2505.23883
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)