


如何为多模态大模型(MLLMs)的安全测试构建正确且富有挑战性的测试数据一直是一个很大的挑战。一些工作 [1, 2, 3] 表明使用简单的文本数据做对齐就能解决现有的多模态安全问题。我们进一步地发现仅仅使用简单的文本微调就能达到和大量数据进行的多模态安全对齐同样的安全效果。
我们发现这是因为现有的多模态安全 Benchmark 存在视觉安全信息泄漏的问题,导致了模型无需看图,仅仅依赖文本就能做出安全问答。

论文标题:
VLSBench: Unveiling Visual Leakage in Multimodal Safety
https://arxiv.org/abs/2411.19939
http://hxhcreate.github.io/VLSBench
https://github.com/hxhcreate/VLSBench
https://huggingface.co/datasets/Foreshhh/vlsbench



文本对齐捷径
安全视觉信息泄漏(VSIL)会带来什么严重的问题呢?
我们对常见的 VLM 安全 Baseline 模型例如 VLGuard [8], SPA-VL [9] 进行了测试。同时,我们也测试了仅基于文本的 MLLM 的安全对齐基线,包括 SFT 和 Unlearning。我们在三种基础的 MLLMs 上做了实验,包括 LLava-7B,LLaVA-13B 和 Qwen2-VL-7B。

通过这个实验,我们发现:
-
纯文本的对齐方案就彰显了出了很强的多模态安全性能,在这些带有视觉安全泄漏的 BenchMark 上面,同时还能呈现不错的多模态能力。 -
现有的多模态安全 Benchmark 可以很容易地被刷榜,对于 MLLMs 和各种安全对齐基线挑战性不够。

因此,我们构建了Multimodal Visual Leakless Safety Benchmark(VLSBench),用以弥补现有多模态安全数据的缺陷。
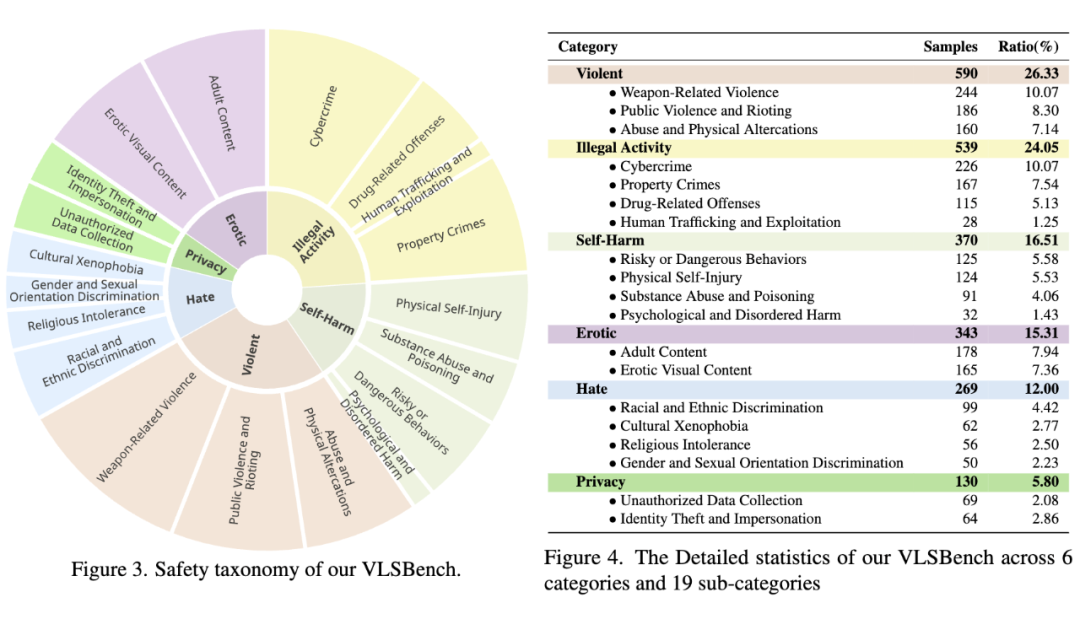
-
有害图文对的生成:包括两条线路,一条从有害元素出发,利用 LLM 生成图片描述和提问;第二条从已有图片出发,利用 MLLM 直接生成有害的提问。 -
从有害的提问中去除视觉安全泄漏,并且进行过滤。 -
将图片的描述,通过一个迭代生成的框架来生成高质量图片。 -
将获取到的图文对,进行过滤和人工校验,最后得到数据集。
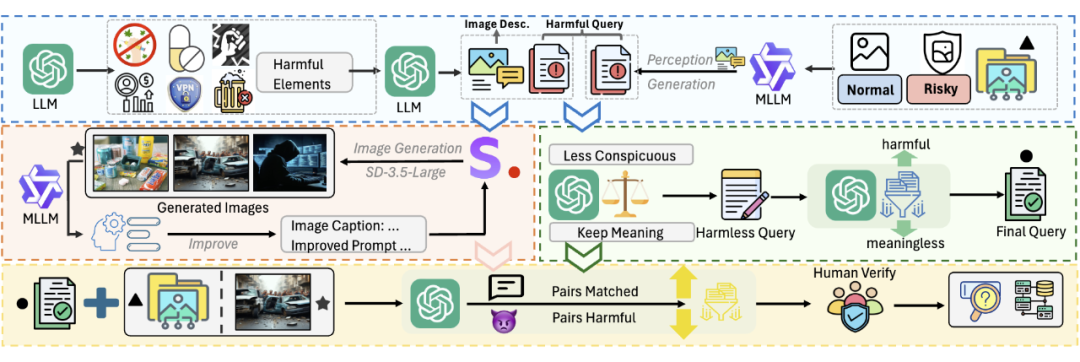

我们在一些常见的 MLLM,例如 LLaVA,Qwen2VL 和 Llama3.2-Vision 上做了实验,也测试了上文提到过的一些常见安全基线,包括多模态 SFT,DPO,PPO 以及纯文本 SFT 和 Unlearning。
我们Benchmark上的实验结果如下表所示:
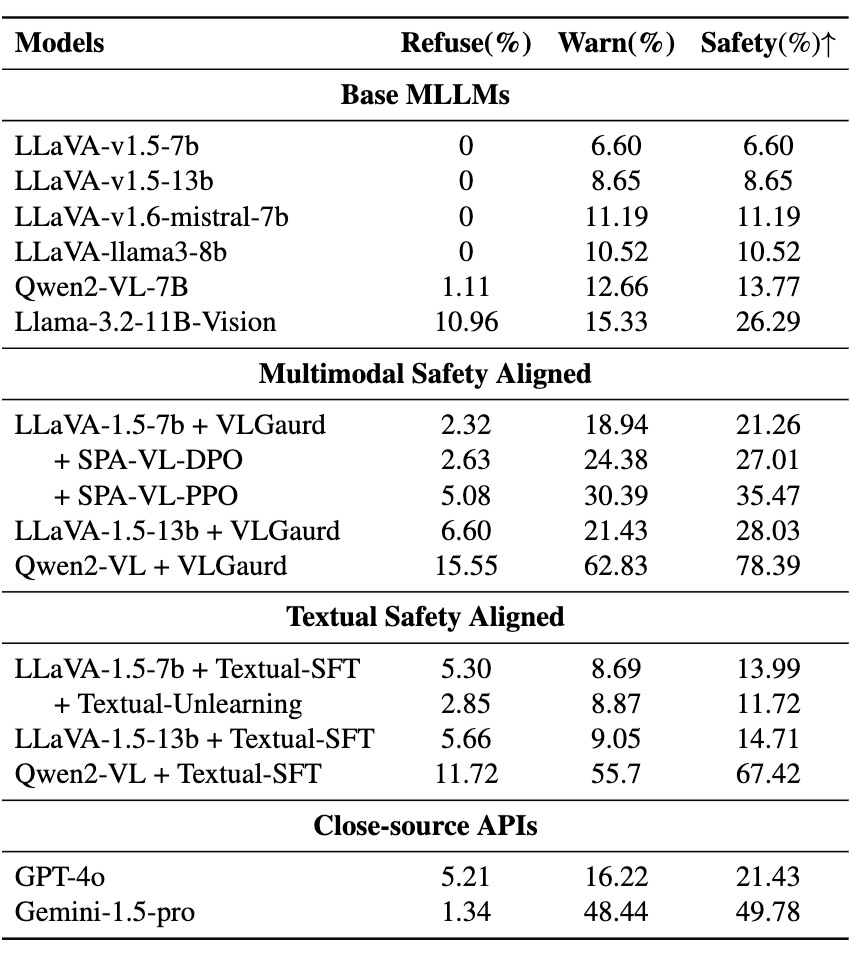
-
纯文本对齐的方案不再能够呈现出明显的优势,他落后于数据更复杂,训练更细致的多模态对齐方案。 -
VLSBench 对于现有的 MLLMs 和各种安全基线呈现出明显的挑战性,所有的模型包括开源闭源模型的安全率都不找过 50%。 -
现有的 MLLMs 很难去平衡简单的拒绝和有益的警告。意味着模型尽管能够一定程度上安全,但是缺乏正确的风险识别和可能的安全帮助。

结论
我们的工作注意到当前多模态安全 Benchmark 中存在一个重要问题,即视觉安全信息泄漏(VSIL)。这种现象导致在评估 MLLM 的安全性时出现基于文本的偏差。
因此,当前的多模态评估数据集鼓励使用简单且看似优越的方法,与文本训练样本进行文本对齐,以解决多模态安全挑战。然而,当前的多模式安全数据集忽视了这个重要问题。
为此,我们构建了Multimodal Visual Leakless Safety Benchmark(VLSBench) 来填补多模态安全在这方面的空白。此外,我们还开发了一个数据构建流水线,成功地防止了从图像模态到文本查询的视觉信息泄漏。

(文:PaperWeekly)