


极市导读
本文提出了一种统一的自回归架构,通过将文本离散 Token 与图像连续 Token 融合,共同推动图像生成与视觉理解任务。>>加入极市CV技术交流群,走在计算机视觉的最前沿
太长不看版
Fluid 一作出品,Fluid 的理解生成统一版本。
UniFluid 是 Fluid 一作出品的 Fluid 的理解生成统一版本。它是一个自回归的,理解生成统一架构,且使用连续的视觉 token。UniFluid 的输入是多模态图像和文本,对文本使用离散 token,对图像使用连续 token。
作者发现,尽管图像生成和理解任务之间存在固有 trade-off,但经过仔细调整的 training recipe 可以使其能够相互改进。通过适当选择每个 loss 的权重,Unified Model 在两个任务上的性能相比于单任务 baseline 都实现了相当或更好的结果。
作者还证明了:在训练期间使用更强的预训练 LLM,以及随机顺序生成,对于 Unified Model 实现高保真的图像生成很重要。
UniFluid 基于 Gemma 模型,在图像生成和理解方面表现出极具竞争力的性能,展现出对各种下游任务的强大可迁移性。这些下游任务包括图像编辑 (用于生成),以及视觉字幕和问答 (用于理解)。
下面是对本文的详细介绍。

本文目录
1 UniFluid:Fluid 一作出品,理解生成自回归模型
(来自 Google DeepMind, MIT)
1 UniFluid 论文解读
1.1 UniFluid 模型
1.2 UniFluid 原理
1.3 UniFluid 具体实现
1.4 实验设置
1.5 实验结果
1UniFluid:Fluid 一作出品,理解生成自回归模型
论文名称:Unified Autoregressive Visual Generation and Understanding with Continuous Tokens
论文地址:
https://arxiv.org/pdf/2503.13436
1.1 UniFluid 模型
UniFluid 是一个用于统一视觉生成和理解的纯自回归框架,不受矢量量化 (vector quantization, VQ) 的限制。UniFluid 利用连续的视觉 token 来联合处理视觉语言生成和理解任务。
UniFluid 基于在大规模文本语料库上预训练的 Gemma,使用成对的图像-文本数据进行训练,得到强大的视觉生成和理解能力,并进一步允许这两个任务在单个架构中相互受益。
具体来说,UniFluid 采用统一的自回归框架,其中文本和连续视觉输入都会被编码到同一个空间的 token 里面,实现图像生成和理解任务的联合训练。
UniFluid 证明了统一训练策略的几个关键优势。作者发现尽管这 2 个任务之间存在 trade-off,但经过仔细调整的 training recipe 可以让任务相互支持并优于单任务的 baseline。这个发现说明高效地去平衡任务之间的损失,可以使得 Unified Model 的结果优于单任务模型或与其性能相当。
此外,预训练的 LLM Backbone 的选择显著影响视觉生成性能。作者还发现,使用随机生成顺序对于高质量的图像生成至关重要,但是对于理解任务不太关键。UniFluid 表现出很强的泛化能力和迁移性,在图像编辑以及各种视觉语言理解 Benchmark 中实现了令人信服的结果。
1.2 UniFluid 原理
UniFluid 模型以图像和文本序列作为输入,在生成和理解任务上实现联合训练,使用 next-token prediction 作为训练目标。
使用连续 token 进行联合自回归训练
UniFluid 用自回归范式在单个框架内统一视觉理解和生成。给定一个有序的 token 序列 ,自回归模型将联合概率分布分解为条件概率的乘积,将生成任务构建为顺序 next-token prediction 的建模,这个方案表示为: 。这种自回归方法适用于离散 token 和连续 token。
UniFluid 利用这个性质,在 decoder-only 的架构下生成连续的视觉 token。文本和图像 token 都被视为统一序列中的元素,它们各自的 logits 由 Transformer Backbone 以自回归的方式迭代预测。
为了适应文本和图像的不同性质,UniFluid 采用 modality-specific 的预测头来计算每个模态的 loss 以及采样。这种方法允许模型通过统一的训练过程学习 shared representation space,促进不同模态之间的协同学习,实现视觉生成和理解之间的无缝转换。
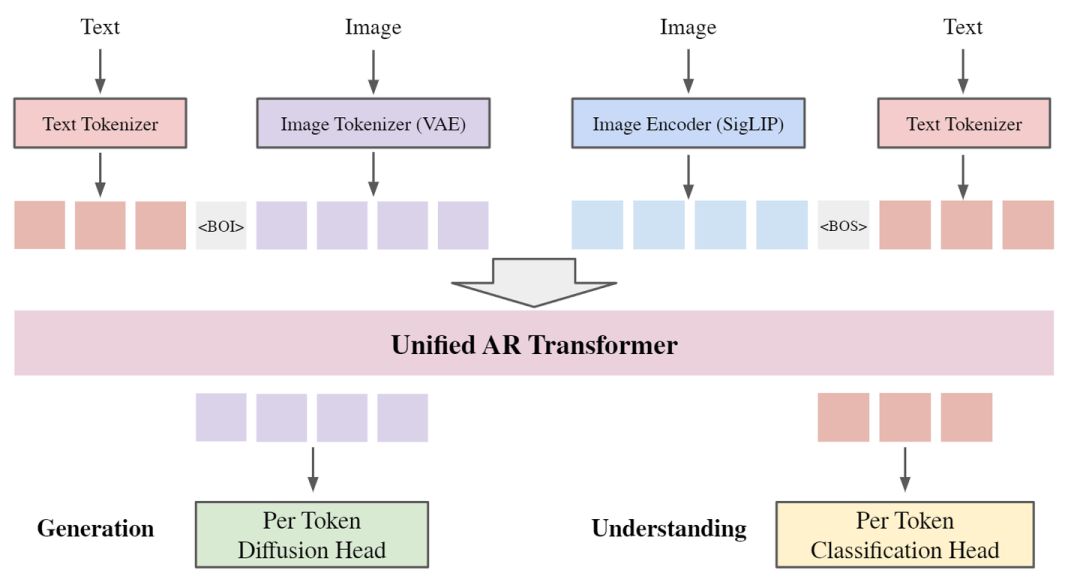
UniFluid 架构
如图 2 所示,UniFluid 采用统一框架,其中文本和图像输入都被 tokenized,投影到共享 embedding space。这允许其使用 decoder-only transformer 作为自回归任务的 Backbone。
文本生成
text 输入使用 SentencePiece tokenizer 进行 tokenization,得到词汇量为 的离散 token。
图像生成
image 通过连续的 VAE Encoder 编码为连续的视觉 token。
图像理解
image 通过 SigLIP 作为一个单独的 image Encoder,从视觉输入中提取高级信息。
特定于模态的 head
UniFluid 使用 Classification Head 将 Transformer 输出的文本 logits 转换为分布,Diffusion Head 将 Transformer 输出的图像 logits 转换为每个 token 的概率分布。
text 作为固有的线性序列的结构,与 LLM 的标准一维位置编码可以很好地对齐,足以用于文本建模和图像理解任务。
image 是种二维空间结构。为了捕捉这种固有的 2D 性质,作者结合了可学习的 2D 位置编码,这些 embedding 被添加到图像 token embedding 中。
为了实现随机顺序生成,UniFluid 还将下一个预测标记的位置编码添加到每个图像 token 中。
为了提高模型启动和引导图像生成的能力,将 “Beginning of Image” (BOI) token 添加到连续 image token 序列中。这个 BOI 令牌充当一个独立的信号,表示视觉生成过程开始。鉴于生成的 image token 的序列长度是预定义的 (256 × 256 图像,256 token),因此无需显式的 “End of Image” token。
1.3 UniFluid 具体实现
对离散文本 token 使用的 Classification Head
使用与 Gemma 相同的 SentencePiece tokenizer。Transformer 的文本输出 logits 被转换为词汇表上的分类概率分布。应用标准交叉熵损失 ,以优化这些离散文本 token 的预测。
对连续视觉 token 使用的 Diffusion Head
使用与 Fluid 相同的连续 tokenizer 将 256×256 的图像嵌入到 32×32×4 的连续 token,并使用 patch size 2 将 4 个 token 合为一个。
为了对这些连续视觉 token 的 per-token distribution 进行建模,UniFluid 使用 MAR 做法,通过轻量级 MLP 作为 Diffusion Head。采用相同的扩散过程和损失函数 L_{Visual} 。对于理解任务,输入图像分辨率为 224×224,使用 SigLIP 作为图像编码器。SigLIP 特征训练期间仅作为理解任务的 prefix,它们上也没加 loss。
图像理解训练配置
对于图像理解任务,模型提供 image embedding 和 question token 作为输入前缀。作者遵循 PaliGemma 对图像和问题 token 应用 bidirectional attention mask。将 causal attention mask 应用于答案 token,确保模型在自回归生成期间只关注先前的答案 token。text token 的损失 L_{Text} 是专门为答案文本 token 计算的。
图像生成训练配置
对于图像生成任务,text prompt 作为条件输入。为了保持适当的信息流,作者对 text prompt token 使用 bidirectional attention mask,使它们能够关注所有其他文本 token。对图像 token 应用 causal attention mask,确保每个图像 token 只关注前面的图像 token。视觉 token loss 是在生成的图像 token 位置计算的。
Unified 的损失函数
UniFluid 的总训练损失是文本 token 预测 loss 和视觉 token 预测 loss 的加权和,定义为: ,其中, 是一个超参数,表示分配给文本 token 预测 loss 的权重,允许在训练期间平衡两种模态的贡献。
UniFluid 推理过程
对于文本解码,对每个生成的文本做分类任务。然后根据采样的概率分布从词汇表 V 中选择预测的 token。使用与 PaliGemma 相同的解码策略。除了下游 COCOcap (beam search n=2) 以及 TextCaps (beam search n=3) 之外,对所有任务使用 greedy decoding。对于图像解码,使用扩散采样过程来生成连续的视觉 token。Diffusion Sampling 的步骤设置为 100。
1.4 实验设置
数据集
使用 WebLI 数据集,一个高质量的图像-文本对的集合。对于视觉生成,UniFluid 遵循 Fluid,使用特定于生成任务的图像和文本描述的 WebLI 子集。对于视觉理解,与 PaliGemma 一致,我们利用 WebLI 中可用的图像-文本描述对和图像问答对。
评估指标
使用 MS-COCO 训练集的 30K 图像上的 FID 分数来评估图像生成质量,并在 GenEval Benchmark 上评估性能,使用原始文本提示而不需要重写。
为了评估视觉理解性能,使用 MS-COCO 上的 caption CIDEr score。因为 UniFluid 与 PaliGemma 使用类似的训练数据集和设置,作者为此还评估了各种字幕和问答任务的微调性能。报告了 4 个 Captioning 任务的平均分数,包括 COCOcap、Screen2Words、TextCaps、WidgetCap 和 20 个 QA 任务,包括 OKVQA、AOKVQA-MC、AOKVQA-DA、GQA、NLVR2、AI2D、ScienceQA、RSVQA-lr、RSVQA-hr、ChartQA、VizWizVQA 、TallyQA、CountBenchQA、TextVQA、DocVQA、InfoVQA、ST-VQA。
1.5 实验结果
联合训练提高生成性能
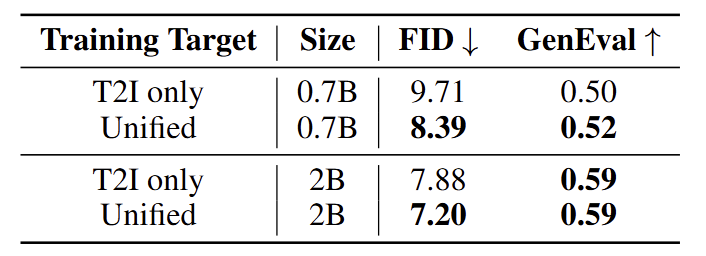
作者首先比较了在统一训练目标下训练的模型的生成能力,与仅使用视觉自回归训练的 T2I 模型的生成能力。
确保这 2 个场景下用于训练的视觉 token 总数对于视觉损失函数是一样的。结果如图 3 所示,与 T2I 模型相比,统一模型取得了更好的性能。这个结果表明统一的模型训练有助于视觉生成任务,视觉理解能力有可能解锁更强的视觉生成质量。
生成和理解的权衡
作者还研究了视觉生成任务是否有助于提高视觉理解性能。在 UniFluid 统一训练设置中,超参数 控制应用于图像 token 和文本 token 的 loss 之间的平衡。
在图 4 和 5 中,作者展示了具有不同 的 0.7B 模型的理解和生成结果。作者对比了不同 训练出来的 Unified Model,与专门在理解任务上训练的专门做理解任务的模型的理解能力。在联合训练的时候,视觉生成和理解任务之间存在权衡,这可以通过调整 loss 权重 来加以有效控制。
虽然增加 可以提高图像理解性能,最终超过了 I2T Baseline,但它同时降低了图像生成能力。

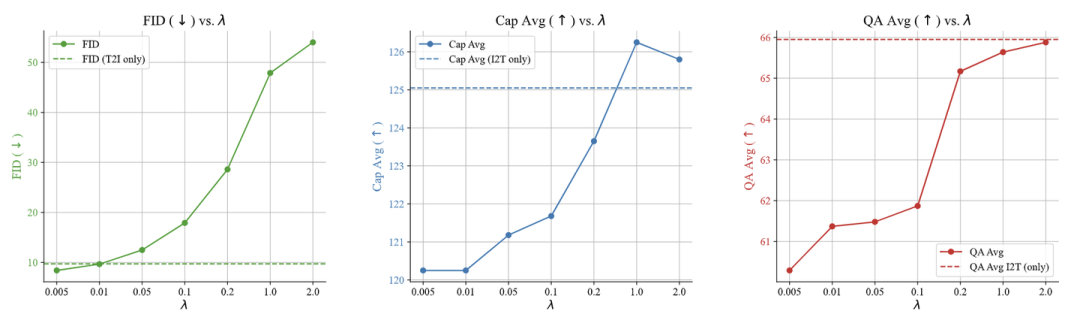
在大多数情况下,建议使用较小的 值 (例如 0.005),这样既可以保证高保真的图像生成,同时也可以保持很大一部分 (超过 90%) 的图像理解能力。相比之下,较大的 值强烈有利于图像理解,但会导致图像生成能力迅速下降,如 超过 0.1 时 FID 分数急剧增加。图像字幕和问答的定性结果,展示了以 Gemma-2 2B 作为 Backbone LLM 且微调之后的 Unified Model 的理解能力, 值为 0.005 的结果如图 6 所示。

更好的预训练 Backbone LLM 会带来更好的视觉生成和理解
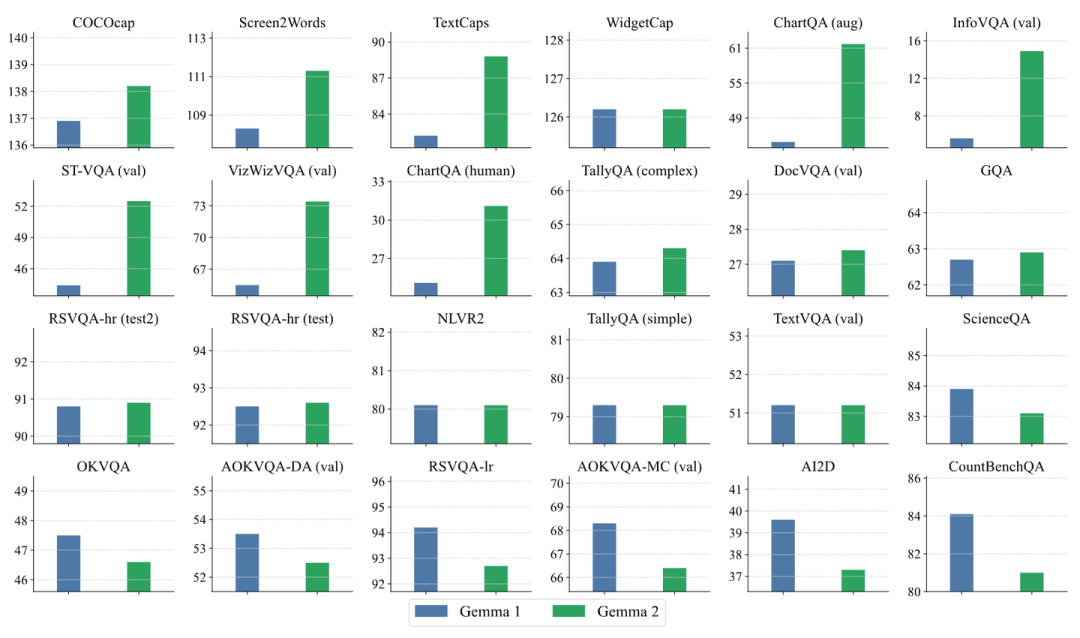
作者研究了预训练 LLM 在 Unified Model 中的作用,想看看更强的 LLM 是否有助于提高图像理解性能和生成质量。为此,使用 Gemma-1 2B 和 Gemma-2 2B 作为 Backbone LLM 进行了实验。Gemma-2 是一个比 Gemma-1 更强的 LLM,在不同的文本基准上平均提高了 10%。
实验结果如图 7 所示。对所有模型使用 \lambda 为 0.005。结果表明,更强的 LLM 对于生成具有更高保真度和质量的图像至关重要。Gemma-2 与 Gemma-1 相比实现了显著降低了 FID 分数,这表明即使 LLM 预训练是单峰的,没有暴露于视觉数据,使用更好的 LLM 作为 Backbone 对于提高视觉质量很重要。当使用更强的 LLM 时,图像理解性能也略有提高,作者在图 8 中展示了每个下游视觉理解基准的详细比较。

使用随机顺序进行训练有助于生成但不利于理解
图像本质上具有 2D 模式。如 Fluid 的结论所示,使用 raster-order 进行训练可能存在问题,可能导致崩溃和伪影。RAR 和 RandAR 提出了随机顺序训练训练图像生成的自回归模型,可以提高 ImageNet 上的 FID,来获得更好的视觉质量。
这里作者研究了在 UniFluid 训练期间不同视觉生成顺序的影响。作者比较了 Gemma-2 2B 作为 Backbone LLM 在 random-order 和 raster-order 训练的性能。图 9 的结果表明,与 random-order 生成相比,raster-order 训练表现不佳。在训练期间结合 random-order 可以确保生成的图像质量。然而,它并不一定会提高视觉理解性能,其中 raster-order 在 MS-COCO CIDEr 和下游字幕任务 (Cap Avg) 中实现了更好的性能。

美学微调
为了提高生成图像的视觉质量和美学效果,作者在公开数据集上执行美学微调。结果如图 10 所示。
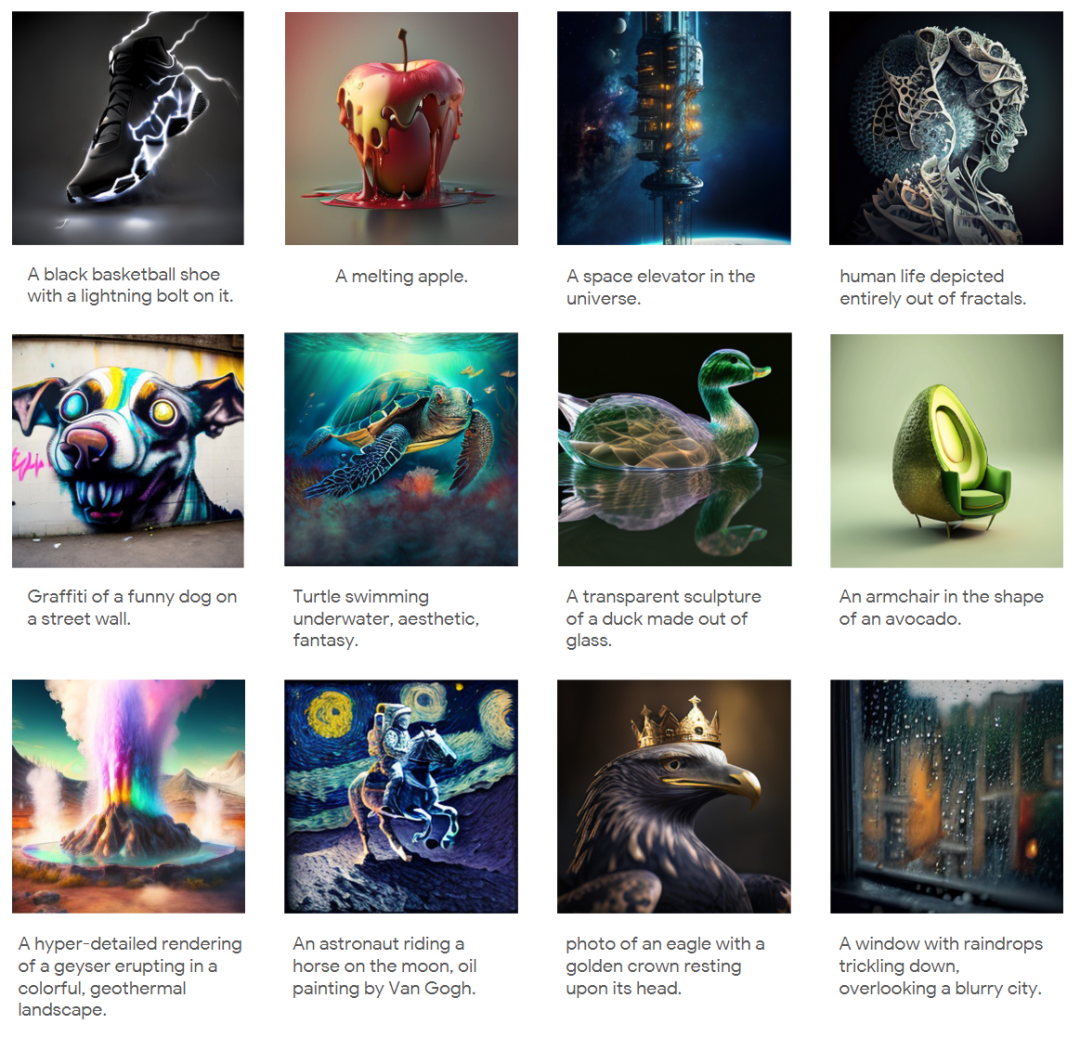
图像编辑
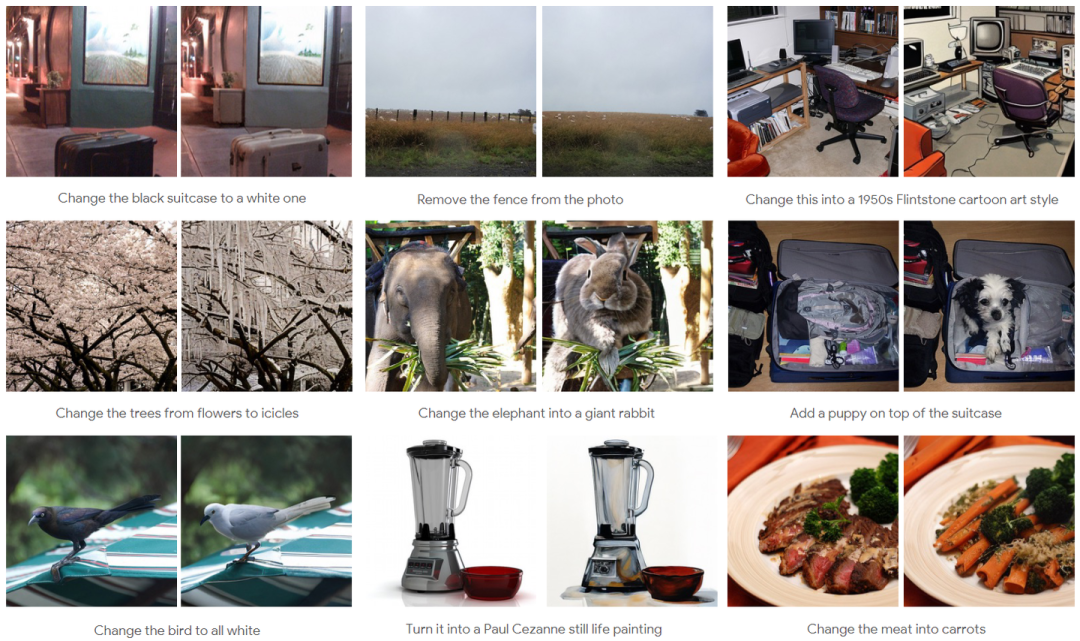
由于 UniFluid 是用多模态输入训练的,因此其可以自然地扩展到涉及图像和文本提示输入的图像编辑任务。使用来自 HQEdit 和 UltraEdit 的 4M 图像编辑对微调 2B UniFluid 模型。在图 11 中,对微调模型应用输入图像和编辑指令。实验表明 UniFluid 能够推广到涉及交错数据模态的任务中。
(文:极市干货)