


极市导读
ICCV 2025录用结果公布,腾讯优图实验室共有8篇论文入选,涵盖风格化人脸识别、AI生成图像检测、多模态大语言模型等前沿方向 >>加入极市CV技术交流群,走在计算机视觉的最前沿
近日,第20届ICCV国际计算机视觉大会(The 20th IEEE/CVF International Conference on Computer Vision (ICCV 2025))公布了论文录用结果。ICCV作为计算机视觉领域的顶级学术会议,每两年举办一次,与国际计算机视觉与模式识别会议(CVPR)、欧洲计算机视觉国际会议(ECCV)并称为计算机视觉领域的三大顶级会议,具有极高的学术影响力。ICCV 2025 将于 10 月 19日至 25 日在美国夏威夷举行。ICCV 2025大会共收到11239份有效投稿,刷新历史记录,经过严格评审,最终仅接受2698篇论文,录用率为24%。今年,腾讯优图实验室共有8篇论文入选ICCV 2025,内容涵盖风格化人脸识别、AI生成图像检测、多模态大语言模型等方向,展现了优图实验室在人工智能领域的技术能力与创新突破。
以下为入选论文摘要:
1 Stylized -Face:用于风格化人脸识别的数据集
Stylized-Face: A Million-level Stylized Face Dataset for Face Recognition
Zhengyuan Peng(上海交通大学/优图实习生),Jianqing Xu,Yuge Huang,Jinkun Hao(上海交通大学), Shouhong Ding,Zhizhong Zhang(上海交通大学), Xin Tan(上海交通大学),Lizhuang Ma(上海交通大学)
风格化人脸识别的任务是识别不同风格领域(例如动漫、绘画、赛博朋克风格)中具有相同 ID 的生成人脸。这一新兴领域在生成图像治理中扮演着至关重要的角色,其主要目标是:识别风格化人脸的 ID 信息,以检测潜在的肖像权侵权行为。尽管风格化人脸识别至关重要,但由于缺乏大规模、风格多样化的数据集,其发展一直受到阻碍。为了弥补这一缺陷,我们推出了 Stylized-Face 数据集,这是第一个专门为风格化人脸识别设计的数据集。Stylized-Face数据集包含 460 万张图像,涵盖 6.2 万个 ID,旨在提升模型在风格化人脸识别任务中的表现。为了确保如此大规模的数据质量,我们实施了一套半自动化的大规模数据清理流程。基于 Stylized-Face 数据集,我们建立了三个基准测试集,用于评估识别模型在不同场景下的鲁棒性和泛化能力,包括分布内性能、跨方法泛化和跨风格泛化,以应对风格化人脸识别的关键挑战。实验结果表明,在 Stylized-Face 数据集上训练的模型在风格化人脸识别性能(FAR=1e-4 时 TAR 提升 15.9%)和泛化能力(跨方法泛化时 FAR=1e-3 时 TAR 提升 13.3%)方面均取得了显著提升。

2 AIGI-Holmes:基于多模态大语言模型的可解释及可泛化的AI生成图像检测
AIGI-Holmes: Towards Explainable and Generalizable AI-Generated Image Detection via Multimodal Large Language Models
Ziyin Zhou(厦门大学/优图实习生),Yunpeng Luo,Yuanchen Wu,Ke Sun(厦门大学),Jiayi Ji(厦门大学),Ke Yan,Shouhong Ding,Xiaoshuai Sun(厦门大学),Yunsheng Wu,Rongrong Ji(厦门大学)
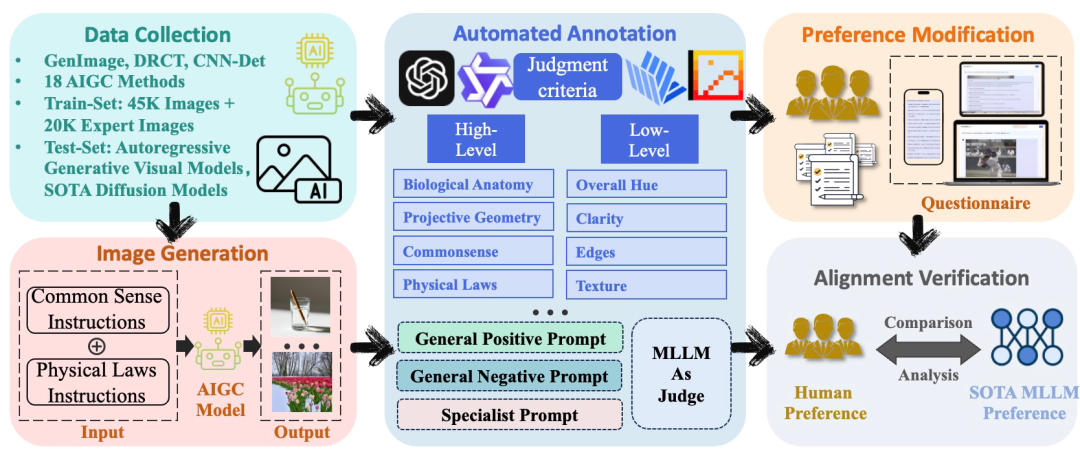
随着AI生成内容(AIGC)技术的飞速发展,高度逼真的AI生成图像(AIGI)被广泛滥用,用于传播虚假信息,严重威胁公共信息安全。尽管现有的AI生成图像检测技术普遍效果良好,但仍存在两大关键缺陷:一是缺乏可被人工验证的解释依据;二是对新一代基于多模态大模型自回归范式生成的图像存在可能的泛化能力不足问题。为应对这些挑战,本文构建了大规模综合数据集 Holmes-Set。该数据集包含两个核心部分:提供AI图像判定解释的指令微调数据集 Holmes-SFTSet,以及用于人类对齐偏好的数据集 Holmes-DPOSet。在数据标注方面,本文创新性地提出了“多专家评审机制”。该机制通过结构化多模态大语言模型(MLLM)的解释来增强数据生成,并采用跨模型评估、专家缺陷过滤与人类偏好修正相结合的方式实现严格的质量管控。同时,本文提出了一个名为 Holmes Pipeline 的三阶段训练框架:首先进行视觉专家预训练,其次进行监督微调(SFT),最后进行直接偏好优化(DPO)。该框架旨在使多模态大语言模型(MLLM)适配AI生成图像检测任务,生成兼具可验证性和人类认知对齐的解释,最终训练出 AIGI-Holmes 模型。在推理阶段,本文还引入了协同解码策略,融合视觉专家模型的感知能力与MLLM的语义推理能力,以进一步增强模型在新数据上的泛化能力。在三大基准测试上进行的广泛实验,充分验证了 AIGI-Holmes 模型的有效性。
3 Fuse Before Transfer: 面向异构蒸馏的知识融合算法
Fuse Before Transfer: Knowledge Fusion for Heterogeneous Distillation
Guopeng Li(武汉大学/优图实习生), Qiang Wang,Ke Yan,Shouhong Ding,Yuan Gao(武汉大学),Gui-Song Xia(武汉大学)
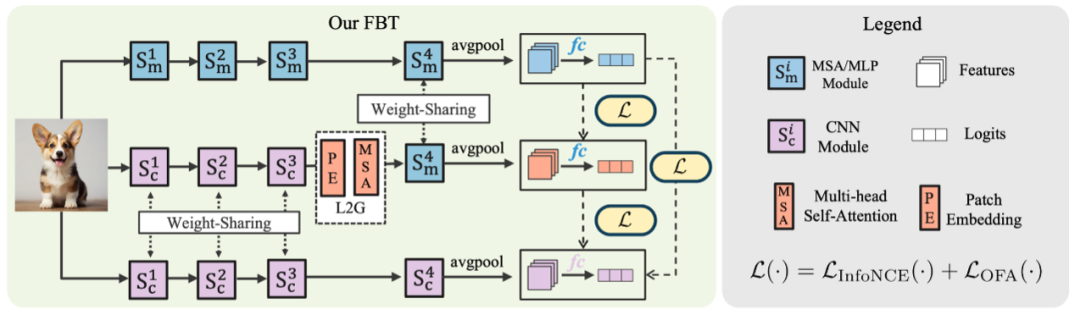
当前大多数知识蒸馏(KD)方法受限于Teacher与Student的结构,往往在同构模型中表现优异,而在异构网络之间效果较差。在实际应用中,跨结构知识蒸馏(CAKD)可以将任意结构Teacher的知识迁移至指定的Student,从而显著提升知识蒸馏的潜力与灵活性。然而,异构模型间固有的归纳偏置差异会导致显著的特征鸿沟,这给CAKD带来了巨大挑战。为此,我们提出在Teacher知识迁移前进行异构知识融合。该融合机制通过直接整合师生模型的卷积模块、注意力模块和MLP模块来统一异构模型的归纳偏置。进一步研究发现,异构特征呈现空间分布异质性,传统逐像素MSE损失有效性不足。因此,我们提出采用空间不敏感的InfoNCE损失,在空间平滑处理后进行特征对齐。本方法在CIFAR-100和ImageNet-1K数据集上,针对CNN、ViT、MLP的同构模型及任意异构组合进行了全面评估。蒸馏模型性能提升显著,在CIFAR-100上最高增益达11.47%,在ImageNet-1K上达3.67%。
4 UniCombine:基于扩散模型的统一多条件控制生成算法
UniCombine: Unified Multi-Conditional Combination with Diffusion Transformer
Haoxuan Wang*(复旦/优图实习生),Jinlong Peng*,Qingdong He,Hao Yang(上交),Ying Jin(复旦),Jiafu Wu,Xiaobin Hu,Yanjie Pan(复旦), Zhenye Gan,Mingmin Chi(复旦), Bo Peng(上海海洋大学),Yabiao Wang
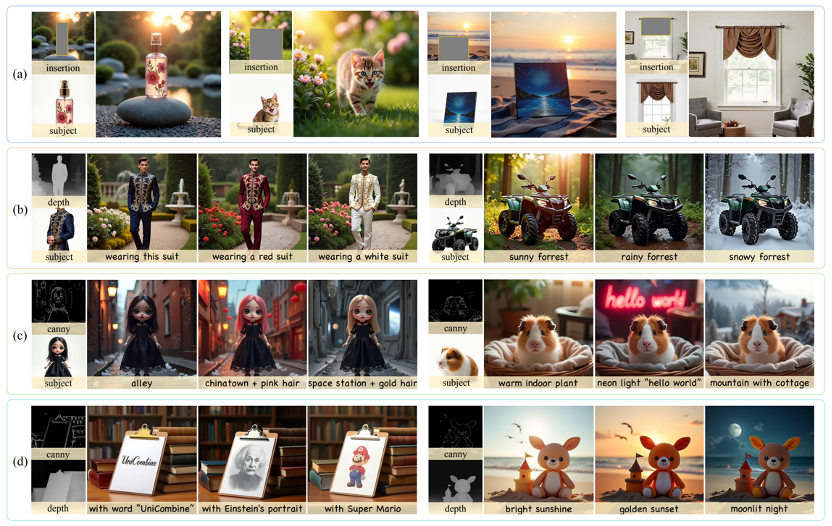
随着扩散模型在图像生成领域的快速发展,对更强大且灵活的可控框架的需求日益增长。尽管现有方法能够超越文本提示进行引导生成,但如何有效结合多种条件输入并保持对所有条件的一致性仍然是一个未解决的挑战。为此,我们提出了UniCombine,一种基于DiT的多条件可控生成框架,能够处理包括但不限于文本提示、空间映射和主体图像在内的任意条件组合。具体而言,我们引入了一种新颖的条件MMDiT注意力机制,并结合可训练的LoRA模块,构建了training-free和training-based两种版本。此外,我们构建并了首个针对多条件组合式生成任务设计的数据集SubjectSpatial200K,涵盖了主体驱动和空间对齐条件。大量多条件生成的实验结果表明,我们的方法具有出色的通用性和强大的能力,达到了最先进的性能水平。
论文链接:
https://arxiv.org/pdf/2503.09277
5 LLaVA-KD:一种蒸馏多模态大语言模型的框架
LLaVA-KD: A Framework of Distilling Multimodal Large Language Models
Yuxuan Cai*(华科/优图实习生),Jiangning Zhang*,Haoyang He(浙大),Xinwei He (华农),Ao Tong (华科),Zhenye Gan,Chengjie Wang(共同通讯),Xuezhucun(浙大),Yong Liu(浙大),Xiang Bai(华科)
大语言模型(LLMs)的成功推动了多模态大语言模型(MLLMs)的发展,旨在实现视觉与语言的统一理解。然而,大规模多模态大语言模型(
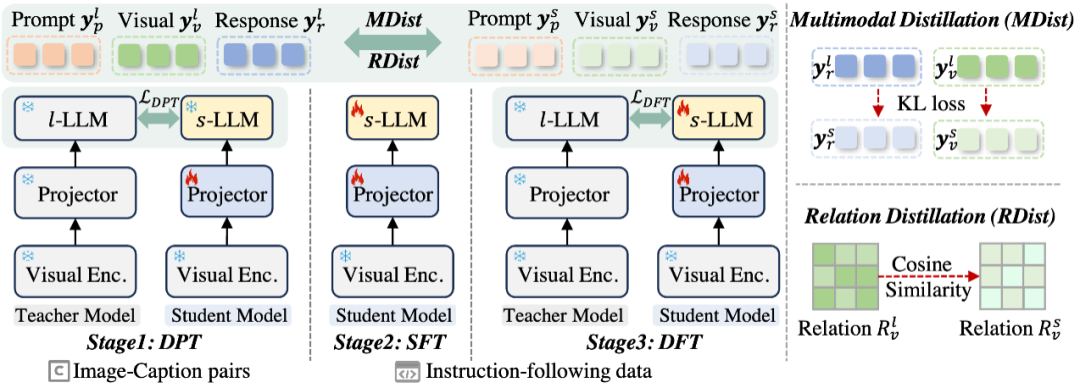
为缓解这一矛盾,我们提出了创新的LLaVA-KD框架,实现知识从
-
多模态蒸馏(MDist):跨视觉和语言模态迁移教师模型的鲁棒表征
-
关系蒸馏(RDist):迁移教师模型捕捉视觉标记间关系的能力
此外,我们设计了三阶段训练范式以充分释放蒸馏策略的潜力:
-
蒸馏预训练:强化
-MLLMs中视觉-语言表征的对齐 -
监督微调:赋予
-MLLMs多模态理解能力 -
蒸馏微调:精调
-MLLMs的知识表征该方法在保持模型架构不变的前提下,显著提升了 -MLLMs的性能。大量实验与消融研究验证了各组件的有效性。
论文链接:
https://arxiv.org/abs/2410.16236
6 基于对抗增强的掌纹识别的算法
Unified Adversarial Augmentation for Improving Palmprint Recognition
Jianlong Jin*(合肥工业大学/优图实习生),Chenglong Zhao*,Ruixin Zhang,Sheng Shang(合肥工业大学/优图实习生),Yang Zhao(合肥工业大学),Jun Wang(微信支付33号实验室),Jingyun Zhang(微信支付33号实验室),Shouhong Ding,Wei Jia(合肥工业大学),Yunsheng Wu
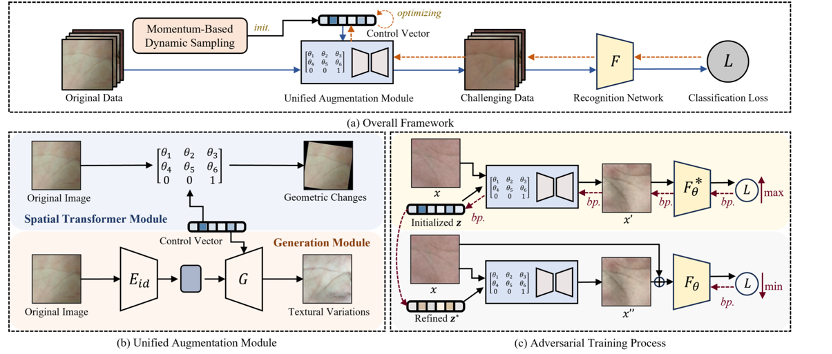
当前掌纹识别模型在受限数据集上表现优异,但在处理存在几何形变和纹理退化的挑战性掌纹样本时仍存在显著局限。数据增强技术虽被广泛采用以提升模型泛化能力,但现有增强方法难以在保持身份一致性的同时生成具有掌纹特异性的多样化样本,导致性能提升有限。为此,我们提出一个统一的对抗性增强框架:首先采用对抗训练范式进行掌纹识别,通过融入识别网络的反馈来优化生成具有挑战性的增强样本;其次同步增强几何形变与纹理变异,具体采用空间变换模块和新型身份保持模块,在维持身份一致性的前提下合成具有丰富纹理变化的掌纹图像;进一步提出动态采样策略以实现更高效的对抗增强。大量实验表明,该方法在挑战性和受限掌纹数据集上均展现出优越性能。
7 从增强到理解:基于语义一致的暗光视觉通用理解增强方法
From Enhancement to Understanding: Build a Generalized Bridge for Low-light Vision via Semantically Consistent Unsupervised Fine-tuning
Sen Wang*(华东师范大学/优图实习生),Shao Zeng*,Tianjun Gu(华东师范大学),Zhizhong Zhang(华东师范大学),Ruixin Zhang,Shouhong Ding,Jingyun Zhang(微信支付33号实验室),Jun Wang(微信支付33号实验室),Xin Tan(华东师范大学),Yuan Xie(华东师范大学),Lizhuang Ma(华东师范大学)
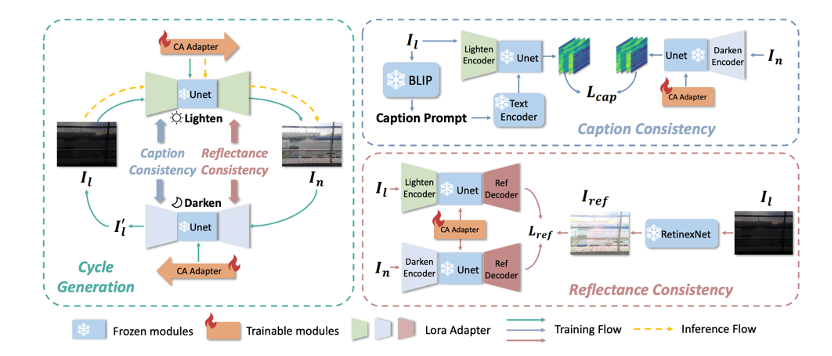
暗光视觉任务中通常将low-level增强和high-level视觉理解分开处理。暗光增强任务旨在提升图像质量以辅助下游任务,但现有方法只依赖物理或几何先验,限制了其泛化能力。同时,现有方法的评估主要关注视觉质量,而忽略了下游任务的表现。而暗光视觉理解任务受到标注数据稀缺的限制,通常使用特定任务的域适应方法,缺乏可扩展性。为了解决这些挑战,我们构建了暗光增强与理解之间的通用桥梁,称为通用理解增强,旨在同时提高方法的泛化能力和可扩展性。为了应对暗光退化的多样化成因,我们利用预训练生成扩散模型对图像进行优化,实现零样本的泛化性能。在此基础上,我们提出了语义一致的无监督微调方法。具体而言,为克服文本提示的局限性,我们引入了一种感知光照的图像提示用于显式引导图像生成,并提出了一种循环注意力适配器以最大化其语义潜力。为缓解无监督训练中语义退化的问题,我们进一步提出了“图像描述一致性”和“反射一致性”策略,以学习高级语义和图像级的空间语义。大量实验证明,我们的方法能够在图像质量增强和通用理解增强(包括分类、检测和分割任务)任务中均超过现有方法,达到最先进的性能水平。
8 OracleFusion:基于语义结构可视化辅助理解甲骨文
OracleFusion: Assisting the Decipherment of Oracle Bone Script with Structurally Constrained Semantic Typography
Caoshuo Li(厦大/优图实习生),Zengmao Ding(安阳师院),Xiaobin Hu,Bang Li(安阳师院),Donghao Luo,AndyPianWu(数字文化实验室),Chaoyang Wang(数字文化实验室),Chengjie Wang,Taisong Jin(厦大),SevenShu(数字文化实验室),Yunsheng Wu,Yongge Liu(安阳师院),Rongrong Ji(厦大)
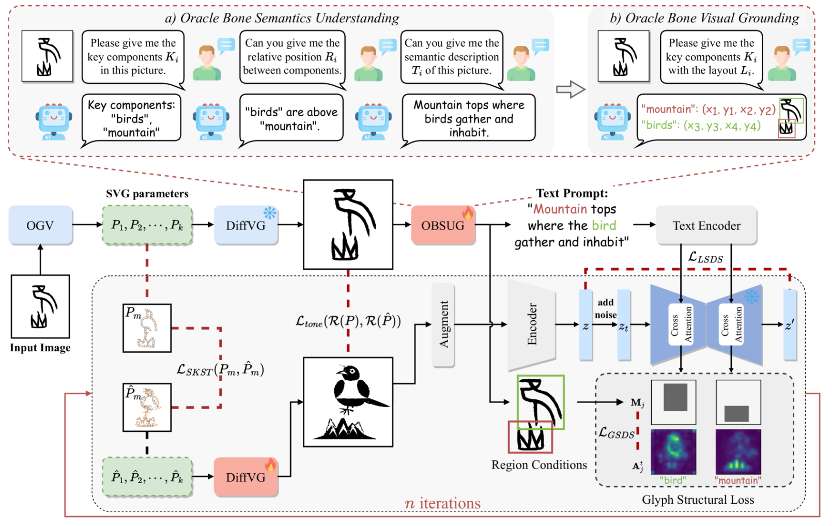
甲骨文是最早的古代语言之一,蕴含着古代文明的文化记录。尽管已发现约 4,500 个甲骨文字符,但只有约 1,600 个被破译。其余未破译的字符结构复杂、意象抽象,对解读构成重大挑战。为了应对这些挑战,本文提出了一种新颖的两阶段语义排版框架 OracleFusion 。在第一阶段,该方法利用具有增强空间感知推理 (SAR) 的多模态大型语言模型 (MLLM) 来分析甲骨文字符的字形结构并对关键部件进行视觉定位。在第二阶段,我们引入甲骨文结构矢量融合 ( SOVF ),结合字形结构约束和字形维持约束,以确保准确生成语义丰富的矢量字体。这种方法保持了字形结构的客观完整性,提供了视觉增强的表示,以帮助专家破译甲骨文。大量的定性和定量实验表明,OracleFusion 在语义、视觉吸引力和字形维护方面均超越了最先进的基线模型,显著提升了可读性和美观度。此外,OracleFusion 还能为未见的甲骨文字符提供专家级的洞察,使其成为推进甲骨文释读的有效工具。
论文链接:
https://arxiv.org/abs/2506.21101
(文:极市干货)