


时隔 5 个月,Grok 终于再次“更新换代”。
这次,xAI 不仅直接跳过了 Grok 3.5,而且并非只发布一款模型。今天刚发布的是通用模型 Grok 4,能够处理常规任务并进行对话。接下来的三个月时间里,xAI 将陆续发布专为编码任务设计的 Coding Model、多模态代理 Multi-modal Agent 和视频生成模型 Video Generation Model。

目前,Grok 4 已上线,提供三个订阅版本,包括免费的基础版、每月 30 美元的 Supergrok 和每月 300 美元的 Supergrok Heavy。SuperGrok Heavy 订阅用户可提前体验 xAI 计划在未来几个月推出的一些新产品。
“在所有学科领域,Grok 4 的智能水平都超过了博士生”。发布会上,马斯克吹嘘道,“我们已经没有测试题可问了,现实是终极的推理测试”,他补充说:“有时,它可能缺乏常识,而且它还没有发明新技术或发现新的物理学,但这只是时间问题。”
直播现场,马斯克身着皮夹克,在 xAI 团队成员的陪同下,详细演示了这款新模型。值得注意的是,距离产品发布仅数小时前,xAI 的首席科学家 Igor Babuschkin 辞职了。在一张成员合照中可以看到,xAI 团队 70% 以上都是亚洲人。

其实这场发布早在周一就被马斯克在 X 上预热了,当时他发文表示将于 7 月 9 日 8 时(北京时间 7 月 10 日上午 11 点)在 X 平台通过直播发布其人工智能聊天机器人最新版本 Grok 4。
马斯克虽然没有爽约,但直播开始时间比计划晚了近一小时。
开场,马斯克就表示,Grok 4 性能非常强大,这系列包含两个版本:Grok 4 和 Grok 4 Heavy。两款模型都是纯推理模型,没有非推理模式。
-
Grok 4 每次在 SAT 考试中都能取得满分,而且事先从未见过考题。
-
Grok 4 在 GRE 考试的各个学科中都能取得近乎满分的成绩。
-
Grok 4 在所有学科上的表现几乎同时超过了绝大多数研究生。
-
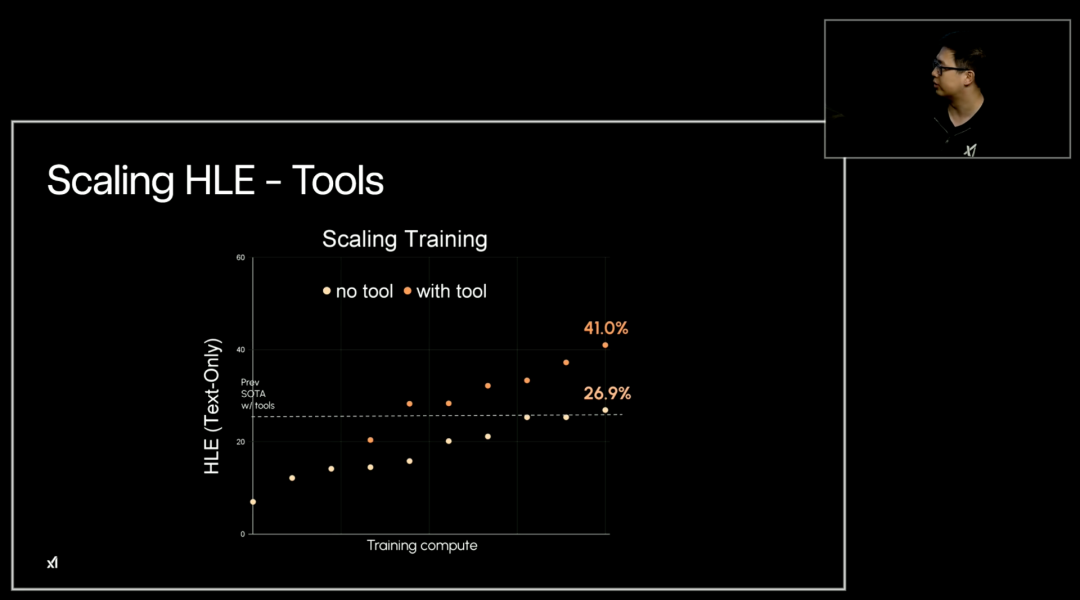
Grok 4 在“人类终极考试”中得分达 50.7%(使用测试时计算、工具和多个并行智能体)
与早期版本的 Grok 一样,Grok 4 搭载了 “深度搜索” 工具,可从网络(尤其是马斯克旗下的 X 平台)抓取实时数据。这意味着 Grok 能在对话中直接提供最新结果,无需额外打开标签页或浏览器。
Grok 4 最大的差异化优势之一是对互联网文化的理解。Grok 4 经过调校,能高精度解读 meme、俚语和幽默内容,有望成为目前最 “懂网络” 的 AI 助手之一。“这款新模型有时可能缺乏常识,也尚未能发明新技术或发现新的物理学知识,但这都只是时间问题,”马斯克表示。
Grok 4 预计不仅支持文本,还将支持图像,甚至可能支持视频 —— 马斯克曾坦言这是他们目前的一大短板。更强的多模态能力将使其更接近与 OpenAI 的 GPT-5o 和谷歌的 Gemini 2.5 Pro 的竞争水平。未来,Grok 4 或还有望支持视频处理。
另据介绍,Grok 4 可通过多个平台使用,确保广大受众的可访问性:
-
xAI 控制台:Grok 4(型号 grok-4-0629)可通过 xAI 的 API 访问,主要面向开发者和企业用户。
-
Grok.com 与 X 平台:用户可在 grok.com、x.com 以及 Grok 的 iOS 和 Android 应用中使用 Grok 4,免费访问但有使用额度限制。
-
SuperGrok 订阅服务:grok.com 上的付费套餐为 Grok 4 提供比免费版更高的使用额度。定价详情请查阅 xAI 官方网站。
-
X Premium 订阅:x.com 的订阅用户可享受 Grok 4 的增强访问权限。定价信息可在 X Premium 支持页面查询。
Grok 4 Heavy 是该公司性能更强大的“多智能体版本”。马斯克声称,Grok 4 Heavy 会生成多个智能体同时处理一个问题,然后它们会“像一个学习小组”一样比较各自的工作,以找到最佳答案。
基准测试 KO 一众领先模型,
编码水平超越 Cursor?
“在多项基准测试中,Grok 4 都展现出前沿水平。”
xAI 声称,Grok 4 在无需“工具”的情况下,在“人类的最后考试”(Humanity’s Last Exam)中获得了 25.4% 的准确率,超过了谷歌 Gemini 2.5 Pro(21.6%)和 OpenAI o3(high)(21%)。(“人类的最后考试”是一项极具挑战性的测试,旨在衡量 AI 回答数千道众包问题的能力,涵盖数学、人文和自然科学等学科。)
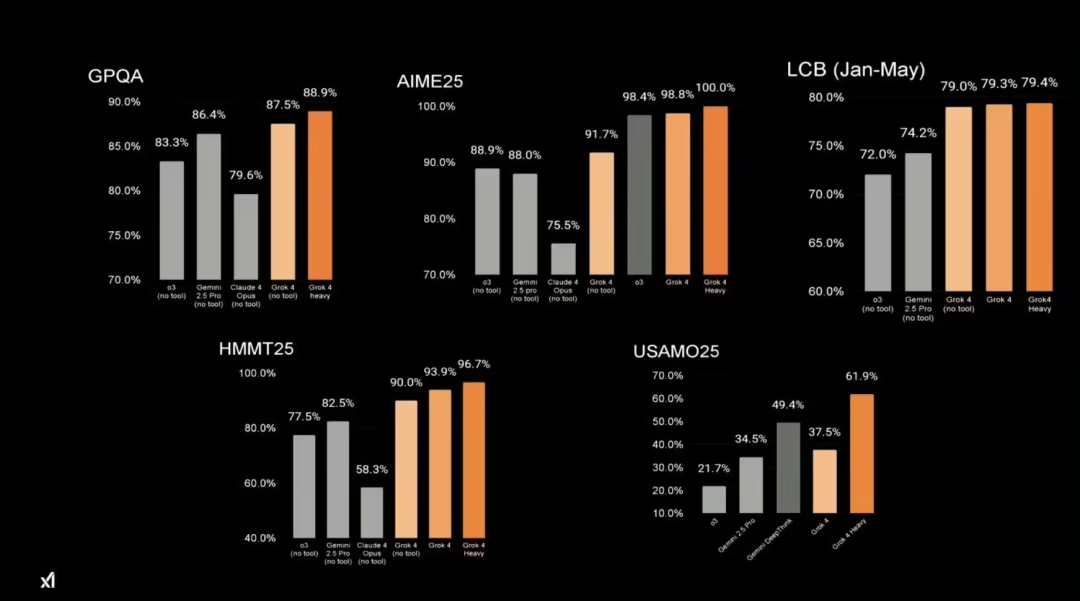
xAI 还表示,配备“工具”的 Grok 4 Heavy 能够获得 44.4% 的得分,优于配备工具的 Gemini 2.5 Pro,后者得分为 26.9%。
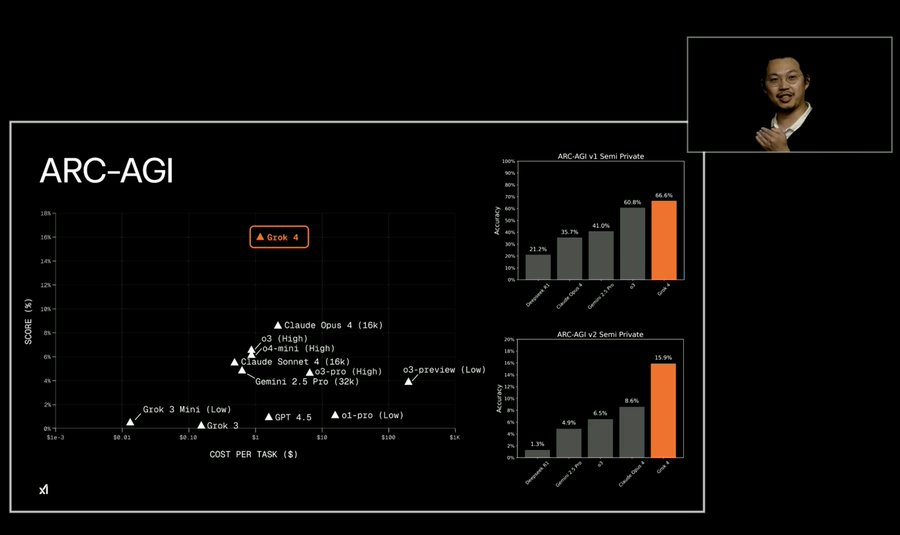
在 ARC-AGI-1 测试中,Grok 4(Thinking 版本)取得了 66.7% 的成绩,与 ARC 上个月公布的 AI 推理系统帕累托最优边界高度吻合。(ARC-AGI 是评估人工智能通用推理能力的基准测试;Pareto frontier“帕累托最优边界”在 AI 领域指的是在多个性能维度上达到最优平衡的状态,即无法在提升某一维度表现的同时不损害其他维度。)
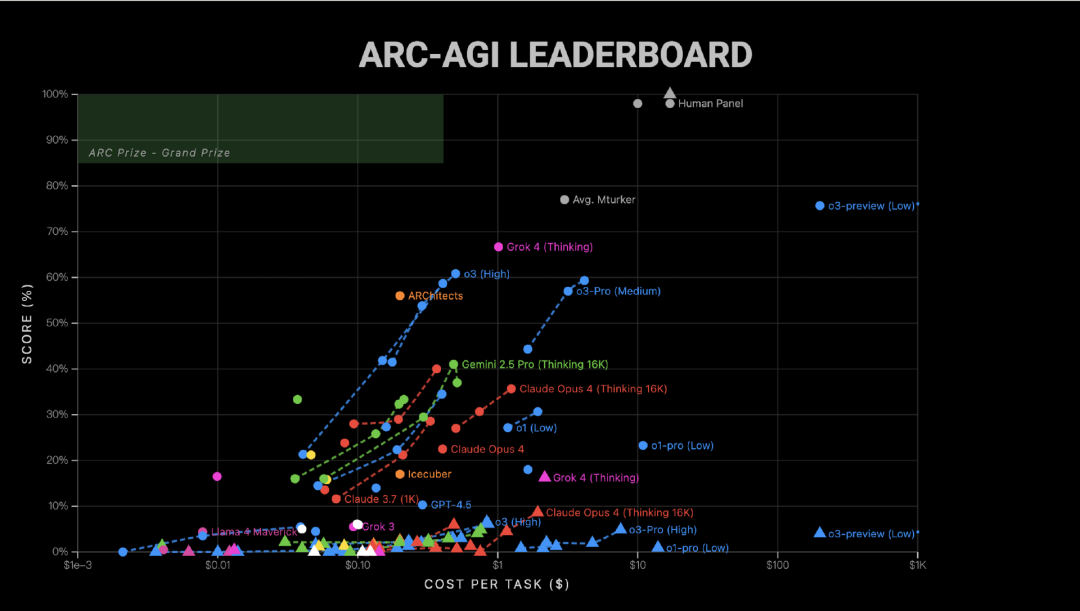
在 ARC-AGI-2 测试中,Grok 4(Thinking 版本)以 15.9% 的得分创下新的最优成绩(SOTA)。这一成绩几乎是此前商业模型最优成绩的两倍,且超过了当前 Kaggle 竞赛中的最优成绩。(Kaggle 是知名的数据科学与机器学习竞赛平台。)
发布之前,xAI 让独立 AI 基准测试与分析平台 Artificial Analysis 提前使用了 Grok 4,其在完成全套基准测试后放出这样的结果:Grok 4 的人工智能分析智能指数达到 73,领先于 OpenAI o3(70)、谷歌 Gemini 2.5 Pro(70)、Anthropic Claude 4 Opus(64)以及 DeepSeek R1 0528(68)。
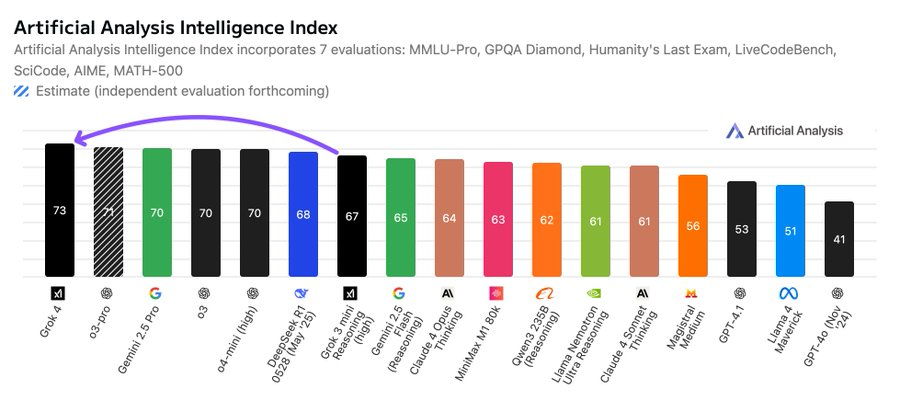
Grok 4 除在人工智能分析智能指数中位居榜首外,在编码指数(LiveCodeBench 和 SciCode)与数学指数(AIME24 和 MATH-500)中同样领先。更详细的关键基准测试结果如下:
-
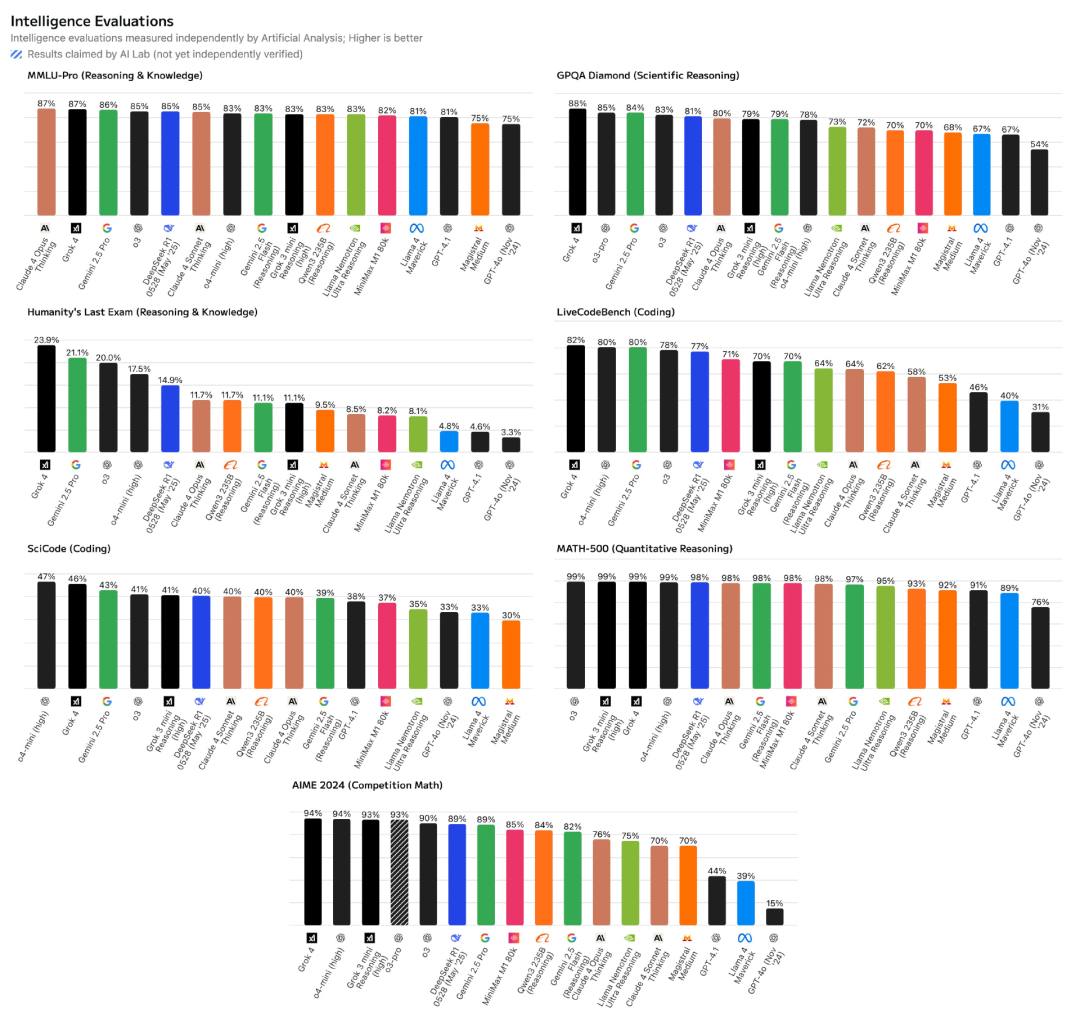
在 GPQA Diamond 测试中创下 88% 的历史最高分,较 Gemini 2.5 Pro 此前 84% 的纪录实现突破。
-
在 “人类终极考试”(HLE)中取得 24% 的历史最高分,超过 Gemini 2.5 Pro 此前 21% 的纪录。注:我们的基准测试套件使用原始 HLE 数据集(2025 年 1 月版),且仅运行纯文本子集,不借助任何工具。
-
在 MMLU-Pro 和 2024 年 AIME 测试中分别以 87% 和 94% 的成绩并列第一。
-
速度:每秒输出 75 个 token,慢于 o3(188 token / 秒)、Gemini 2.5 Pro(142 token / 秒)、Claude 4 Sonnet 思维版(85 token / 秒),但快于 Claude 4 Opus 思维版(66 token / 秒)。
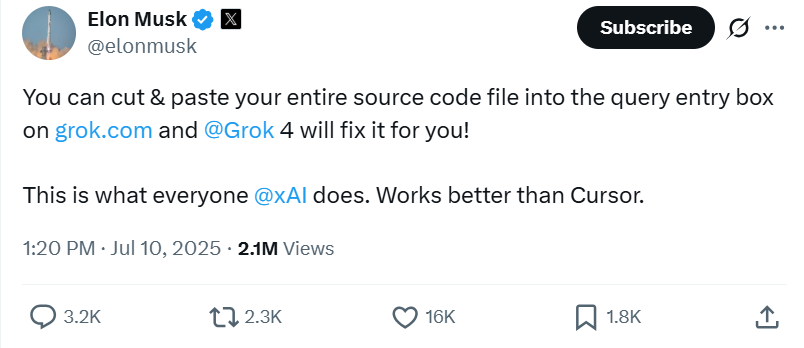
此外,马斯克提到,在编码方面,“Grok 4 比 Cursor 更好用”。据他介绍,将整个源代码文件复制粘贴到 Grok 的查询输入框中后,Grok 4 就会开始修复代码。
性能如此强大,
怎么做到的?
Grok 4 为什么能做到如此强大的性能表现?
现场,xAI 研究科学家 Tony Wu 重点介绍了该模型在训练方面的进展,并指出其从预训练转向了对推理和强化学习的高度重视。

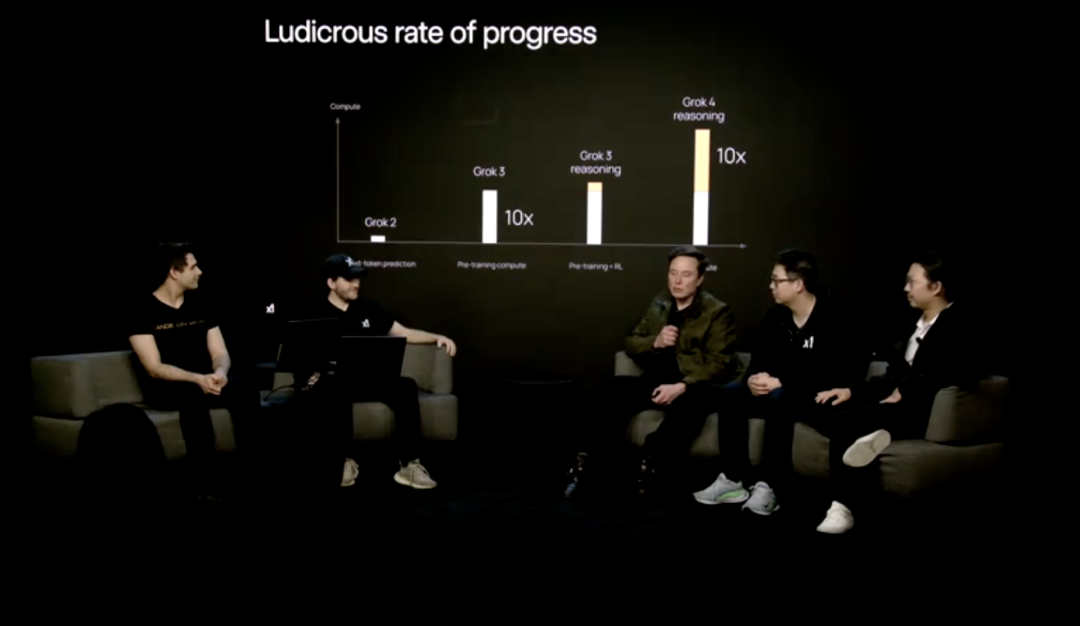
“从 Grok 3 到 Grok 4,我们将大量的计算投入到推理和强化学习中,”Tony Wu 说道。他还补充道,借助 Grok 4 Heavy 中新增的工具和多智能体系统,该模型在严苛的人文硕士考试基准测试中解决了超过 50% 的文本问题,相比早期模型的个位数准确率,实现了显著的飞跃。
马斯克将这一飞跃归功于大规模计算扩展,并指出 xAI 将训练量从 Grok 2 提升到 Grok 3,然后再提升到 Grok 4,提升了一个数量级。“它的训练量是 Grok 2 的 100 倍,而且只会继续增加,”马斯克说道。“从某些方面来说,这有点令人恐惧,但这里的智能增长是惊人的。”
xAI 联合创始人 Jimmy Ba 也对此次规模扩张表示赞同,并称赞该公司的 Colossus 超级计算机已扩展到 20 万个 GPU,使其在强化学习中的计算能力比任何竞争对手的模型高出 10 倍。Jimmy Ba 指出:“这确实是发展最快的领域。”
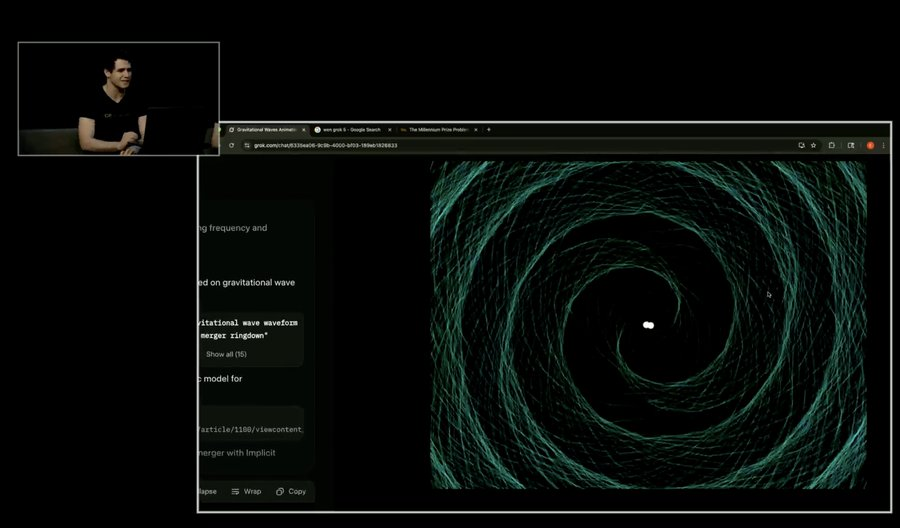
有趣的是,在直播演示中,Grok4 甚至重现了由碰撞黑洞产生的引力波。
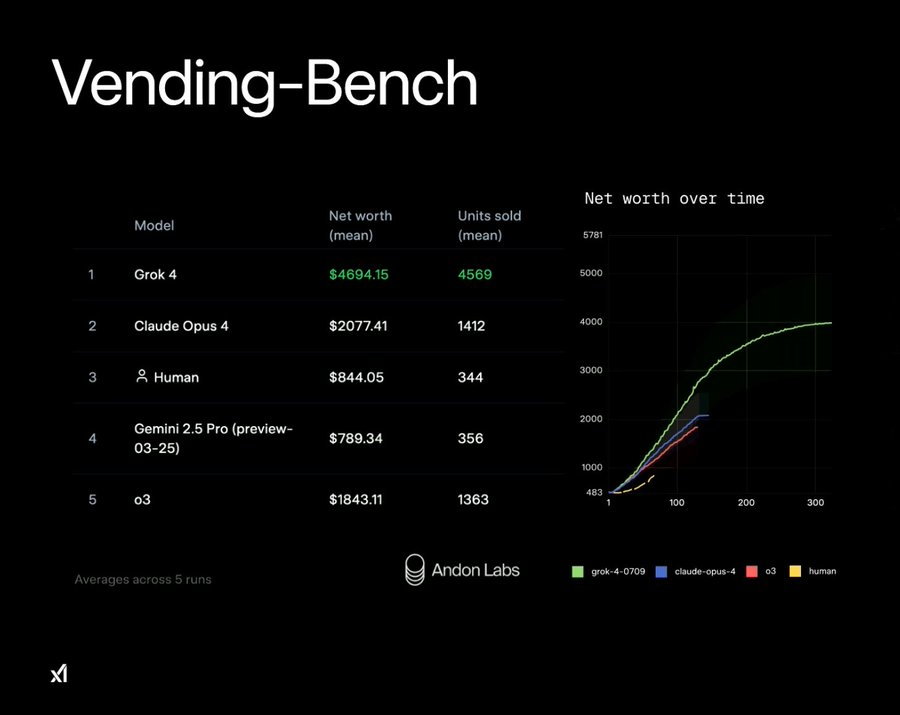
其中一个演示展示了 Grok 4 在 Handle Labs 的 VendingBench 上表现出色。VendingBench 是一款 AI 商业模拟游戏,该模型通过管理库存和合同,使竞争对手的净资产翻了一番。马斯克以他标志性的幽默感回应道: “很高兴看到我们现在有办法支付所有这些 GPU 的费用了,”他开玩笑说。“我们只需要一百万台自动售货机,每年就能赚 47 亿美元(合约人民币 337.28 亿元)。出发!”
语音模式也得到了显著升级。据介绍,Grok 4 的语音功能拥有自然、类人的声线,且中断更少。Jimmy Ba 解释了他们的理念: “我们追求的是更平静、更流畅、更自然的声音,而不是更夸张或更做作的声音。”
该路线图瞄准了关键的研发痛点。预计“几周内”将推出一个专门的编码模型。即将推出的第七版基础模型将增强多模态理解,从而实现强大的视频生成功能。马斯克设定了雄心勃勃的创意时间表: “我预计第一款真正优秀的人工智能电子游戏将在明年问世,”他预测道,“也可能是第一部值得一看的人工智能电影将在明年问世。”
“唯一能够完美评判事物的就是现实,”他总结道。“因为物理学是定律,所以最终其他一切都只是建议……对人工智能的最终考验是现实。”

Grok 4 的发布在 Hacker News、Reddit、X 等平台上引发热议。
在 Hacker News 上,有网友称:
“Grok 4 看起来它确实是新的 SOTA 模型,在 Humanity’s Last Exam、GPQA、AIME25、HMMT25、USAMO 2025、LiveCodeBench 以及 ARC-AGI 1 和 2 中的得分明显优于 o3、Gemini 和 Claude。马斯克团队强调专用编码模型将在几周后推出,所以他们今天并没有过多地讨论 Grok 4 的编码性能。”
对于马斯克团队晒出的 Grok 4 在人类最后的考试基准测试中的得分,网友也认为如果情况属实那这款模型真的太强大了。
“老实说,如果它真的在人类的最后考试中获得了 44.4% 的分数,那将是极其令人印象深刻的,因为 Gemini 2.5 Pro 和 o3 加上工具后得分仅为 26.9% 和 24.9%。”
在 Grok 4 发布后,压力似乎来到了 OpenAI 这边,有网友认为,OpenAI 新模型可能会在 8 月份发布,因为他们可能会在 Grok 4 发布后争个后来者居上。
“我认为 Chat GPT 5 要到 8 月底才会发布。他们会根据 Grok 的表现,看看如何提升它的水平。”
(文:AI前线)