


“情智兼备”是新一代人工智能的重要发展方向,是迈向通用人工智能的关键一步。在人机交互场景中,具备情智的数字人与机器人需要精准解译多模态交互信息,深度挖掘人类内在情感状态,从而实现更具真实感与自然性的人机对话。然而,面对多模态情感数据语义的高度复杂性,如何有效建模跨模态关联关系仍是领域内亟待突破的核心挑战。
针对这一技术瓶颈,快手可灵团队与南开大学在「多模态情感理解」领域完成了开创性研究,成功定位了现有多模态大模型在情感线索捕捉中的关键短板。研究团队从多模态注意力机制的维度切入,提出了新的模块化双工注意力范式,并基于此构建了一个涵盖感知、认知与情感能力的多模态模型‘摩达(MODA)’。该模型在通用对话、知识问答、表格处理、视觉感知、认知分析和情感理解等六大类任务的 21 个基准测试中均实现了显著性能提升。此外,基于新的注意力机制,‘摩达’在角色剖析与规划演绎等人机交互场景中表现出色。目前,该研究成果已被 ICML 2025 收录,并获选焦点论文(Spotlight,Top 2.6%)。

-
论文标题:MODA: MOdular Duplex Attention for Multimodal Perception, Cognition, and Emotion Understanding
-
论文地址:https://arxiv.org/abs/2507.04635
-
项目主页:https://zzcheng.top/MODA/
-
模型地址:https://huggingface.co/KwaiVGI/MODA
-
代码地址:https://github.com/KwaiVGI/MODA
利用多种线索预测人类的情感状态,赋予了多模态大模型更强的拟人能力 [1]。现有的主流多模态大模型具有通用可泛化的注意力架构,然而以语言为中心进行预训练机制导致其存在模态偏置,难以关注到细粒度的情感线索。基准测试表明,现有方法在需要细粒度认知和情感理解的高级任务中表现不佳,甚至低于随机猜测水平 [2]。例如,在二分类讽刺检测任务中,三个最先进的多模态方法仅能达到 50:50 的识别准确率。
这一现象的根源在于对主导模态的过度关注,从而忽视了辅助模态中蕴含的细粒度线索。我们深入探究其内在原因,重点分析了用于混合多模态线索的注意力机制。如图 1(a) 和 (b) 所示,现有模型难以捕捉细粒度细节(例如角色的眼神、对话中的关键词),最终导致情感理解的错误。其核心的问题是多模态大模型多个注意力层之间的注意力不一致(图 1(c) 中跨模态的注意力差异高达 63%),即多模态注意力失调现象。具体表现为:一方面,多模态大模型的注意力分数偏向于文本模态;另一方面,注意力的逐层衰减,进一步加剧了模态间的差异。最终,不同模态之间的注意力分数差异最高可达 10 倍。
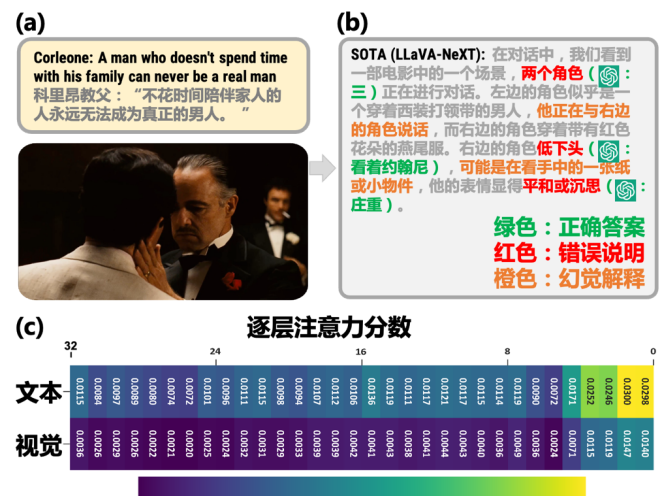
图 1: 多模态注意力失调制约模型能力
为解决这一问题,本研究从多模态注意力机制的视角出发,指出了现有多模态大模型的关键卡点,并深入分析了其失效 / 失能的核心成因。基于上述观察,我们提出一种模块化的双工注意力范式,并据此构建了一个新一代多模态模型‘摩达’。该模型专为感知(Perception)、认知(Cognition)、情感(Emotion)等多层次任务设计,显著提升了模型在细粒度理解、复杂规划和交互任务上的能力。
注意力机制通过计算多模态词元间的相似性和掩码来控制词元间的交互。为了研究多模态注意力失调问题,我们在四类细粒度理解问题上进行实验分析。
如图 2(a) 所示,实验结果显示视觉内容所分配的注意力明显低于文本模态。这一现象符合预期,因为基于自回归模型微调而来的多模态大模型,通常在处理细粒度视觉感知时面临固有挑战。此类模型的架构设计最初主要针对文本任务优化,因此在在扩展到多模态场景时,视觉特征受关注的程度不足。这种模态间不平衡突显了当前架构中的关键局限性:模型在文本处理方面的能力并未平滑地转化为同等水平的视觉处理能力。
进一步揭示,在图 2(b) 和 (c) 中,模型跨越 32 个层级间表现出显著的跨模态注意力偏差。较高层与较低层的注意力分布存在明显不一致。具体而言,较低层通常过度关注跨模态交互,因此牺牲了有效捕捉模态内特征的能力。这种错位导致了多模态集成效果欠佳。原因在于,当模型从低层次向高层次特征抽象过渡时,跨模态的注意力得分随着层次加深而降低,致使视觉模态的信息在一定程度上被稀释了。
以此为基础,引出多模态注意力失调问题。给定层中的视觉词元和文本词元,多模态注意力通过以下两部分建立链接(即,自模态→,→和跨模态→,→),其中链接通常通过成对词元的相似性和加权求和来实现。然而,由于词元之间的模态差距,链接的强度会减弱,链接值→和→会随着深度呈指数衰减α
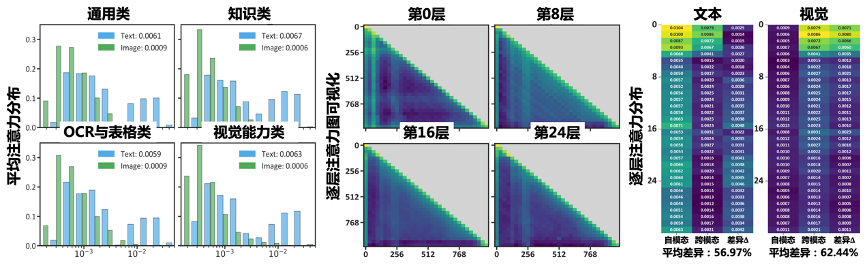
图 2: 预实验证明了多模态注意力失调的存在
为克服多模态注意力失调的问题,我们提出对来自多个模态的词元进行对齐的新方案,即模块化双工注意力。该范式的核心设计是将多模态注意力划分为两个部分:模态对齐部分和词元焦点修正部分。如图 3 所示,以图像与上下文(如对话的背景和历史消息)提示作为输入。借助模块化双工注意力,得以矫正大模型中由于模态偏置而导致的错误多模态特征流。通过双工注意力对齐和模块化注意力掩码以“对齐后修正”的方式修正存在缺陷的注意力分数。
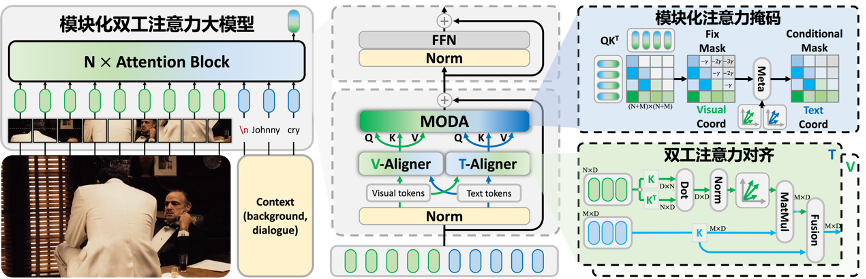
图 3: ‘摩达’网络架构
为了减少模态不一致性,一个直观的解决方案是将多模态特征进行对齐。受到扩散模型中视觉 – 语言嵌入空间映射最新进展的启发 [4],我们提出了基于 Gram 矩阵的嵌入空间基向量进行跨模态语义迁移。具体来说,根据词元表征计算 Gram 矩阵,从中提取每个模态空间的基向量,压缩每个模态的语义,并作为其他模态的转移。因此,双工注意力对齐包括 V-Aligner 和 T-Aligner,分别负责视觉和语言模态。
对于第模态,空间基是根据归一化的Gram矩阵给出的,其中是词元和 之间的内积:
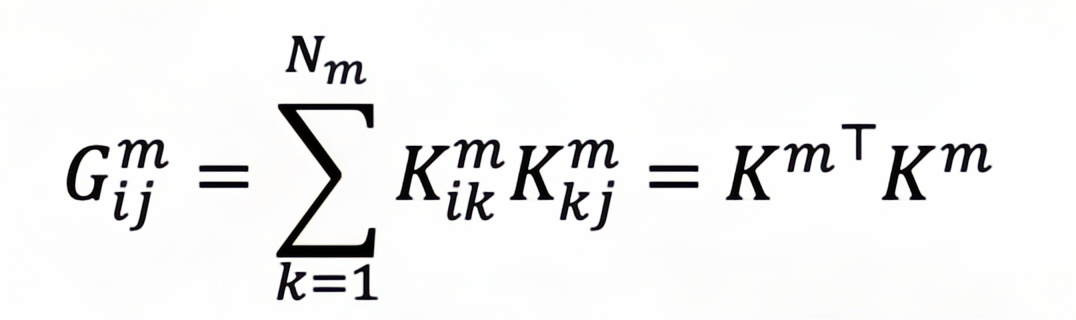
其中是第个模态词元的键状态,是属于模态的词元数量。通过包括由 Gram矩阵定义的空间基向量,可以有效捕捉词元之间的关系,从而构建出一个既有丰富信息又能保持数据内在结构的特征表示。
作为后续工作,归一化的Gram矩阵充当跨模态词元转移函数,使得来自其他模态𝑚的词元能够高效地转换到模态,作为一个核化映射函数。对齐后的词元计算如下:
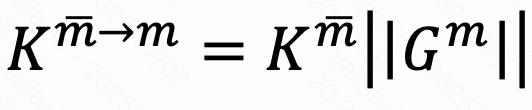
其中表示来自其他模态的值。映射后的词元与原始词元进一步融合,以增强所有模态之间的词元相似性。
注意力掩码控制词元在变换器层之间的流动,并为多模态大模型引入位置偏差。为了更好地适应多模态词元序列的需求,为每个模态分配一个调节后的注意力掩码,分为和,负责模态内和模态间注意力:
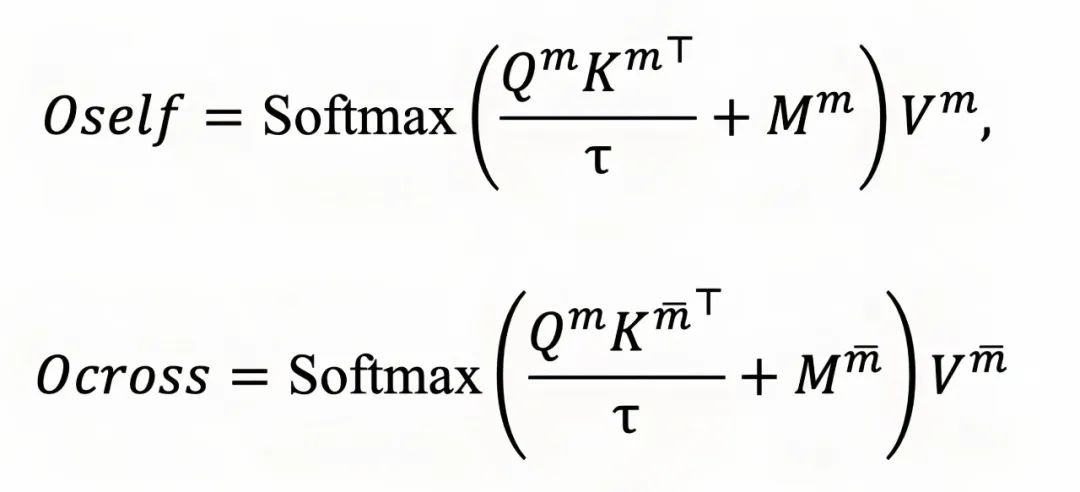
为了缓解塌陷的注意力矩阵并防止它在词元上过度平滑,提出一种模块化注意力掩码,它选择将不必要的注意力值存储在这些伪注意力分数中。对于每一行(即第个词元的所有注意力分数),它可以注意到的序列长度固定为。因此,每行中将有个伪注意力分数,用于过度注意力分配。将注意力分数转化为:
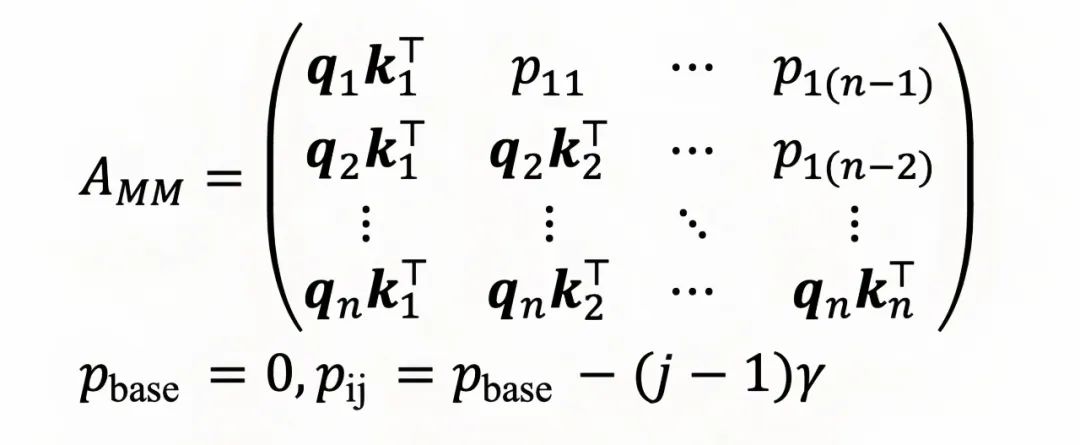
其中γ是衰减率超参数。
除了绝对位置先验信息外,进一步引入模态位置以强制模型修正词元在模型层间的流动。引入归一化的 Gram 矩阵作为指标,找出哪些部分应该携带模态位置先验信息。这种分离允许更精确地控制同一模态中的词元如何相互作用,以及它们如何与来自其他模态的词元交互。
具体来说,利用视觉和文本模态的Gram矩阵作为基向量,这里
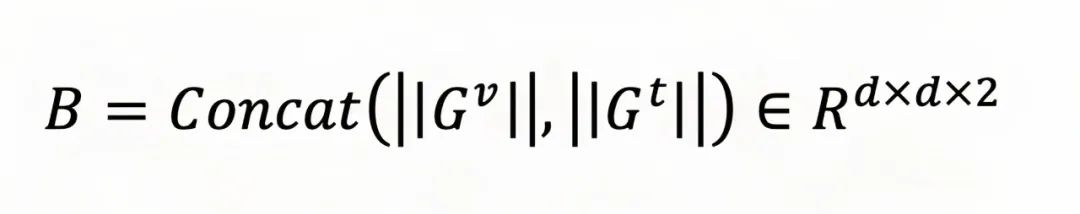
进一步利用多个模态的特征捕捉各个注意力头的特征。这里,
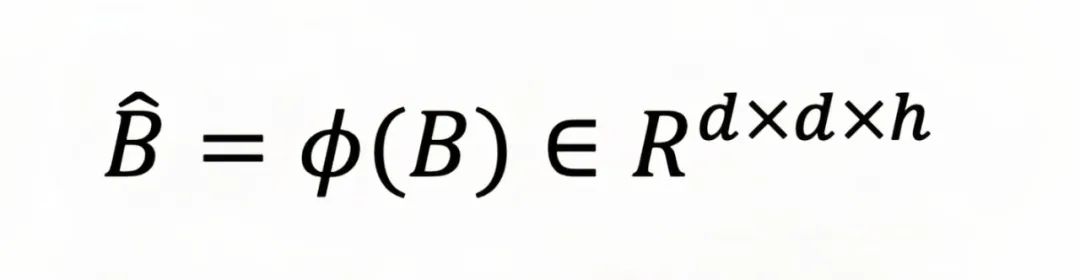
然后,将各个注意力头的基向量进行上采样,对齐基向量与注意力图的尺寸到
实验结果表明,通过引入模块化双工注意力范式,模态偏置引起的注意力失调问题得到了有效缓解,在基于此范式构建的 80 亿与 340 亿参数量级多模态模型成功实现了性能显著提升。该范式专为多模态大模型网络架构设计,能够无缝替换原有注意力模块,并有效促进多模态信息的深度融合。
①缓解多模态注意力失调: MODA 有效缓解了跨模态间的注意力差异问题。如图 4 所示,该范式将模型各层的跨模态注意力差异率由原本的 56% 与 62% 显著降低至 50% 与 41%。

图 4: 模块化双工注意力机制在缓解多模态注意力失调问题上的效果
②性能提升:
-
内容感知能力:如表 1 所示,MODA 在包含通用对话、知识问答、表格 OCR、视觉感知四大类任务(共计 16 个数据集)的内容感知方面展现出明显优势。
-
认知与情感理解能力: 如表 2 所示,MODA 在认知分析和情感理解两大类任务(共计 5 个数据集)上的性能也得到显著提升。
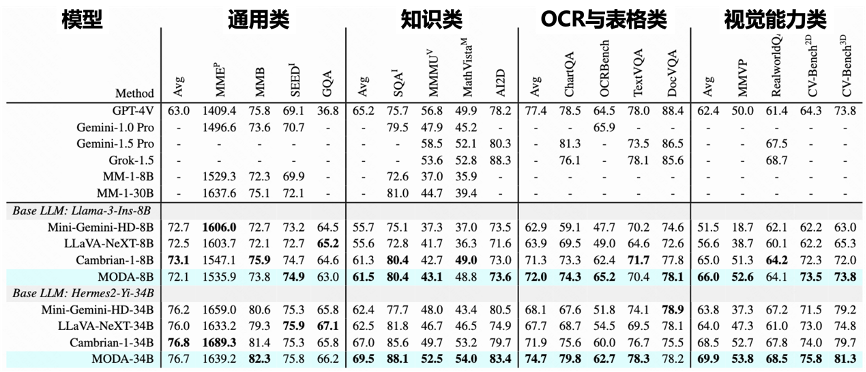
表 1:‘摩达’在通用对话、知识问答、表格 OCR、视觉感知 4 大类任务上的表现
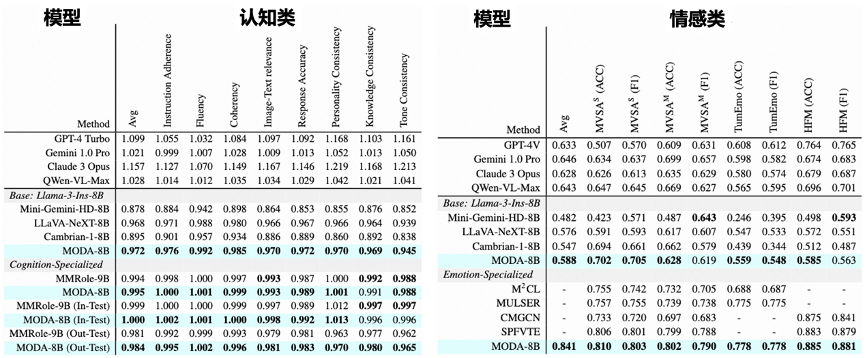
表 2:‘摩达’在认知分析与情感理解 2 类任务上的表现
③多功能性:MODA 具备内容感知、角色认知与情感理解的综合能力(图 4 提供可视化样例)在对话场景中,MODA 精准识别用户意图与情感倾向,并基于角色配置文件自动适配符合场景规范的响应策略。

图 4:‘摩达’在内容感知、角色认识与情感理解三个方面可视化样例
④人机对话应用:MODA 在人机对话场景中展现出强大潜力(应用示例见图 6)。模型可实时解析用户的微表情、语调及文化背景特征,构建多维人物画像,并深度理解角色动机与情感脉络以自动规划对话策略。例如在心理咨询中识别矛盾情绪并引导倾诉,或在虚拟偶像交互中动态调整角色台词风格。这种能力突破了传统规则式应答的局限,使 AI 能够像人类导演般”预判剧情走向”,在金融客服、沉浸式娱乐等领域实现有温度的人格化服务。

图 6: ‘摩达’在人机对话场景中的应用示例
MODA 已成功应用于快手可灵数据感知项目,重点通过细粒度情感感知显著增强了数据分析能力。在情感识别与推理任务中,MODA 展现出卓越的性能,有效提升了分析的精度和应用效果,尤其是在情感变化检测和个性化推荐任务中提升感知精度,有力支撑了可灵视频生成产品的性能。
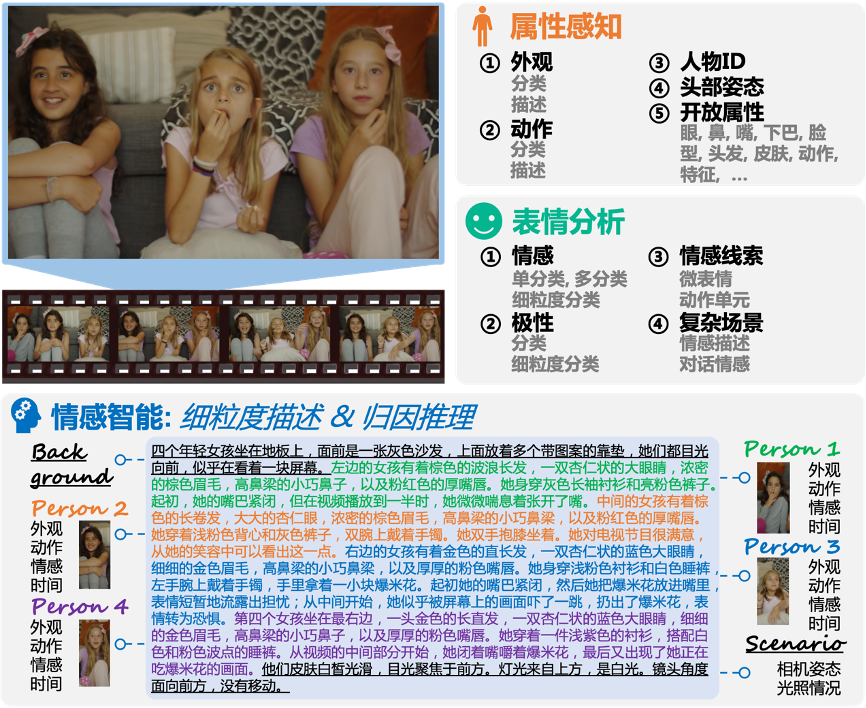
图 7: ‘摩达’在可灵数据细粒度感知项目中的应用示例
点击【阅读原文】即可跳转模型地址。
参考文献:
[1]Sicheng Zhao, Guoli Jia, Jufeng Yang, Guiguang Ding, Kurt Keutzer. Emotion recognition from multiple modalities: Fundamentals and methodologies. IEEE Signal Processing Magazine, 38(6): 59-73, 2021.
[2]Zhiwei Liu, Kailai Yang, Qianqian Xie, Tianlin Zhang, Sophia Ananiadou. EmoLLMs: A series of emotional large language models and annotation tools for comprehensive affective analysis. KDD, 2024.
[3]Yihe Dong, Jean-Baptiste Cordonnier, Andreas Loukas. Attention is not all you need: Pure attention loses rank doubly exponentially with depth. ICML, 2021.
[4]Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer. High-resolution image synthesis with latent diffusion models. CVPR, 2022.
(文:AI前线)