

今天是2025年7月11日,星期五,北京,晴
继续看文档解析进展,来看看自然场景,尤其是历史文献修复的工作,其是一个很好的技术练兵场,具体可以细化为文本检测、布局分析、阅读顺序、文本ocr以及修复等多个点,这个难度很大,但很有意义。
实际上,我们在之前的文章《文档智能遇上历史古籍:古籍文档修复及识别开源数据集》(https://mp.weixin.qq.com/s/RqeU4f_lquA8DD1MNuHHwQ)有过介绍,其中提到《Predicting the Original Appearance of Damaged Historical Documents》(https://arxiv.org/pdf/2412.11634,https://github.com/yeungchenwa/HDR) 这个工作,构建了一个大规模的数据集HDR28K,基于MTHv2和M5HisDoc两个数据集,分别从这两个数据集的测试集中随机选择536张和891张原始图像作为HDR28K的测试集,算是提出了一个任务,然后做了个端到端的方案,DiffHDR网络-基于扩散的历史文献修复网络DiffHDR,将HDR任务视为一系列扩散步骤,逐步将受损区域转换为与目标字符内容和字符风格相匹配的图像。
现在,来看看一个pipeline的方案,方案也开源了,也很有趣,尤其是其中的投票策略。
历史文献修复的三阶段策略
现有的方法主要侧重于单一模态或有限尺寸的修复,难以满足实际需求,端到端的不太好,所以更直接的方式法模仿历史学家的修复流程:损伤定位->文本预测->外观恢复。
这种工作其实很有社会意义,所以看一个这方面的最新前沿工作《Reviving Cultural Heritage: A Novel Approach for Comprehensive Historical Document Restoration》,https://github.com/SCUT-DLVCLab/AutoHDR,https://arxiv.org/pdf/2507.05108,模型也开源了,AutoHDR-Qwen2-1.5B、AutoHDR-Qwen2-7B
1、先看数据
在数据上,做了一个全页HDR数据集 (FPHDR),包含1,633张真实图像和6,543张合成图像,这些图像包含字符级和行级位置信息,以及不同损伤等级的字符标注。
还是要说到数据合成,构建了包含三种退化类型的像素级损坏-恢复对样本,

包括:
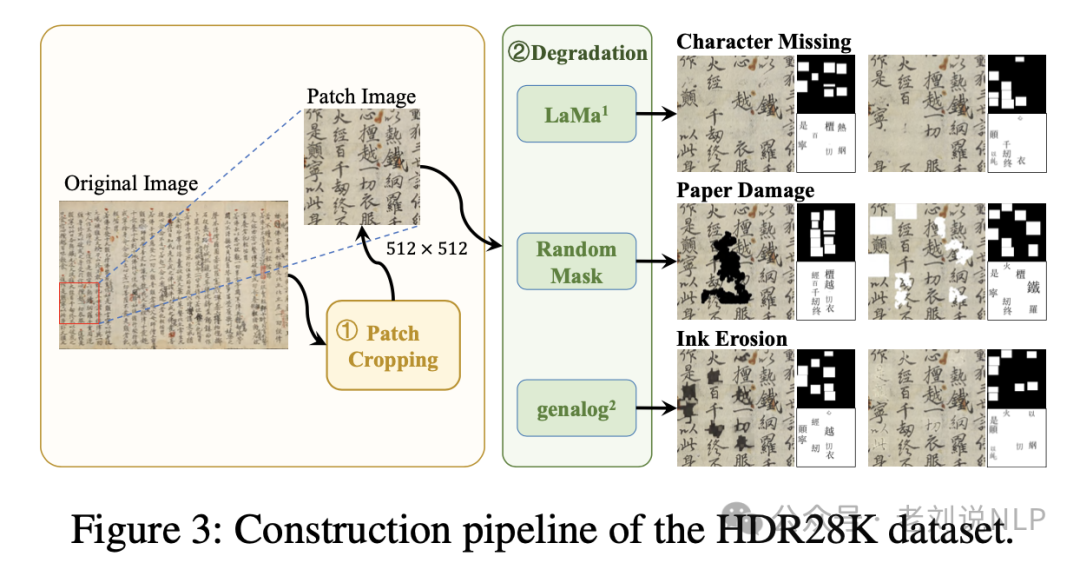
1) 字符缺失Character Missing:使用LAMA在随机生成的掩模上执行内容移除;
2) 页面损坏Paper Damage:在图像块中以黑色或白色遮盖随机区域以模拟退化;
3) 墨水侵蚀Ink Erosion:通过应用genalog多样的退化模式和核心来模拟水侵蚀和褪色效果。
2、预测模型建模思路
通过三阶段方法模拟历史学家的修复工作流程,如下:
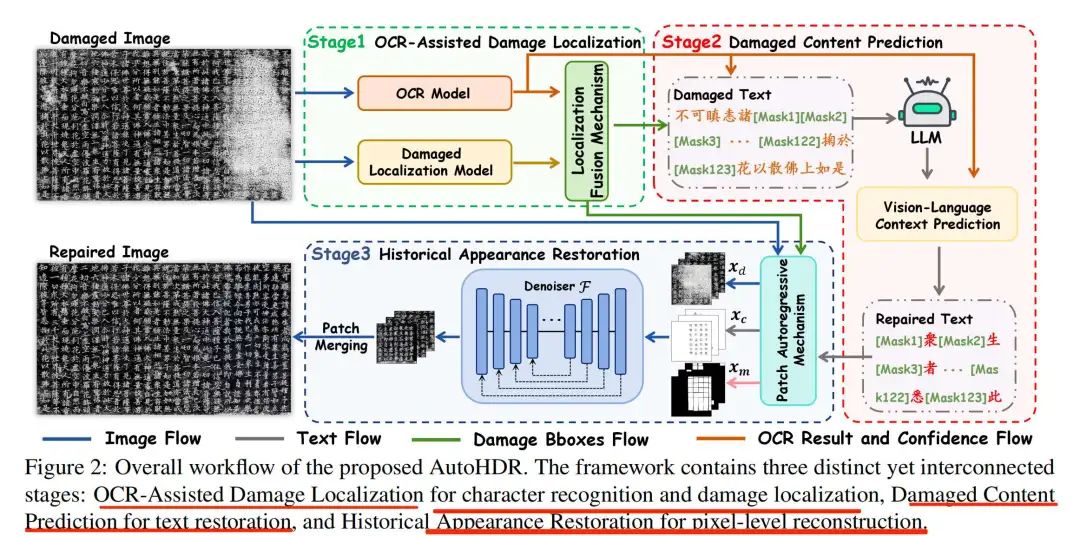
三个步骤:OCR辅助的损坏定位(OADL)用于字符识别和损坏定位,损坏内容预测(DCP)用于文本恢复,以及历史外观恢复(HAR)用于像素级重建,很典型的pipeline。
1)OCR辅助的损害定位(OADL)
OCR辅助的损伤定位阶段主要负责识别清晰可辨的字符,并检测受损字符的位置。
至于什么是轻微受损,什么是重度受损,也是观察的结果:

涉及到两个模型;
一个是使用来自多个中国历史数据集的数据进行训练,包括MTHv2、M5HisDoc、AHCDB和HisDoc1B做的字符级别的OCR模型。
一个是基于DINO的用于定位严重受损字符的检测模型。
训练完这两个模型后,实施定位融合机制,以合并两个模型的定位框,这个在文档目标检测上用的很多,合并检测结果。
这个步骤可看看:
OCR置信度得分低于0.1的字符,表示存在歧义,被认定为受损,并提取其相应的定位框B o。同时,从损伤定位模型中提取定位框Bs。接着,计算所有Bo与Bs之间的交并比。如果bo∈Bo与任何bs∈Bs的交并比大于0.5,则移除bo。相反,如果bo与任何Bs都不重叠(交并比低于0.5),则保留b。
2)损坏内容预测(DCP)
结合OCR的视觉识别和LLM的语言理解能力,预测受损内容。
采用Qwen2作为骨干模型,通过两阶段微调策略增强。
一阶段使用来自Daizhige和HisDoc1B(包含历史文献、诗歌、艺术、佛教文本等)的数据进行增量预训练,以增强模型对古典中文的理解;
二阶段利用CBeta(一个权威的佛教文本仓库)提供的成对的损伤与恢复的历史文本来做微调。
但是,其中有个问题,就是是在古典汉语文本中包含变体字符,即意义相同但书写形式不同的字符,所以使用字符变体来增强数据。
然后呢,问题又来了,由于古典汉语固有的复杂性,同一位置可能自然契合多个合理结果。因此,仅依赖这个LLM无法保证文本恢复的准确性。
所以,从视觉感知的角度来看,OCR方法可以识别轻微损坏的字,这可以作为有价值的辅助信息,减少需要预测的损坏内容量,并减轻LLM的预测负担。
那问题又来了,怎么融合进去?那就是利用OCR识别轻受损字符,LLM专注于重受损字符,分开去做。
这其实就是一个投票算法:
首先,OCR识别轻受损字符:对于每个字符,首先通过OCR技术识别其内容。如果OCR的置信度超过预定阈值,则直接采用OCR的预测结果;
其次,LLM预测重受损字符:对于OCR置信度较低的字符,利用LLM(如Qwen2)进行预测,LLM在处理复杂文本和罕见字符方面具有优势。
最后,综合预测结果,是个融合设计:
(1)基础得分:OCR和LLM概率得分的加权和。OCR对轻微损坏的字符有较高信心,但对严重损坏的字符信心较低,而LLM在后者情况下表现更好;
(2)排名得分:从两个模型预测中字符的排名位置得出得分;分别对LLM和OCR模型输出的概率进行排名,每个模型都根据其概率按照预测顺序生成自己的排名得分,这个排名标准有助于在概率得分接近时区分相似的字符;
(3)匹配奖励:出现在两个模型预测中的字符获得额外得分,表示视觉和语义上的合理性。
最后,将上述得分相加以获得综合得分,得分最高的候选字符被选为最终预测。
3)历史外观恢复(HAR)
基于DiffHDR做了个一个扩散模型,以像素级别恢复受损的历史外观,这类模型很多,包括NAFNet、Uformer和Restormer。
架构上也很简单,模型输入包括受损图像、掩码图像和内容图像,通过去噪生成恢复图像,是一个典型的恢复问题,这个也用在试卷擦除等场景中。
为了扩展到页面级别,引入了补丁自回归(PAR)机制,题首先从受损图像的四个角落动态选择起始补丁,选择损坏字符数量最少的补丁,以确保模型有尽可能完整的字符作为参考。然后对选定的补丁进行恢复,并将其放回原位。接着,一个重叠滑动窗口操作提取下一个补丁,利用先前恢复的区域作为进一步恢复的参考。
3、总结
这个工作借鉴的思路就是合成、分而治之的策略,尤其是其中的投票策略。
现在比较保险的做法,都是分而治之,做成pipeline方案,但这类的方式,就是在时间上不占优势,例如,正如文章所说,AutoHDR利用三阶段过程进行历史文档恢复,本质上在处理速度上存在一定的局限性。在实验中,单张NVIDIA A10 GPU上的推理平均需要约五分钟,此外,其还有误差传播。
所以,这其实又回到那个问题,是否可以直接用超强的多模态大模型去做?本文的开头就提到一个方案,只是效果不好而已。
参考文献
1、https://mp.weixin.qq.com/s/RqeU4f_lquA8DD1MNuHHwQ
2、https://github.com/SCUT-DLVCLab/AutoHDR
(文:老刘说NLP)