

微软在官网发布了2025年国际机器学习会议获奖论文CoLLabLLM,同时开源了该创新框架。
大模型在处理明确输入的单轮任务时表现出色,但在多轮交互中会暴露出严重缺陷。在现实场景中,用户往往无法完全清晰地表达自己的意图,导致模型需要通过多次交互来逐步明确需求,这种低效的对话方式不仅增加了用户的挫败感,也降低了任务完成的效率。
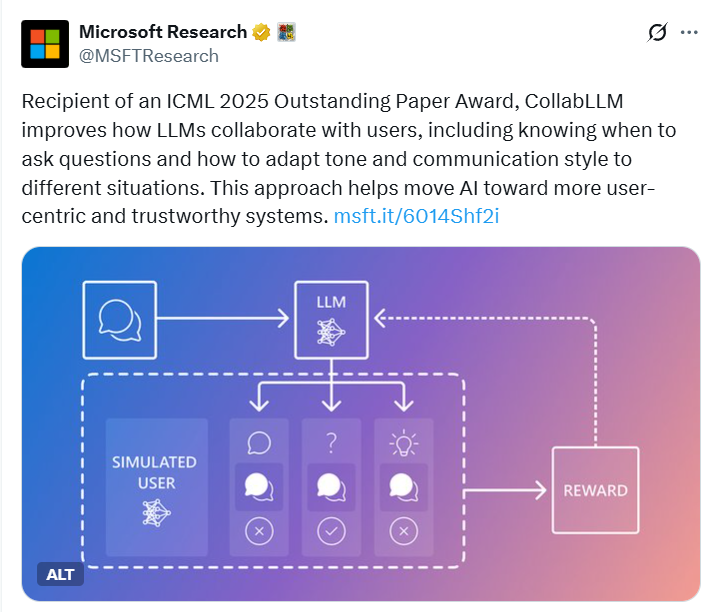
CoLLabLLM则通过多轮对话模拟和多轮感知奖励,使模型能够预测自身响应对未来交互的影响,从而给出更准确的结果提升用户体验。
开源地址:https://github.com/Wuyxin/CoLLabLLM
论文地址:https://www.microsoft.com/en-us/research/wp-content/uploads/2025/02/2502.00640v2.pdf
CoLLabLLM框架简单介绍
CoLLabLLM框架主要由四大核心模块组成,构建了一个完整的全周期协作系统,实现了从上下文理解到长期奖励优化的闭环。
上下文状态理解模块是整个框架的基础,负责整合对话历史与当前用户输入,构建结构化的上下文表示。与传统模型仅简单拼接对话内容不同,该模块采用动态窗口机制,能根据任务的复杂度和对话的长度自动调整上下文的保留范围,确保模型始终聚焦于关键信息。
在文档创作任务中,会优先保留用户关于文章主题、风格、重点内容的明确要求,以及之前讨论过的结构框架;而在代码生成任务中,则会重点维护用户对函数功能、参数类型、错误处理方式等技术细节的描述。这种有选择性的上下文管理,不仅减轻了模型的处理负担,还能避免无关信息干扰,使模型更精准地把握用户意图。
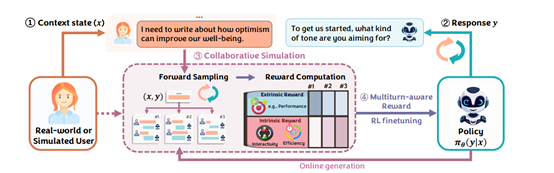
响应生成模块是CoLLabLLM与用户直接交互的接口,基于Llama-3.1-8B模型架构,并结合LoRA低秩适配技术进行参数高效微调。这一技术选择既保留了基础模型强大的语言生成能力,又通过微调使其适应协作场景的特殊需求。
在生成响应时,模块不仅关注语义的连贯性和表达的准确性,更核心的是评估每个候选响应的长期价值,即该响应能否引导用户提供更多必要信息、减少后续交互的成本,从而推动整个协作过程向实现用户目标的方向高效发展。
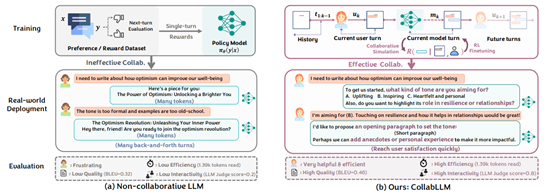
例如,在用户提出撰写一篇关于乐观主义的文章这一需求时,传统模型可能会直接生成全文,而CoLLabLLM的响应生成模块则会输出类似你希望文章采用令人振奋的还是诚挚的语气?是否需要强调乐观主义在韧性或人际关系中的作用?这样的引导性问题。
这种生成策略的转变,使得模型从单纯的内容生产者转变为积极的协作引导者,通过有针对性的提问,逐步明确用户的潜在需求,为后续的高质量协作奠定基础。
协作模拟模块是CoLLabLLM框架的核心相当于它的“大脑”,通过用户模拟器生成未来可能的对话轨迹,从而帮助模型预判当前响应的长期影响。
研究团队采用GPT-4o-mini构建用户模拟器,使其能够高度模仿真实用户的语言风格、知识水平,甚至会偶尔出现拼写错误等真实用户常见的行为特征。模拟器严格遵循三大行为准则:最小化努力,即避免主动提供过多细节,模拟真实用户在初始阶段往往只给出模糊需求的特点;偶尔犯错,增加交互的真实性;保持目标导向,不偏离任务主题,确保模拟的对话轨迹与用户的潜在目标相关。
在模拟过程中,模块采用“前向采样”策略,并设置窗口大小w作为超参数来平衡计算成本与预测准确性。实验数据表明,当w=2时,模型会模拟未来两轮的可能交互,这种策略相比单轮模拟,能使任务完成质量提升13.3%,同时将计算成本控制在每样本约0.00439美元的可接受范围内。通过这种前瞻性的模拟,协作模拟模块为模型提供了评估当前决策长期影响的依据,使模型能够跳出短期响应质量的局限,从更宏观的协作进程角度做出最优选择。
多轮感知奖励计算与强化微调模块则负责将协作模拟的结果转化为模型可学习的信号,通过强化学习算法优化模型的行为策略。该模块的奖励函数创新性地融合了外在指标任务成功度和内在指标用户体验,形成全面的多轮感知奖励。
其中,外在奖励通过BLEU评分(文档任务)、代码通过率(编程任务)或准确率(数学任务)等具体指标,衡量最终成果与用户目标的匹配度;内在奖励则包含token数量惩罚鼓励交互简洁,减少用户阅读负担和大模型裁判评分由Claude-3.5-Sonnet等模型评估交互的流畅性、协作性等用户体验维度。
在获取奖励信号后,研究团队采用PPO和DPO两种强化学习算法进行微调。其中,OnlineDPO变体表现最优,能够通过动态调整模型偏好,使交互效率提升8.25%,交互评分从基线模型的62.0跃升至92.0。
通过这种强化微调过程,模型逐渐学会在每一轮交互中选择那些既能满足当前用户需求,又能为长期协作带来最大价值的响应方式,最终形成稳定、高效的协作行为模式。
CoLLabLLM测试数据
为了测试CoLLabLLM的性能,研究团队在三大基准平台进行了综合测试。MediumDocEdit-Chat聚焦文档创作与编辑,以100篇Medium文章为目标,通过BLEU评分、token数量和交互评分评估协作质量。
结果显示,其OnlineDPO变体BLEU评分达36.8,较基线提升5.14%,token数量减少8.25%,ITR评分从62.0跃升至92.0,在乐观主义主题文章创作中,通过精准提问减少37%修改次数,内容匹配度显著提升。
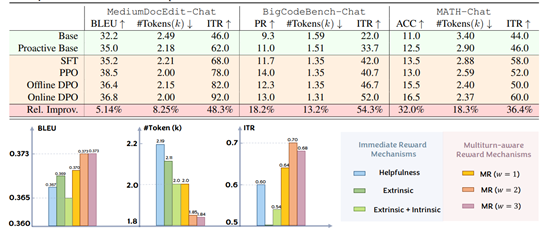
BiCodeBench-Chat针对代码生成与调试,选取600个编程问题,核心评估代码通过率和交互效率。该框架将代码通过率从11.0提升至13.0,token数量减少13.2%,在Python文本token化任务中,通过确认NLTK版本、token器选择等关键信息,最终代码通过率达100%,避免传统模型因擅自假设导致的错误。
MATH-Chat专注数学问题求解,选用200道5级难度题目,以准确率为核心指标。其OnlineDPO变体准确率提升32.0%,token数量减少18.3%,在球面坐标转换问题中,通过追问关键假设澄清用户需求,成功推导出正确答案,验证了复杂逻辑推理中的协作优势。这三大测试共同证明,COLLAB大模型能在多样任务中主动引导交互、精准捕捉意图,实现高效协作。
(文:AIGC开放社区)