

项目简介
Leffa 是一个用于可控人物图像生成的统一框架,可以精确操纵外观(即虚拟试穿)和姿势(即姿势转移)。

可控人物图像生成旨在生成以参考图像为条件的人物图像,从而可以精确控制人物的外观或姿势。然而,现有方法尽管实现了较高的整体图像质量,但通常会扭曲参考图像的细粒度纹理细节。我们将这些扭曲归因于对参考图像中相应区域的关注不够。为了解决这个问题,我们提出了注意力学习流场(Leffa),它明确引导目标查询在训练期间注意注意力层中的正确参考键。具体来说,它是通过基于扩散的基线内的注意力图之上的正则化损失来实现的。我们的大量实验表明,Leffa 在控制外观(虚拟试穿)和姿势(姿势转移)方面实现了最先进的性能,显着减少了细粒度细节失真,同时保持了高图像质量。此外,我们表明我们的损失与模型无关,可用于提高其他扩散模型的性能。
方法
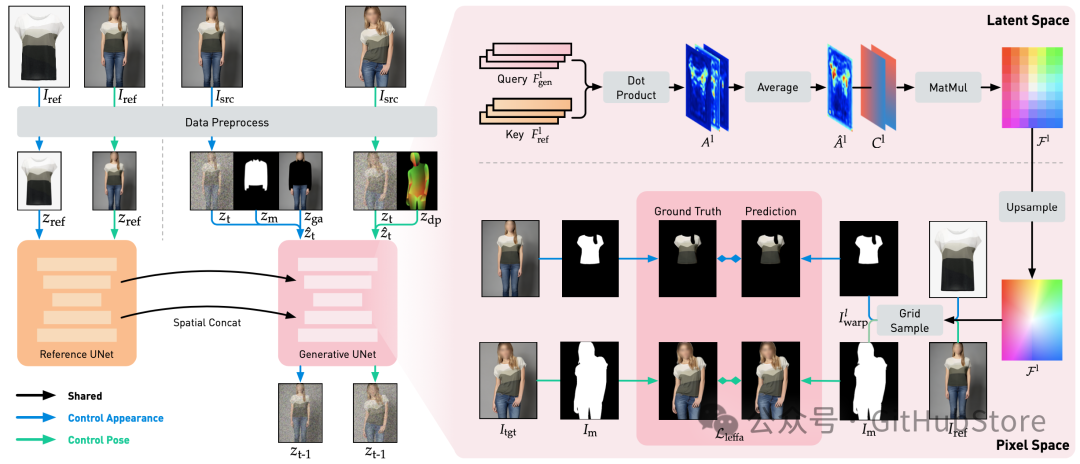
用于可控人物图像生成的 Leffa 训练流程概述。左边是我们基于扩散的基线;右边是我们的 Leffa 损失。请注意,训练期间 Isrc 和 Itgt 是同一图像。
可视化
与其他方法的定性视觉结果比较。用于姿势转移的输入人物图像是在虚拟试穿中使用我们的方法生成的。可视化结果表明,我们的方法不仅生成高质量的图像,而且大大减少了细粒度细节的失真。

安装
创建conda环境并安装要求:
conda create -n leffa python==3.10conda activate leffacd Leffapip install -r requirements.txt
Gradio App
本地运行:
python app.py
项目链接
在线体验:https://huggingface.co/spaces/franciszzj/Leffa
Github:https://github.com/franciszzj/Leffa
模型:https://huggingface.co/franciszzj/Leffa
扫码加入技术交流群,备注「开发语言-城市-昵称」
(文:GitHubStore)