

#01
-
工作流系统是通过预定义的代码路径来协调 LLM 和工具的系统。
-
Agent 则是由 LLM 动态指导,自主执行任务的过程和工具使用,控制完成任务的方式。
#02
#03
-
LangChain 的 LangGraph:https://langchain-ai.github.io/langgraph/
-
Amazon Bedrock 的 AI Agent 框架:https://aws.amazon.com/bedrock/agents/
-
Rivet,一个拖放式图形用户界面(GUI)LLM Workflow 构建器:https://rivet.ironcladapp.com/
-
Vellum,另一个用于构建和测试复杂 Workflow 的 GUI 工具:https://www.vellum.ai/
#04
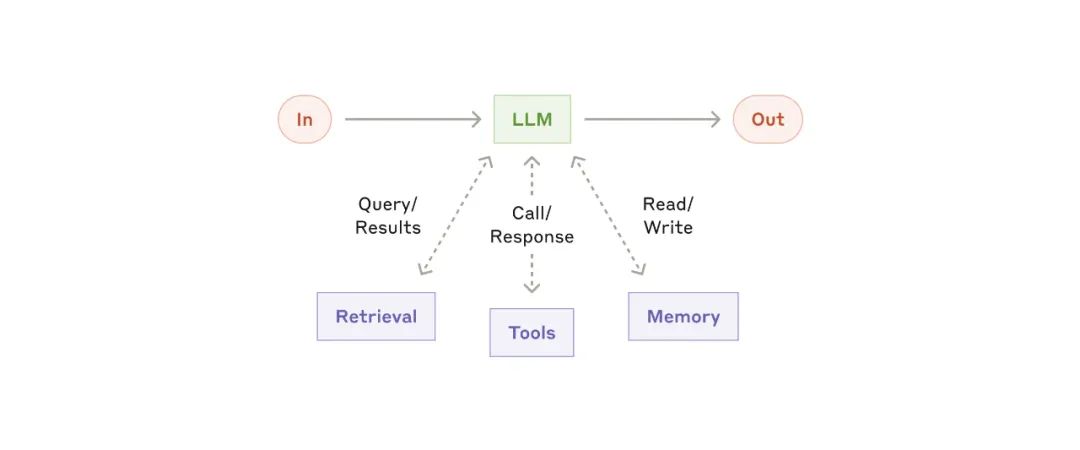 增强型 LLM
增强型 LLM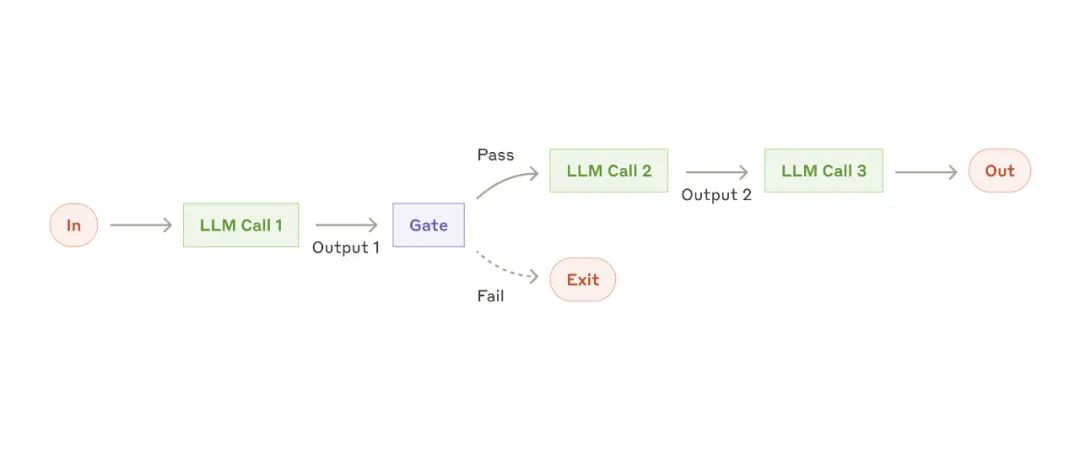 提示链工作流
提示链工作流-
生成市场营销文案,然后将其翻译成另一种语言。
-
撰写文档的大纲,检查大纲是否满足某些标准,然后根据大纲编写文档。
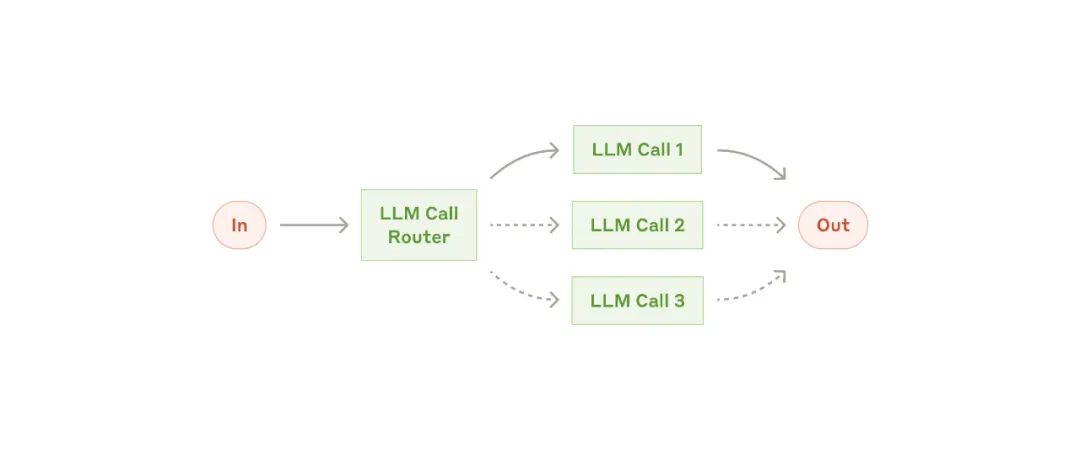 路由工作流
路由工作流-
将不同类型的客户服务查询(如一般问题、退款请求、技术支持)分别引导到不同的下游流程、提示词和工具中。
-
将简单或常见的问题路由到较小的模型(如 Claude 3.5 Haiku),而将复杂或不常见的问题路由到更强大的模型(如 Claude 3.5 Sonnet),以优化成本和速度。
-
划分:将任务拆解为独立的子任务并行执行。
-
投票:多次执行相同的任务以获取多样化的输出。
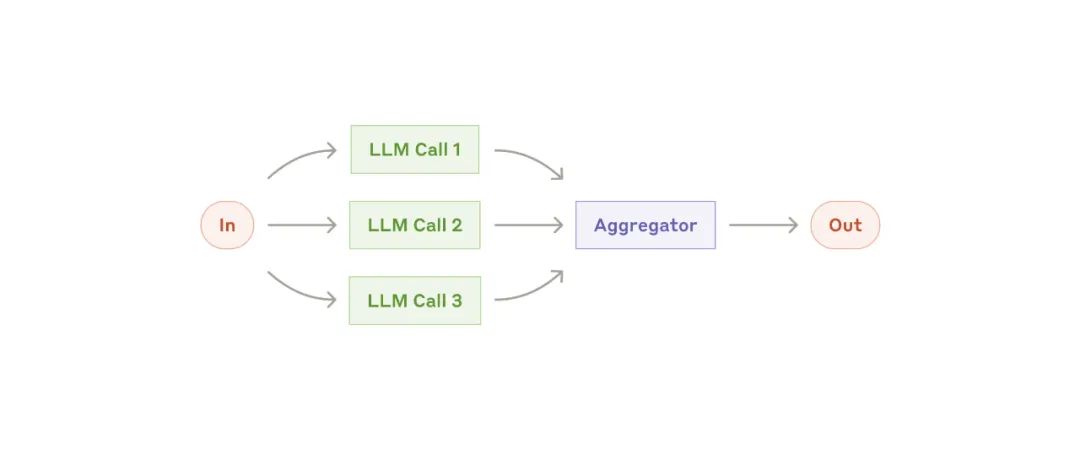 并行化工作流
并行化工作流-
划分:
-
实现保护机制,其中一个模型实例处理用户查询,另一个实例筛查不当内容或请求。与让同一个 LLM 调用同时处理保护机制和核心响应相比,这种方法通常效果更好。
-
自动化评估 LLM 的性能,其中每个 LLM 调用都会根据给定提示评估模型性能的不同方面。
-
投票:
-
审查代码中的漏洞,多个提示词审查并标记代码中的问题。
-
评估给定内容是否不当,多个提示词评估不同方面或设置不同的投票阈值,以平衡假阳性和假阴性。
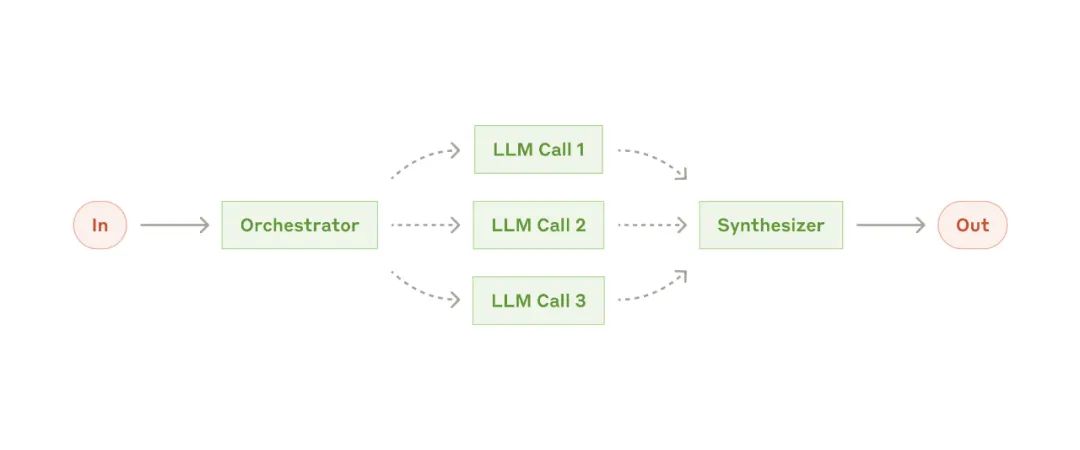 Orchestrator-workers 工作流
Orchestrator-workers 工作流-
编程产品,每次对多个文件进行复杂的更改。
-
搜索任务,涉及从多个来源收集并分析信息以找到可能相关的内容。
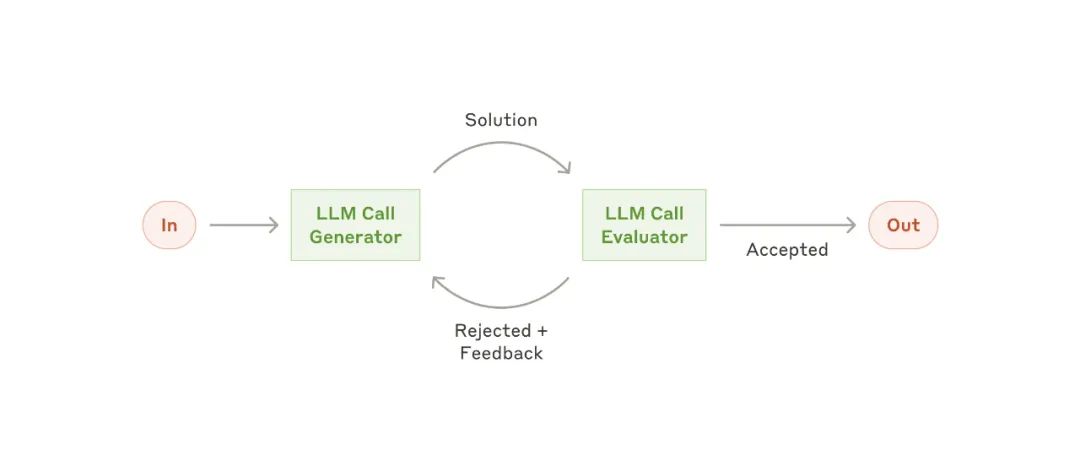 Evaluator-optimizer 工作流
Evaluator-optimizer 工作流-
文学翻译,其中可能存在翻译 LLM 最初未捕捉到的细微差异,但评估者 LLM 可以提供有价值的反馈。
-
复杂的搜索任务,涉及多轮搜索和分析以收集全面信息,评估者决定是否需要进一步的搜索。
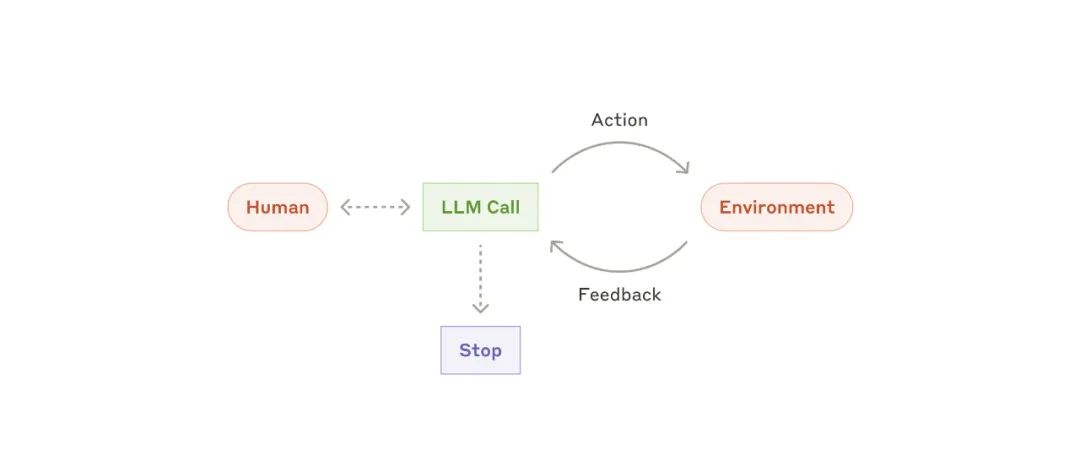 自主 Agent
自主 Agent-
用于解决 SWE-bench 任务的编程 Agent,这些任务涉及根据任务描述对多个文件进行编辑:https://www.anthropic.com/research/swe-bench-sonnet -
我们的 “计算机使用” 参考实现,其中 Claude 使用计算机来完成任务:https://github.com/anthropics/anthropic-quickstarts/tree/main/computer-use-demo
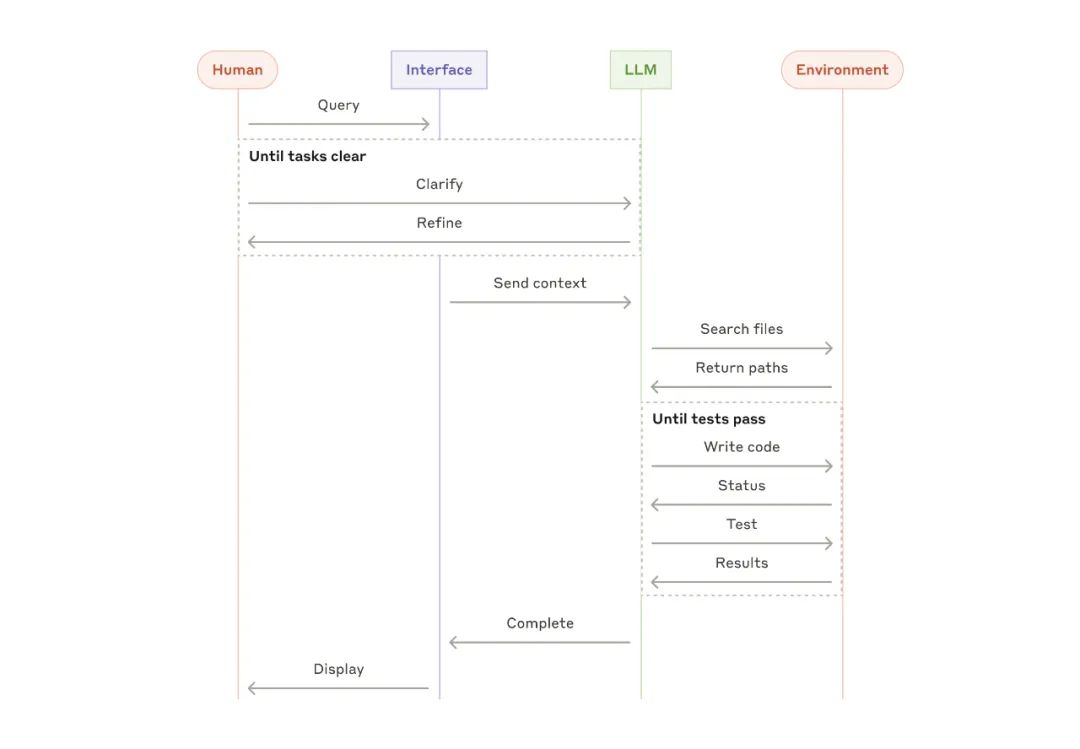 编码 Agent 的高级流程
编码 Agent 的高级流程#05
#06
-
保持 Agent 设计的简洁性。
-
优先考虑透明度,明确展示 Agent 的规划步骤。
-
通过详细的工具文档和测试,精心设计 Agent 与计算机的接口(ACI)。
#07
-
支持交互通常遵循对话流程,同时需要访问外部信息和执行操作;
-
可以集成工具来提取客户数据、订单历史和知识库文章;
-
诸如发放退款或更新工单等操作可以通过程序化处理;
-
成功可以通过用户定义的解决方案进行明确衡量。
-
代码解决方案可以通过自动化测试来验证;
-
Agent 可以使用测试结果作为反馈反复优化解决方案;
-
问题空间定义明确且结构化;
-
输出质量可以客观衡量。
#08
-
给模型足够的 Token “思考”,以避免其写入死胡同。
-
将格式保持在模型在互联网上自然看到的格式范围内。
-
确保没有格式上的 “额外开销”,例如,避免模型需要精确计算成千上万行代码的行数,或者在编写代码时进行转义。
-
将自己放在模型的位置。根据工具的描述和参数,是否很明显如何使用这个工具?如果是,那么模型也可能有相同的理解。好的工具定义通常包括示例用法、边界情况、输入格式要求和与其他工具的清晰区分。
-
如何改变参数名称或描述,使得更加直观?可以将其视为为团队中的初级开发者编写一个出色的文档字符串。当使用多个相似工具时,这一点尤其重要。
-
测试模型如何使用你的工具:在我们的工作台中运行多个示例输入,查看模型会犯什么错误,并进行迭代。
-
对工具进行防错处理。更改参数,使错误更难发生。
(文:AI大模型实验室)