



论文标题:
FlashRAG: A Modular Toolkit for Efficient Retrieval-Augmented Generation Research
中国人⺠大学高瓴人工智能学院
https://arxiv.org/abs/2405.13576
https://github.com/RUC-NLPIR/FlashRAG-Paddle
https://huggingface.co/datasets/RUC-NLPIR/FlashRAG_datasets

背景介绍
在大语言模型时代,检索增强生成已成为缓解幻觉问题的有效解决方案。通过外接知识库,大模型可以在⻓尾问题、垂域问题上有良好的表现。检索增强生成(RAG)技术的广泛应用和巨大潜力吸引了大量研究关注。
然而,近年来随着大量 RAG 算法和模型的出现,如何在一致的环境下快速构建并比较评估这些方法变得越来越具有挑战性。同时,如何利用大语言模型为文本更快更好的构建准确嵌入表示、如何加速推理生成速度等方面也日益受到关注。
为解决上述问题,中国⼈⺠大学高瓴人工智能学院联合百度共同发布了 FlashRAG-Paddle 框架,其中内置 36 个经过预处理的 RAG 数据集以及 9 种预实现的 RAG 算法,能够帮助研究⼈员高效地在 RAG 领域进行复现、基准测试和开发新算法。
同时,借助基于⻜桨框架 3.0 版本打造的 PaddleNLP 大语言模型套件,通过极致的全流程优化,为 RAG 中的检索器、生成器、重排器、精炼器提供从组网开发、预训练、精调对⻬、模型压缩以及推理部署的一站式解决方案。

FlashRAG-Paddle框架
FlashRAG-Paddle 是一个用于检索增强⽣成(RAG)研究的 Python 工具包,它基于国产深度学习平台⻜桨框架和 PaddleNLP 大语言模型套件构建,并针对国产芯片进行了优化。
-
全面且可定制的框架:包含 RAG 场景所需的核⼼组件,如检索器、重排序器、生成器和压缩器,可灵活组合成复杂的流程。
-
综合基准数据集:包含 36 个经过预处理的 RAG 基准数据集,⽤于测试和验证 RAG 模型的性能。
-
预实现的先进 RAG 算法:提供 9 种先进的 RAG 算法,可在不同设置下轻松复现结果。
-
高效的预处理阶段:通过提供各种脚本,如用于检索的语料库处理、检索索引构建以及文档的预检索,简化了 RAG ⼯作流程的准备⼯作。
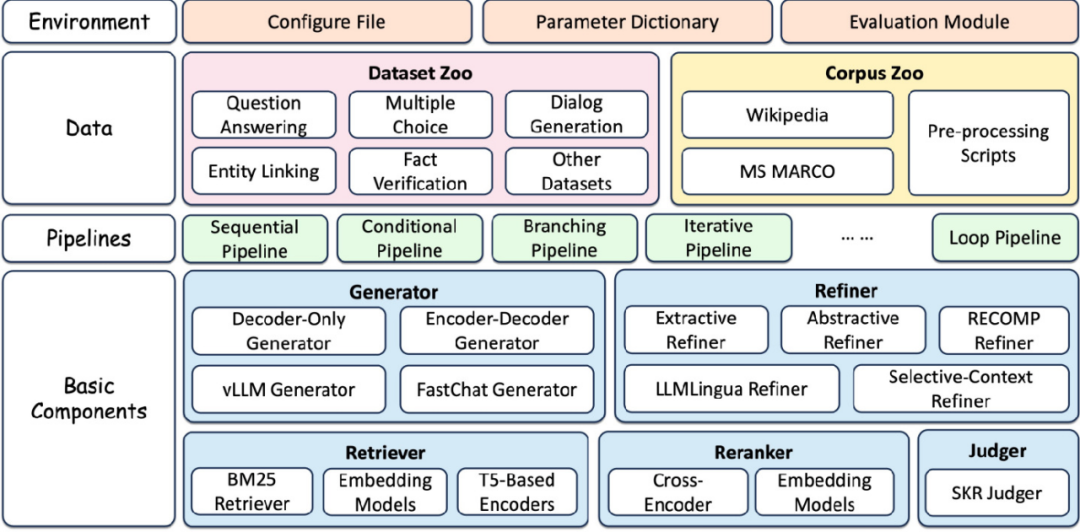
-
检索器 (Retriever):负责从知识库中检索与查询最相关的文档。FlashRAG 支持使用 embedding 模型以及基于词项匹配的 BM25 方法等。 -
生成器 (Generator):根据给定的文本(通常是查询和检索结果的拼接)生成最终的回复。框架支持使用各类 LLM 模型,并⽀持 FastChat、vllm 等加速方案。 -
重排器 (Reranker):对检索结果进行重新排序,以进一步提升与查询的相关性。重排器分为交叉编码器和双塔编码器两种类型。 -
精炼器 (Refiner):对输⼊的文本进行进一步的精炼和压缩,去除冗余信息。目前已支持抽取式、生成式、基于 LLMLingua 和基于 Selective-Context 的多种精炼器。
流程层位于组件层之上,通过组装各类组件实现端到端的 RAG 流程。基于各种方法的推理路径,我们将 RAG 流程分为了四⼤类:
-
Sequential:顺序执行 retriever、refiner、reranker、generator 等组件,是最基础的 RAG 流程。
-
Conditional:通过 judger 模块判断不同类型的查询,并选择不同的执行路径
-
Branching:并行执行多条路径,并将各路径的生成结果进行整合,代表工作如 REPLUG、SuRe 等。
-
Loop:通过迭代的⽅式交替执行 retriever 和 generator,代表工作如 Self-Ask、Self-RAG、FLARE、IRCoT 等。
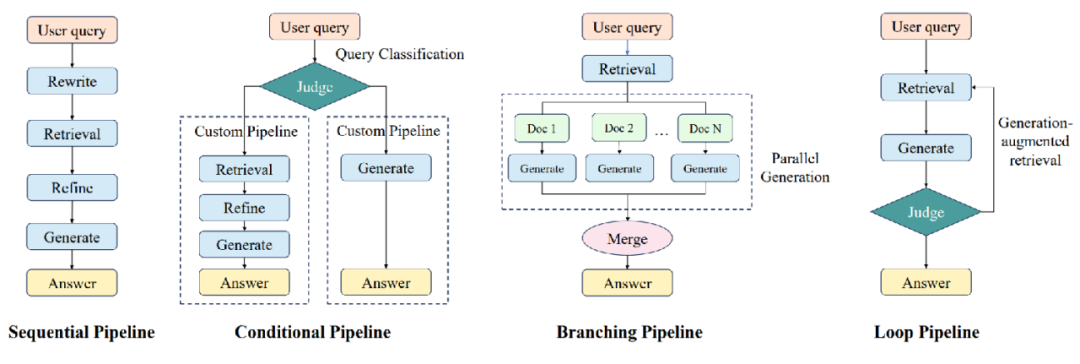
最上层为数据层,包括用于检索的语料数据以及用于评估的各种任务数据。在 RAG 流程运行完成后,会自动计算相关的评价指标并保存评测结果。
我们收集并处理了 RAG 研究中广泛使用的 35 个数据集,并对其进行了预处理,以确保格式一致,便于使用。对于某些数据集,我们根据社区中常用的方法对其进行了调整以满足 RAG 任务的要求。所有数据集均可在 Huggingface 平台上进行下载。

PaddleNLP: 超大Batch嵌入表示学习和多硬件高性能推理助力检索增强生成
PaddleNLP 是基于⻜桨框架打造的大语言模型套件,通过极致的全流程优化,为开发者提供从组网开发、预训练、精调对⻬、模型压缩以及推理部署的一站式解决方案。
-
模型组网简化与参数多样:PaddleNLP 通过统一分布式表示与自动并行技术,显著简化了组网开发的流程,减少了分布式核⼼代码量 50% 以上,结合多种并行策略 Llama 3.1 405B 等超大规模模型能够开箱即用。此外,PaddleNLP 预置了 80 多个主流模型的训练、压缩、推理全流程方案,满足了不同应用场景下的多样化需求。
-
精调与对齐性能提升:借助飞桨框架独有的 FlashMask 高性能变长注意力掩码计算机制和 Zero Padding 零填充数据流优化技术,PaddleNLP 有效减少了无效数据填充带来的计算资源浪费,显著提升了精调和对⻬的性能。以 Llama 3.1 8B 模型为例,其性能相较于 LLaMA-Factory 方案实现了 1.2 倍的提升,单机即可轻松完成 128K ⻓文的 SFT/DPO 任务。
-
硬件适配⼴泛与⾼效:PaddleNLP 基于⻜桨插件式松耦合统一硬件适配方案(CustomDevice),仅需适配 30 余个接口即可实现大模型的基础适配,支持英伟达 GPU、昆仑芯 XPU、昇腾 NPU、燧原 GCU 和海光 DCU 等多款主流芯⽚的⼤模型训练和推理。依托框架提供的多种算子接入模式和自动并行调优技术, PaddleNLP 实现了框架与芯片间的软硬协同性能优化,为用户提供了更加高效、稳定的模型训练和推理体验。
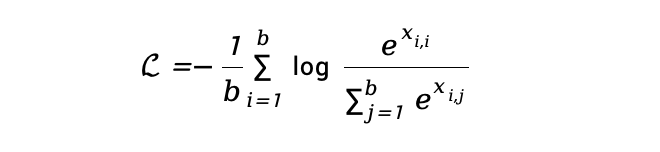
-
Weight Only INT8 及 INT4 推理,⽀持权重、激活、Cache KV 进行 INT8、FP8 量化的推理; -
注意力机制支持 PageAttention、FlashDecoding 等优化; -
支持基于 TensorCore 深度优化。
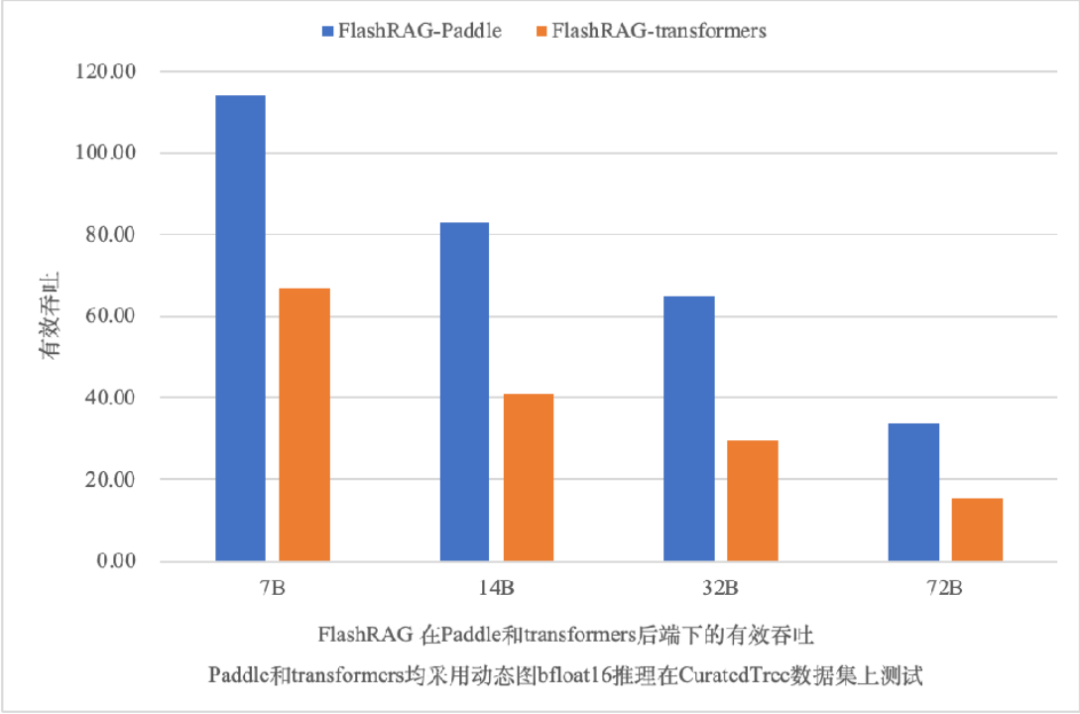
PaddleNLP 高性能推理通过内置全环节算子融合策略,获取更优推理性能。在 7B、14B、32B 和 72B 模型的推理性能上,PaddleNLP 后端相比 transformers 后端动态图推理提速 70% 至 119%。同时,Llama 3.1 405B 作为开源社区中的最大模型,PaddleNLP 推理也快速支持了此模型,单机 8 卡即可实现快速推理能力。
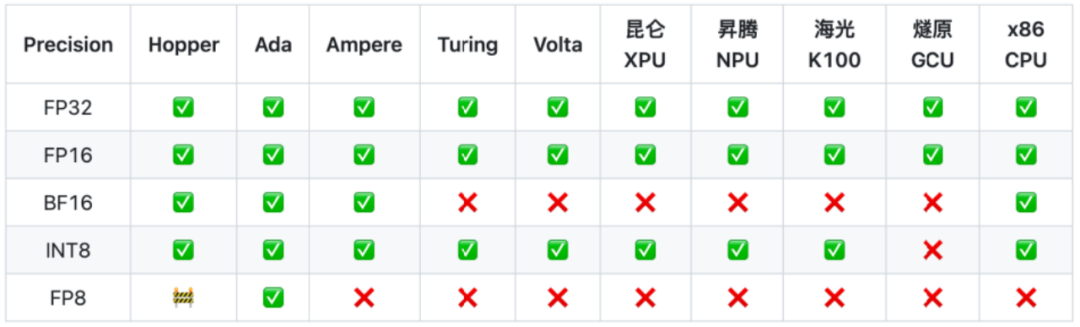
在硬件支持方面,⻜桨推理引擎展现出了强大的兼容性和灵活性。当前在支持英伟达 GPU 的基础上,还支持了国产及国际领先的 AI 芯片生态,包括昆仑 XPU、昇腾 NPU、海光 DCU、燧原 GCU、英特尔 X86 CPU 等多种硬件的大模型推理,不同硬件的推理入口保持统一,仅需修改 device 即可支持不同硬件推理。
PaddleNLP 的这一特性强化了 RAG 在更广泛的多硬件环境下的部署场景,满足不同用户的多样化需求,推动 RAG 在更多实际业务中的应用与落地。

FlashRAG + PaddleNLP 快速打造RAG文档问答应用
RAG(检索增强生成)技术巧妙融合了信息检索与先进的生成模型,通过从丰富的外部知识库中精准检索相关信息,为大型语言模型提供强有力的回答辅助。这一创新技术充分发挥了信息检索的精准性与生成模型的创造力,能够自动生成既高质量又准确,同时紧密贴合上下文的文档总结。接下来,我们将为您详细介绍如何仅需三步,即可轻松构建 RAG 文档总结应用。
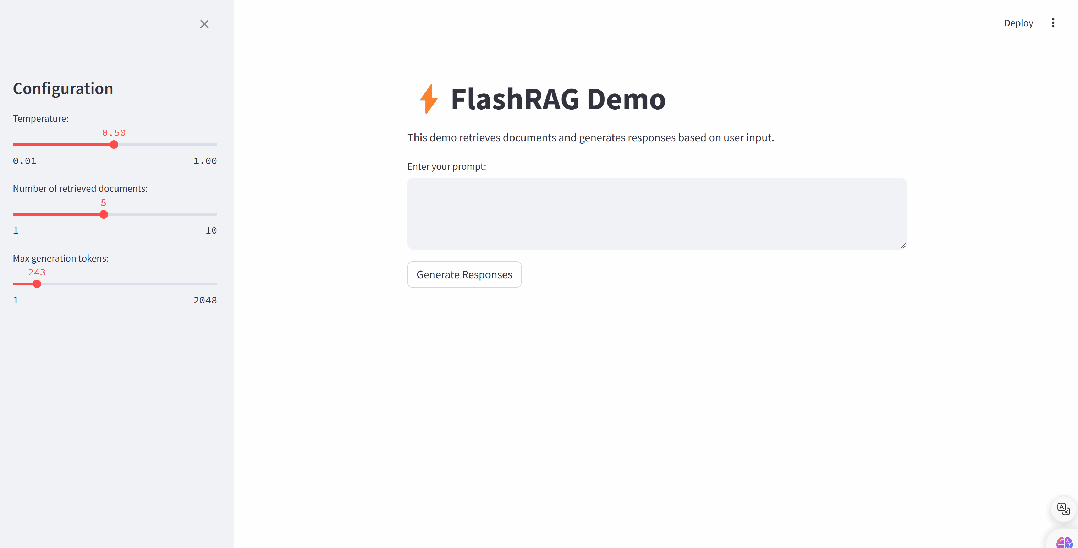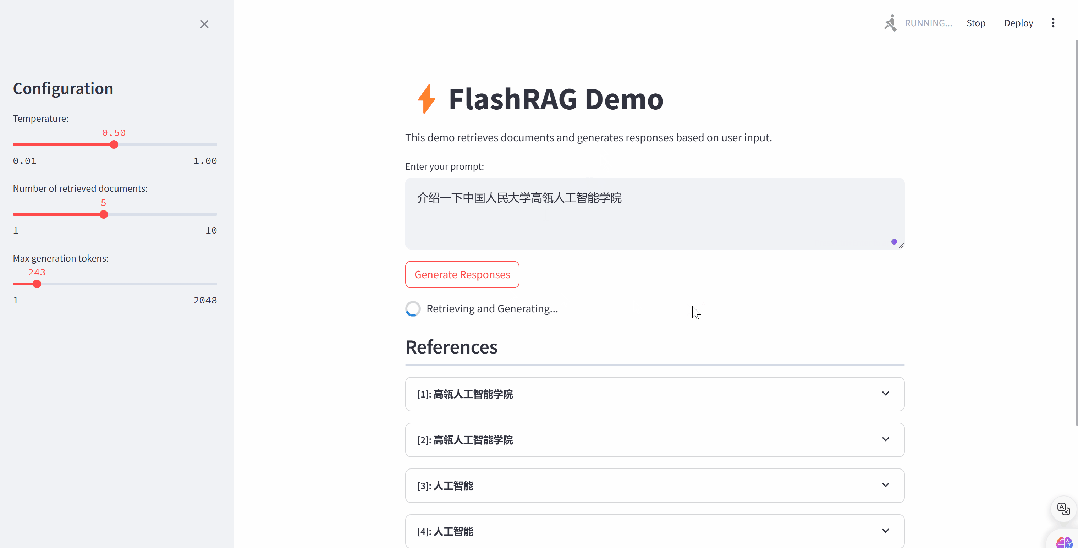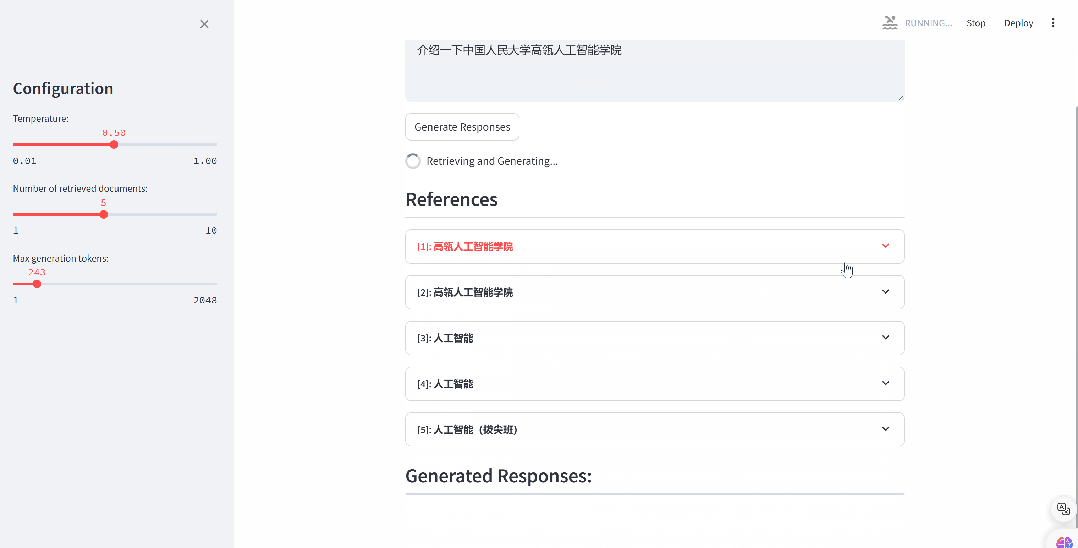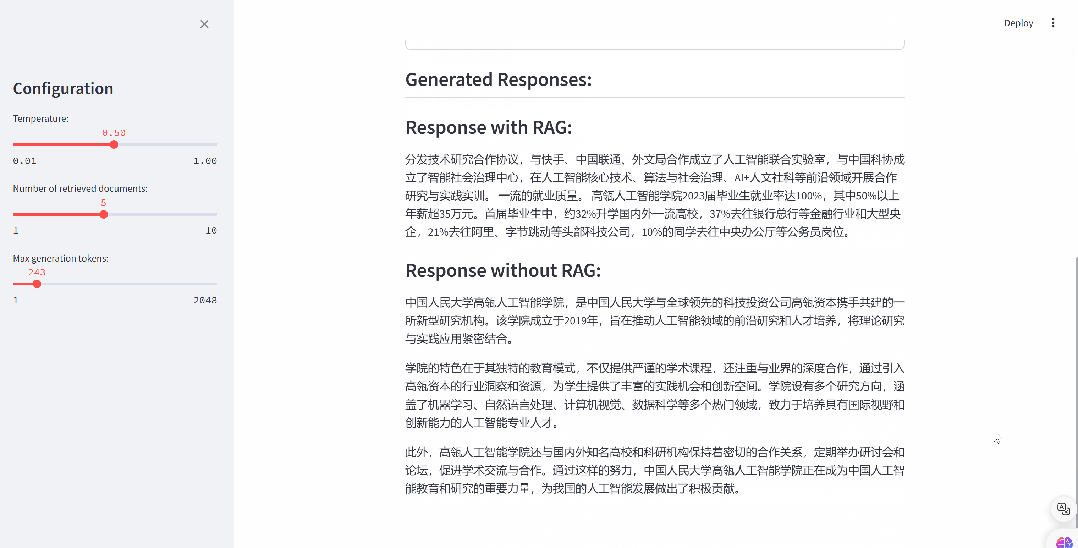
4.1 构建自己的语料数据库
步骤1:准备语料
{"id": "0", "contents": "contents for building index"}{"id": "1", "contents": "contents for building index"}
步骤2:索引
然后,使用以下代码构建您自己的索引。
-
对于密集检索方法,通过使用 embedding 模型,将文档嵌入到密集向量中,之后使⽤ faiss 集向量索引。
-
对于稀疏检索方法,基于 Pyserini 或 bm25s,依据词频将语料构建为 Lucene 的倒排索引。
python -m flashrag.retriever.index_builder \retrieval_method e5 \model_path intfloat/e5-base-v2/ \corpus_path indexes/sample_corpus.jsonl \save_dir indexes/ \use_fp16 \max_length 512 \batch_size 256 \pooling_method mean \faiss_type Flat
稀疏检索⽅法(BM25)
python -m flashrag.retriever.index_builder \--retrieval_method bm25 \indexes/sample_corpus.jsonl \--bm25_backend bm25s \--save_dir indexes/
4.2 配置检索器和生成器
步骤1:配置检索模型和生成模型
# 定义⼀个配置字典,包含所有必要的设置config_dict = {"save_note": "demo", # 保存备注,用于标识这次配置"model2path": { # 模型名称及其对应的路径"e5": "intfloat/e5-base-v2", # 检索模型e5的路径"llama3-8B-instruct": "meta-llama/Meta-Llama-3-8B-Instruct" # ⽣成模型llama3-8B-instruct的路径},"retrieval_method": "e5", # 指定使⽤的检索模型"generator_model": "llama3-8B-instruct", # 指定使⽤的⽣成模型"corpus_path": "indexes/general_knowledge.jsonl", # 知识库⽂件的路径,检索模型会从这⾥查找信息"index_path": "indexes/e5_Flat.index", # 索引⽂件的路径,⽤于加速检索过程}# 使⽤配置字典和⼀个配置⽂件路径来初始化配置对象config = Config("my_config.yaml", config_dict=config_dict)
# 定义⼀个带有引⽤信息(reference)的系统提示,AI在回应时会参考这些信息system_prompt_rag = ("你是⼀个友好的AI助⼿。""像⼈类⼀样回应输⼊,如果输⼊中有指令,请遵循指令进⾏回应。""\n以下是⼀些提供的参考信息。你可以使⽤这些信息来回答问题。\n\n{reference}")# 定义⽤户输⼊的基本模板,{question}会被实际的问题所替换base_user_prompt = "{question}"# 使⽤前⾯定义的配置和模板,创建⼀个带有引⽤信息的对话模板对象prompt_template_rag = PromptTemplate(config, system_prompt=system_prompt_rag, user_prompt=base_user_prompt)
# 根据配置加载检索模型,这是RAG⽤于从知识库中查找信息的模型retriever = load_retriever(config)# 根据配置加载⽣成模型,这是RAG⽤于⽣成输出的模型generator = load_generator(config)
4.3 检索增强,生成输出
# 使⽤检索模型,根据⽤户的查询(query)来检索最相关的topk个⽂档retrieved_docs = retriever.search(query, num=topk)# 将检索到的⽂档信息整合到对话模板中,形成带有引⽤信息的输⼊提示input_prompt_with_rag = prompt_template_rag.get_string(question=query, retrieval_result=retrieved_docs)# 使⽤⽣成模型,根据带有引⽤信息的输⼊提示来⽣成回应# 这⾥可以设置⼀些⽣成参数,如temperature控制⽣成的随机性,max_new_tokens控制⽣成的最⼤⻓度response_with_rag = generator.generate(input_prompt_with_rag, temperature=temperature, max_new_tokens=max_new_tokens)[0]# 打印⽣成的回应print(response_with_rag)

FlashRAG 和 FlashRAG-Paddle 的所有资源已开源,我们诚挚邀请国内外的研究⼈员和开发者使用、复现和贡献代码,共同推动 RAG 技术的发展和国产化进程!
https://arxiv.org/abs/2405.13576
https://github.com/RUC-NLPIR/FlashRAG-Paddle
https://github.com/PaddlePaddle/PaddleNLP

▼ 点击「 阅读原文」,立即报名
(文:PaperWeekly)