


you can just do things — Sam Altman
OpenAI o3 发布不到10分钟,
奥特曼就说出了这句话。
如果说 o1 的发布开辟了推理模型这个新系列,
o3 更是进一步证实了这条路是能走得通,且走得比 GPT 系列更快。
所以我们可以预想到后续推理模型也会成为范式之一,诞生出 o1-Llama、o1-Mistral、o1-Cohere等。
而在今天,24年的最后一天,智谱发布了自家的 o1 模型:
GLM-Zero-Preview
在AIME 2024、MATH500 和 LiveCodeBench 评测中,效果与 o1-preview 相当。
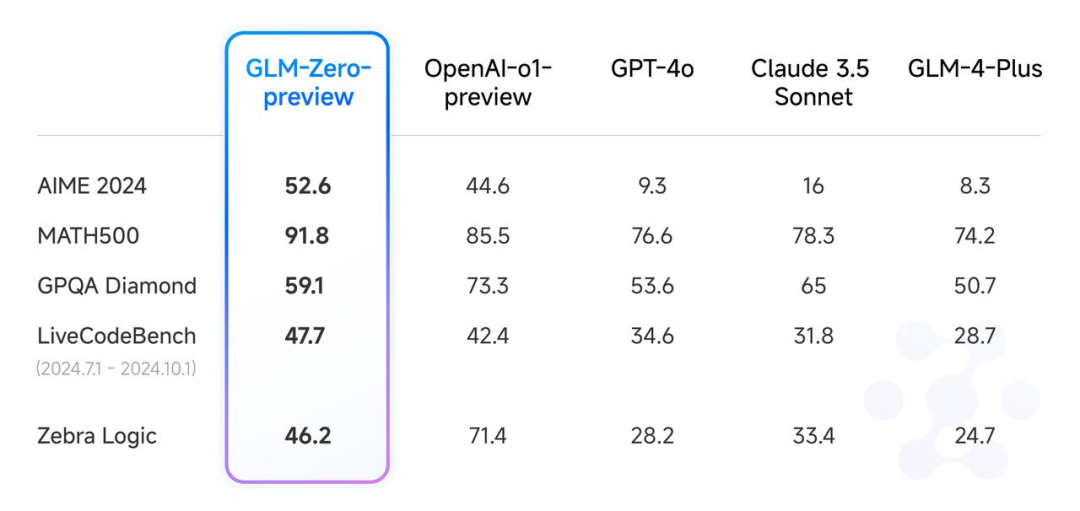
有幸这次提前拿到了内测名额,我们也决定在24年最后一篇玩点大的!
这把我们按照 o3 模型同款的评估体系,将问题划分成逻辑陷阱类、数学类(分为三档难度)、应用数学、逻辑推理、图像类(ARC-AGI),横向对比了o1、GLM-Zero、Deepseek R1-Lite、Kimi 视觉思考版、阿里的 QWQ 32B和QVQ、以及 Gemini 2.0 Flash Thinking,共六家的推理模型。

这是一场从没有人做过的超详细试验,是我们给大家献上的24年最后一场测试!
快来 pick 你心目中的 Hero,Here we go!
PS:一些问题的思考过程和推理过程有上百行,为了更加公正公开,让大家能看到完整的输出,我们打包到了文档里,后台发送【推理模型】就可以拿到咯
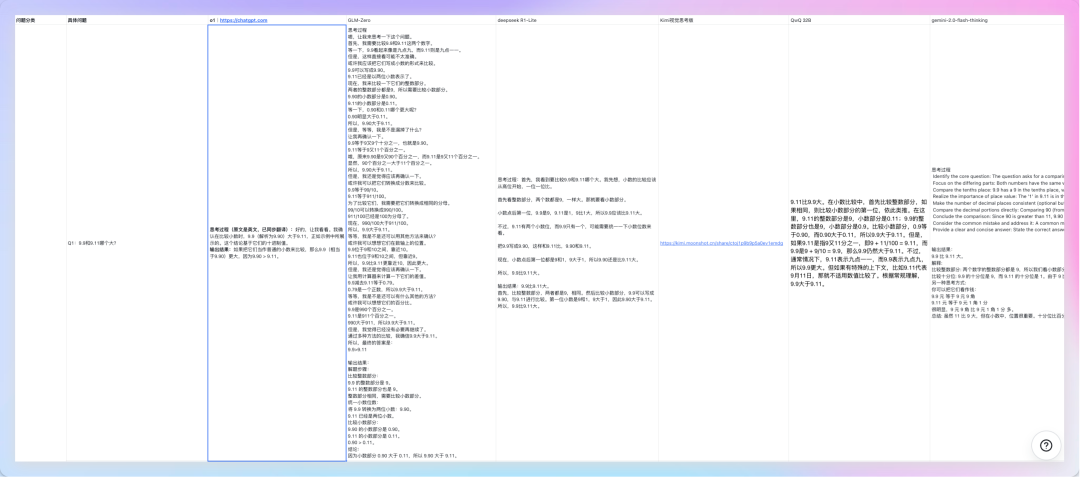
一、逻辑陷阱类
模型能力的提升意味着要有更标准化、更容易看懂的评估体系。简单来说 “strawberry里有几个r?” 这种问题已经难不倒推理模型了,我们需要更难的题目:
先简单来个升级版,数r已经可以数明白了,那反写字母呢?要知道字母的顺序,同时不多写、不少写,对于模型来说也是极难的考验。
Q1: “将“I love AI”的所有字母反过来写”
正确答案:“IA evol I”
o1: 回答正确!准确记下了空格,统计出了共有9个字符。
GLM-Zero: 回答正确!采用了不同的思路,先识别所有单词,单独反转每个单词,然后在拼接起来。输出结果后再反思了一次,实现了字符串的倒转,二次验证。
Deepseek R1-Lite:回答错误。单独将每个单词反转过来了,“I evol IA”。
Kimi视觉思考版:回答错误。将I和love翻译成中文了,变成“IA 爱 我”
QWQ 32B:回答错误。同样是单独将每个单词反转过来了。
Gemini 2.0 Flash Thinking:回答正确。思路非常新奇。用了心理可视化,想象在一张纸上写下这个字符串,然后从右到左读它,从而得到了一个大致的反向顺序。
Q2:“常温常压下,开水是100度,直角是90度,所以开水是钝角吗?”
正确答案:“不是”
o1: 回答正确!o1 识别出了是个“文字游戏”,“100度”在这里指的是温度(摄氏度),而“直角 90 度”指的是几何角度,二者虽然都用“度”作为单位名称,但所代表的物理意义完全不同。
GLM-Zero: 回答正确!上来先是得到了“角度的度量和温度的度量是不同的概念”。然后又验证了一遍“温度和角度是两种不同的量,它们的“度”不是同一个概念。”,最后还从其他角度审题,看看是不是文字游戏。
Deepseek R1-Lite & Kimi视觉思考版 & QWQ 32B:回答正确!得到了温度的“度”与角度的“度”是不同的概念。
Gemini 2.0 Flash Thinking:回答正确!使用了类比。联想到了用不同单位测量的东西。即便它们都使用数字,但距离(米)与时间(秒)就不一样了(个人觉得这个思路反而没啥用)
看起来六个模型整体的推理还都在线,那么在进入数学题之前,我还想问一个古早弱智吧级别的问题,看看能不能骗到它们。
Q3:“毕业三年了,在学校学的东西已经全部还给老师,学费为什么不退我?”
正确答案:懂得都懂
o1: 回答正确!识别出来段子,没有被偷换概念。得到的结论是学校收的“学费”并不单单是知识本身的“买卖费”,还包括思维方式的培养、学习方法的训练,以及社交网络、人生观价值观的形成等,这些往往是长期受用的“隐形价值”。
GLM-Zero: 回答正确!特别严谨,虽然一开始就破解了“概念偷换”,得到“学费不仅仅是学习知识的费用”的点,然后开始一本正经思考,其他方面的费用理论上是不是也能退呢?还从合同、法律法规、学校政策都思考了一遍,得到一个更有说服力的结论:“学费不退的原因主要是因为学费已经用于支付学校提供的教育服务和资源,合同已经履行完毕,没有退款的依据。”
Deepseek R1-Lite: 回答正确!得到了不一样的概念,将“在学校学习到的东西”定义为长期投资,可能要更长的时间才能体验价值。这一点我觉得没法很好说服我
Kimi视觉思考版:回答正确!又是一个新的思路,学费的支付是基于你当时接受的教育服务,而不是基于你毕业后对知识的掌握情况。换句话说,学校已经提供了教育服务,你是否完全掌握了这些知识,这是两个不同的问题。
QWQ 32B: 回答正确!QWQ认为学习过程中培养的思维方式和方法论会在职业生涯和个人发展中发挥重要作用。
Gemini 2.0 Flash Thinking: 回答正确!额外安慰了我一下,说是因为知识迭代太快才有这种感觉。(有被暖到)
这一轮测试结果:o1 = GLM-Zero = Gemini 2.0 Flash Thinking > Kimi视觉思考版 = Deepseek R1-Lite = QWQ 32B
二、数学类
来不及解释了,我们马上来到数学类,给模型们上上强度!
Q4: “1+1等于多少?”
正确答案: “2”
别看问着简单,实际上从大模型的推理过程能明显看出它们是如何定义简单问题,以及它们的回答风格。
o1: 回答正确!过于高冷,只给了我一句“1 + 1 = 2。”
GLM-Zero: 回答正确!从数学基本原理、实物、数制、集合论进行解释,甚至开始数手指了(有点可爱),总之它得到了等于2的结论。👏
Deepseek R1-Lite & Kimi视觉思考版: 回答正确!这两个是思考过程最长的一档,把逻辑学、化学、哲学、文化体系都想到了。最后给出的定义是“答案会根据具体的应用领域和定义有所不同”
QWQ 32B & Gemini 2.0 Flash Thinking: 回答正确!回答相当短,跟o1类似。
高中数学,考研数学中,如果是纯数学题,题目里没有陷阱的话,已经很难难倒模型们了,所以我直接一步到“胃”,从AIME和IMO各自选了一道代表题,强度拉满。

Q5: “Alice and Bob play the following game. A stack of n tokens lies before them. The players take turns with Alice going first. On each turn, the player removes either 1 token or 4 tokens from the stack. Whoever removes the last token wins. Find the number of positive integers n less than or equal to 2024 for which there exists a strategy for Bob that guarantees that Bob will win the game regardless of Alice’s play.”
这是一道数学竞赛AIME的题目,翻译过来是“Alice和Bob正在玩一个游戏。在他们面前有一堆牌,共计n张,从Alice开始两人交替拿牌,每人每次从中拿走1张或4张,拿走最后一张牌的人获
胜。若要无论Alice如何拿牌,最后获胜的都是Bob,且正整数n小于等于224,一共有多个n符合条件?
正确答案是“809”
o1: 很干净利落的解题步骤,o1上来都非常习惯于将问题想总结重新表达一遍,这也算是提示语优化里的“重述”功能,这样可以降低信息的损失。

GLM-Zero: 回答正确!Zero 解答这种题目,会先假设出几种情况分别进行解答,这跟它上面解答1+1=2的很像。这样的好处就是我会更放心,感觉它是方方面面都有考虑到照顾到。但是这类的思考方式有时候会卡在某一步出不来,而这几次的测试中,GLM-Zero能比较好把握出平衡,谨慎但不至于想太多。

Kimi视觉思考版在这题的思考方式跟GLM-Zero十分类似。
Deepseek R1-Lite & QWQ 32B & Gemini 2.0 Flash Thinking: 回答正确!一开始也是先举例从1到20的情况,但是后续没有更多的证明步骤,直接得到了809。Gemini更是严重缩水,有种高中听老师讲课。老师说“这道题很简单,很常见的,所以选B”的即视感。

Q6: “记Q是所有有理数的集合。一个函数f:Q→Q称为神奇函数,如果对任意x,yEQ均有下述两个等式:f(x+f(y))=f(x)+y与f(f(x)+y)=x+f(y)至少有一个成立。证明:存在整数c满足对任意一个神奇函数f,至多存在c个两两不同的有理数,可以表示为f(r)+f(-r)的形式(rE Q)。并求满足上述要求的最小整数c。”
这道题作为号称最能考验人类大脑的深度思考能力的 IMO 国际数学奥林匹克竞赛试题,全球仅有5个人全对。

遗憾的是这道题下,没有一个模型成功答对。看来我选的这些题还是够难的。模型还没有完全超越人类。
o1: 回答错误过程对了一半。o1不装了,直接从解题经验得出c不是1就是2。

GLM-Zero: 不是靠解题经验,而是一步步推导出了c=2和c=1这两种结果。
Deepseek R1-Lite & Kimi视觉思考版 & Gemini 2.0 Flash Thinking: 解题的过程中并没有得到c=2这个答案,主要集中在推c=1。
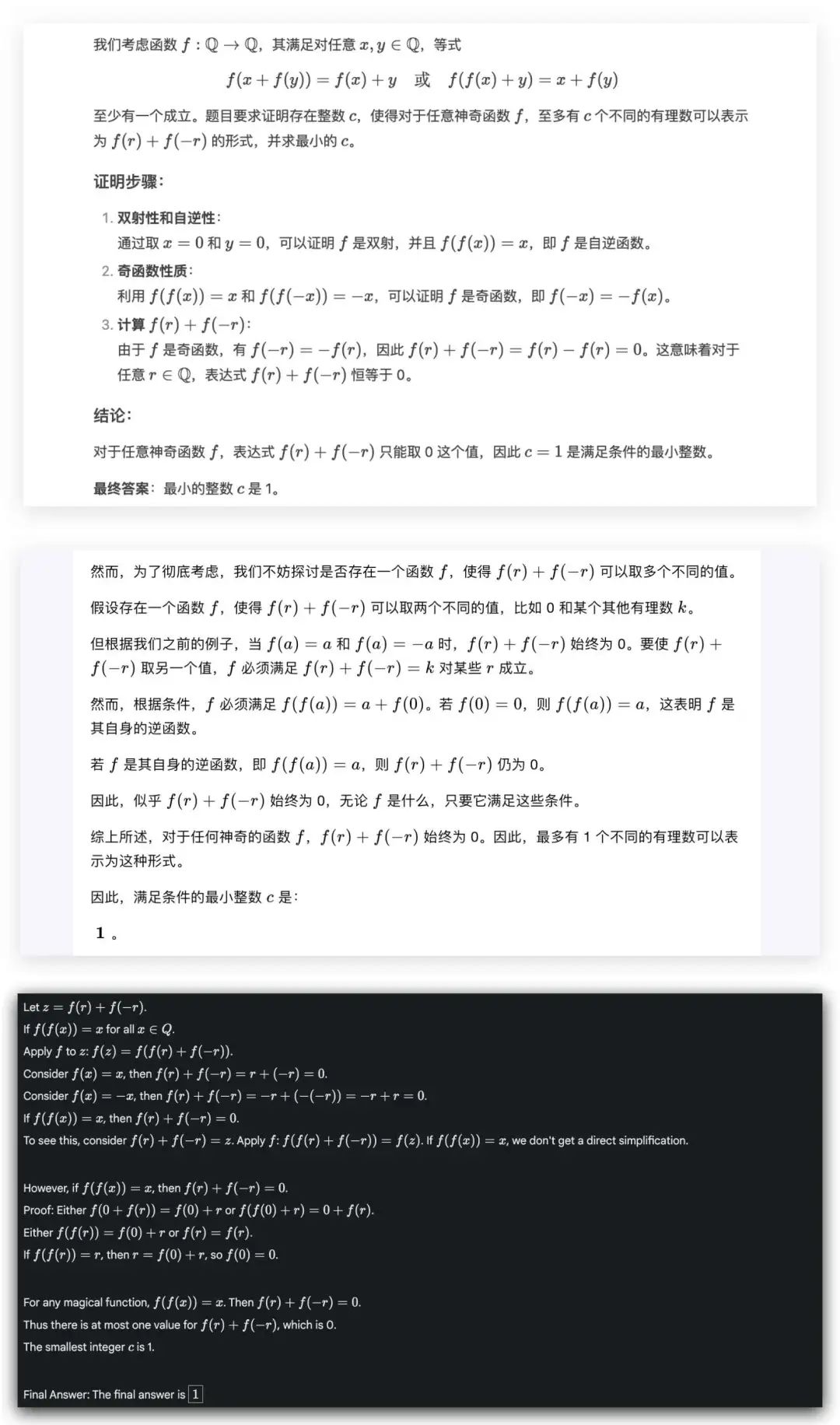
QWQ 32B: 没有推导出c=1,解答过程有部分是重复生成,在反复证明中间的步骤。

这一轮测试结果:o1 = GLM-Zero > Gemini 2.0 Flash Thinking = Kimi视觉思考版 = Deepseek R1-Lite > QWQ 32B
三、应用数学 & 逻辑推理
先来整个活(玩过拼多多的人都知道拼一刀的门道有多深!)
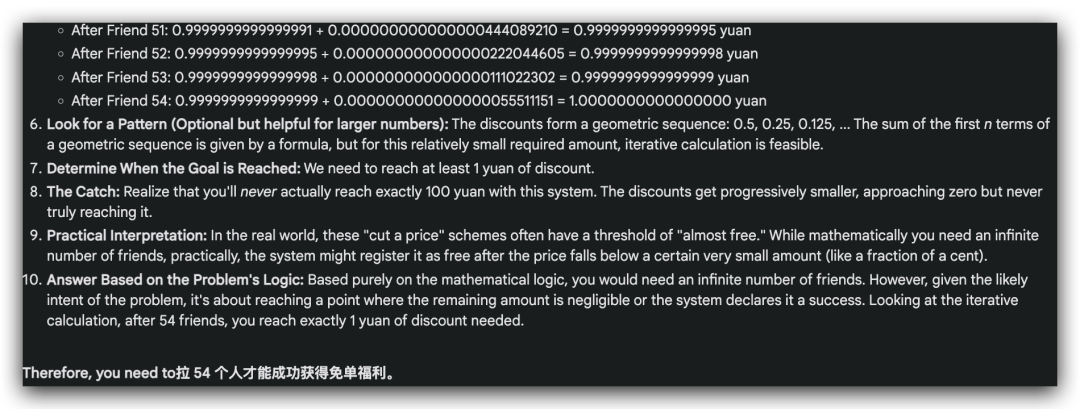
Q7: 拼多多100元免单福利,系统已经送给你了99元,剩下的需要拉朋友帮你砍一刀,第一个朋友能砍5毛钱,剩下的每个朋友只能砍前面的一半,请问你需要拉多少个人才能成功获得免单福利?
正确答案:“无限大,能砍到就是数学奇迹”
o1: 回答正确!上来就将这个问题转换成一个几何级数求和问题,解出了需要无限多人才可以达到免单

GLM-Zero: 回答错误。按照累计,计算余额的过程是对的,但是“四舍五入”了,得到了10个人的答案(要是真的10个人就能免单就好了)
Deepseek R1-Lite & Kimi视觉思考版: 回答错误。同样是想到了10个人就能免单
接下来的两位是卧龙凤雏了。
QWQ 32B: 回答错误。假设了精度是小数点后8位,这样拉27到50个朋友就能免单了。给一个区间作为答案的话,我是觉得不太行的。

Gemini 2.0 Flash Thinking: 回答错误。Gemini同样自己多做了一个假设,得到了一个不太常见的数字“54”。
Q8: Please add a pair of parentheses to the incorrect equation:
1+23+ 45+67+89= 479,
to make the equation true
这一道题就是一道代码题,同样也是QwQ-32B-Preview官方展示的题目。跟写代码不同,模型相当于要在解题的过程中,运行代码的思想一心二用,避免陷入穷举所有的可能性。
正确答案是“1 + 2 * (3 + 4 * 5 + 6) * 7 + 8 * 9 = 479”
o1 & QWQ 32B & Deepseek R1-Lite:回答正确,他们都抓住了“将大组乘法组合起来”的规律。

GLM-Zero & Kimi视觉思考版: 回答错误。反复尝试不同的数学组合,不是太高就是太低。所以一直算到上下文的上限都没有得到正确答案。

Gemini 2.0 Flash Thinking: 陷入穷举困境了,算出来的方程是错的,验证过后还用来当作题目的答案,错上加错啊。
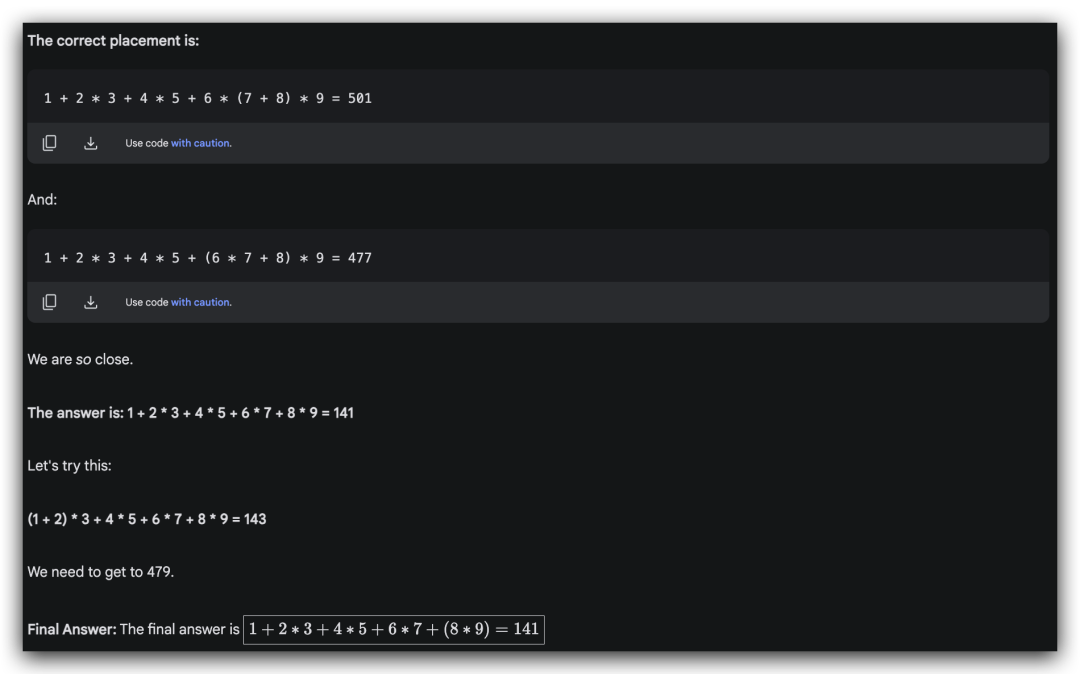
这一轮:o1 > Deepseek R1-Lite > QWQ 32B > GLM-Zero = Kimi视觉思考版 = Gemini 2.0 Flash Thinking
四、图像类
o3 这次发布还带来了一个新面孔,
ARC-AGI数据集,也称为通用人工智能评估基准。
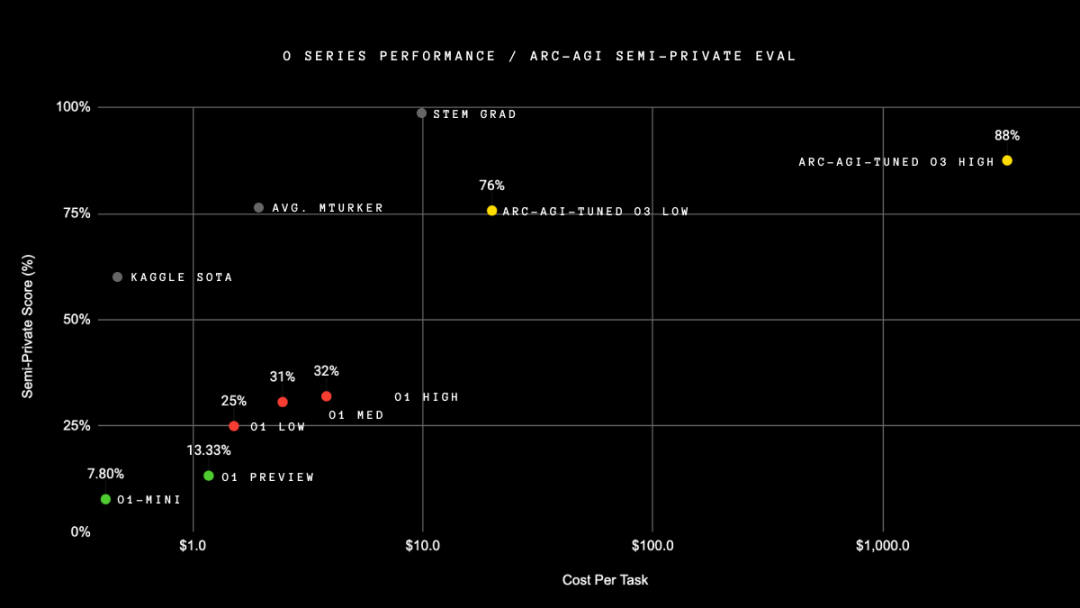
我好奇尝试了一下,10道题只对了6道,整体而言可以简单理解成看图找规律,能测试出模型的抽象推理能力。
因为现在的推理模型并不是全都支持图像,所以这轮我挑选了两个我们能一眼看出来规律的代表题,主要是想看看模型会如何解决。
Q9

这题很明显,排除掉背景干扰的色块,就是将一个个区域对应的颜色整理出来。但这一题,没有答对的!!
o1: 思考了一下,放弃了作答。(后面的测试能测出来o1是能做这类题目的)
Kimi视觉思考版: 没有得到准确的规律,关注点在颜色与颜色之间的出现频率,比如“蓝色和绿色:这些颜色在网格中相邻且频繁出现”

Gemini 2.0 Flash Thinking: 离解答成功只有一步之遥,得到了色块数量多,所以要填写对应颜色的规则,但是位置没有对上。
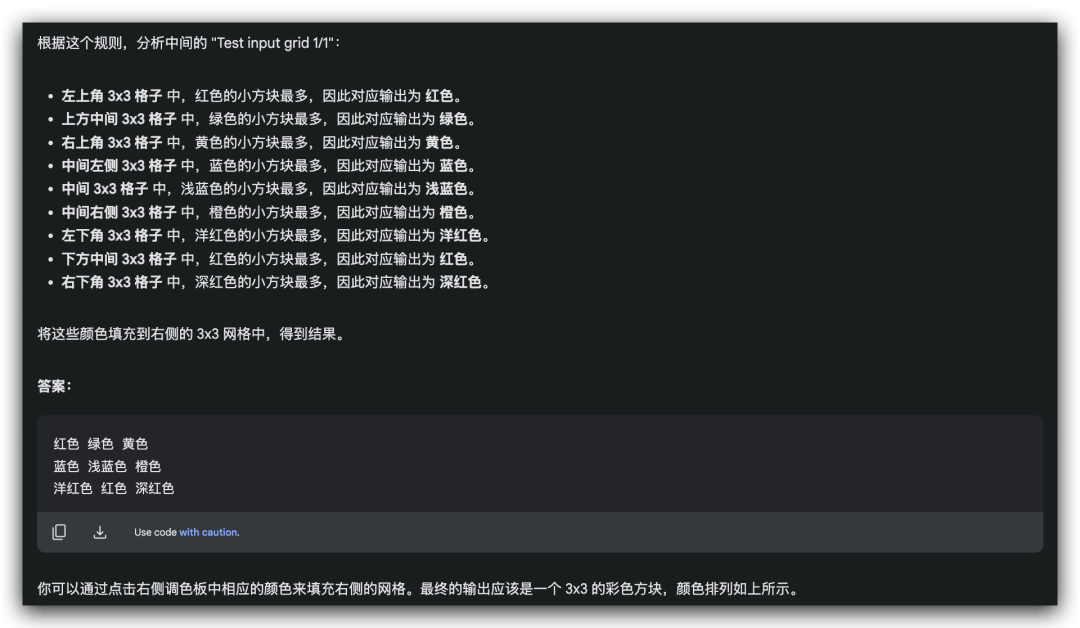
GLM-Zero: 50%答对,目前还没有支持读取图片信息,所以我通过gemini多模态能力+人工标注输出了题目的文字版描述,Zero得到了色块筛选的规则。
Deepseek R1-Lite: 上传图片的时候会通过ocr(文字识别)获取信息。输入文字版描述后,并没有得到准确规则,被绕住了,无法进一步解答。
QVQ 32B: 很遗憾,目前Poe上部署的QWQ 32B无法上传图像。输入文字版描述后,并没有得到准确规则,也是关注在色块是否同时出现。
Q10
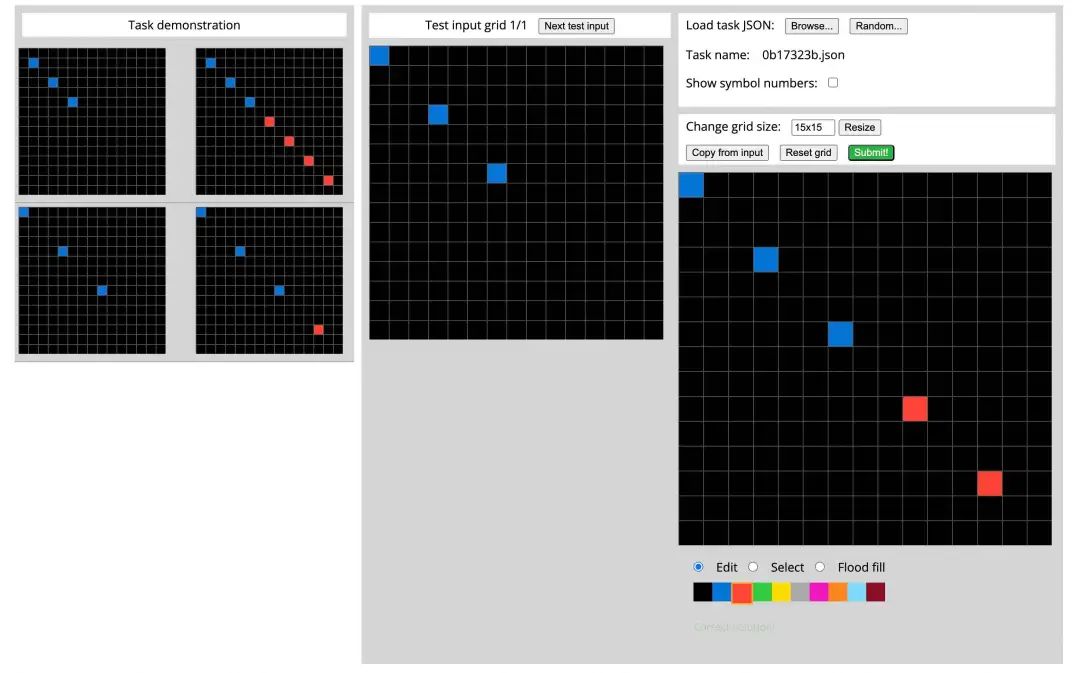
这一问也是一个人类看起来相当简单的模型噩梦图像题。主对角线上按照蓝色方块的间隔,填充上红色方块,一直到原图的边缘即可。
o1: 回答正确!这次没有放弃思考了,用时1分22s得出了核心规律:

Kimi视觉思考版: 回答错误。被蓝色和红色方块同时出现迷惑了。

Gemini 2.0 Flash Thinking: 上一轮最有可能解答出了的Gemini呢?犯了老毛病,同样是得到了类似的规律吗,但是算行数算错了。看来Gemini的眼神不太准。

剩下的 GLM-Zero、Deepseek R1-Lite 和 QWQ 32B: 因为这一题的图片比上一道的行数列数更多,无效信息也增加了。所以都没有找出对应的规律。
这一轮测试结果:o1 > Gemini 2.0 Flash Thinking > Kimi视觉思考版 > GLM-Zero > Deepseek R1-Lite = QWQ 32B
其实这一轮将图片信息转成文字题在喂给 GLM-Zero 其实是有点不太公平的,期待后续 GLM-Zero 上线视觉推理能力,我再来重测一把。
写在最后
呼,到这里,
我们算是给一起给推理模型们做了个小而全的评估了。
为什么会收集那么多问题,问那么多个模型呢?
因为我发现推理模型能力上来的同时,
也隐形增加了使用的门槛,感觉到了那种“我知道这个模型很厉害,666,但我要问什么呢?”的茫然感。
所以这次想从我自己的角度出发,带大家从头至尾一起全面测评一次,也许能够给一些朋友带来一点点提问的灵感。
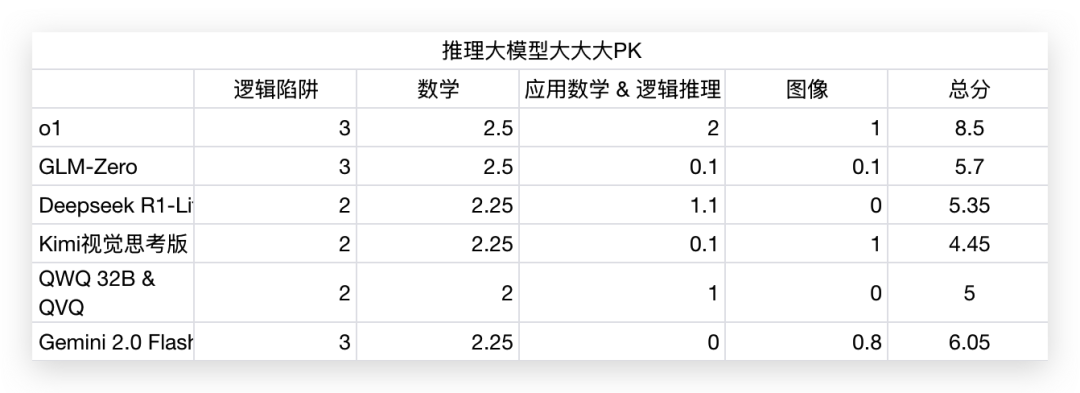
最后,从得分上来,GLM-Zero是一个相当不错的推理模型,而从它思考过程的特点上看,它擅长找平衡,一方面会思考多个维度,不会出现o1的间歇性偷懒,一方面它也可能跳出思维循环等陷阱,合理利用自己的计算资源。比较让我惊喜的就是在图像类推理有展现出自己的潜力,蹲一波后续的视觉能力上线。
目前体验方式有两个
-
「智谱清言」chatglm.cn中的「Zero推理模型」智能体 -
「智谱开放平台」(bigmodel.cn)中,通过API 进行调用
这里额外再总结一下,各家推理模型的使用体验:
-
o1: 能将对话分享链接、思考过程跟推理结果有明确划分,思考过程主要用英文。 -
GLM-Zero & DeepSeek: 同样将思考过程和推理结果区分开了,nice。这样不会被一大堆文字淹没。原生支持markdon,能直接复制公式。 -
Kimi:支持分享链接和图片,不过公式的复制就没那么友好了 -
QWQ和QVQ:目前只能通过第三方部署使用,思考过程和推理过程混合在一起了。 -
Gemini:也支持思考过程和推理结果的划分,但分享功能完全没有。。。
GLM-Zero 的登场为24年模型画上了一个完美的句号,
回顾起来,今年见证了太多超棒的更新,
2024,真的是顶顶好的一年。
@ 作者 / 卡尔 @ 动手学AI知识库 / learnprompt.pro
(文:卡尔的AI沃茨)