

又到了一年一度年终总结时刻,不过今年这篇总结,跟往年的不同,今年只聊LLM。
2024年是LLM蓬勃发展的第二年,只能说发展确实十分迅速,层出不穷的,但也让很多人看清了LLM现有的缺点。今天就跟大家分享一下2024年又做了一年LLM的感受。
当然,这篇也是陆陆续续写了好几天,作为2024的结束语送大家。
懒人目录:
-
LLM的开源社区让我大为震惊
-
做好数据就等于LLM已经做好了90%
-
还有Continue-Pretrain吗?
-
RAG很容易落地吗
-
2024没有Agent,只有WorkFlow
-
多模态模型不如纯LLM智能
-
O1给LLM又续了一条命
-
2025年LLM的发展方向
好久没写个人感悟的长文了,如果觉得不错,欢迎一键三连,你们的支持是我创作的动力!!!
LLM的开源社区让我大为震惊
首先感谢一波Qwen。
其次,我要先承认,我是Qwen吹。对不起,只感谢Qwen确实对其他开源模型有些不公,但实事求是的讲,论模型尺寸的多样性、更新的速度、以及全面性,Qwen确实开的够多。
当然LLama、GLM、Yi、DeepSeek、MiniCPM等等,也都在发力中,甚至前两天DeepSeek还开泼大的,671B,也是望尘莫及,虽然看着很强(看别人说的),但是我真没法跑,真没那么多卡。但反过来想一想,这也是LLM应用落地的现状,有时候从成本和推理优化的角度出发,本地化部署不如API调用,但出于数据安全等考虑,又不得不,直接僵住。
此外开源的很多端侧模型(SLM)也是发展的很好,在降级成本的情况下,很多任务上做的都很不错。
我有个朋友说,做人最忌讳是既要有要,参数量就在那儿摆着呢,要不就别用SLM,既然已经决定想省了,就别那么在乎效果了。
我又要祭出我拿着陈年老图了,虽然很多新模型还没放到上面,但是足以说明,开源社区做的越来越好,不能说智能性已经追赶上了闭源模型,但是再大多数任务上,开源模型已经可以做的足够好了。
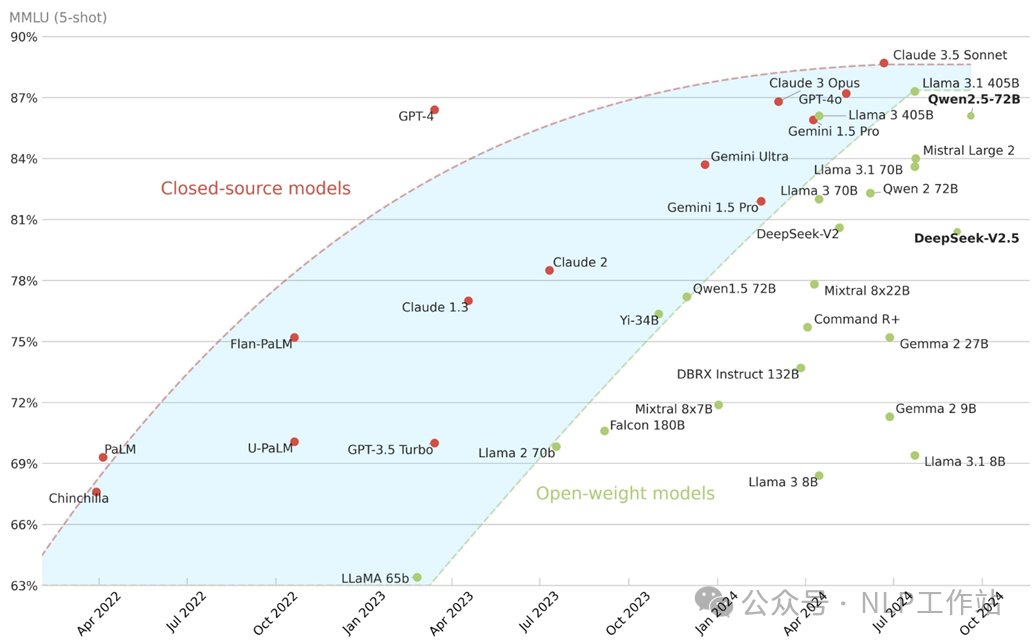
最后,我想说,虽然在闭源模型上,中国相较于国外是还有一定差距,但在开源模型上,我想大声喊出那句,“我们是冠军”!
请别再无脑吹“Llama”了,我们也有,而且更强!起码2024年是这样!
PS:欢迎评论区说出你们心中最佳的开源模型!
做好数据就等于LLM已经做好了90%
90%是我随便说的哈,爱较真的的朋友不要在意,理解我想表达的意思就行,就是数据很重要。
其实2023年的时候,我们已经知道数据的重要性了,数据的质和量都很重要。很多的算法工程师的日常工作就是洗数据,不愿面对也没有办法,这就是事实。
无论是在Pre-training阶段,还是Post-training阶段,数据的合成与收集、高质量数据过滤、多样性筛选都是必不可少的。单机的模型微调deepspeed足够保证训练效率,又有多少人真正读过megtron的代码呢?不过有时也真的没必要,可能真的也用不上,很多时候修改数据路径,修改模型保持路径之后,直接bash sft_train.sh就结束了。
所以,大部分时间还是在做数据的工作。
同时,合成数据也成为了2024年的关键词,在Post-training阶段,合成数据已经成为了必不可少的内容,而且在Phi-4的报告中也显示,预训练阶段,合成数据使用的占比也是高达40%。
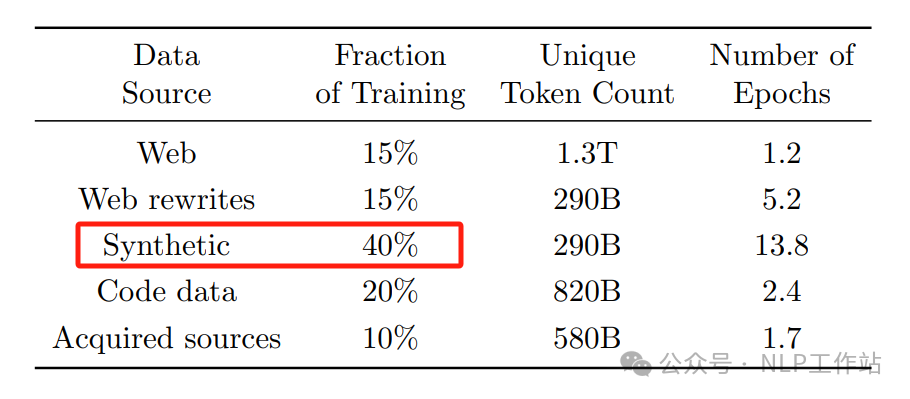
图片来自:Phi-4 Technical Report
并且Ilya在NeurIPS 2024的演讲中也提到“Synthetic data”是未来的发展方向,可见合成数据的重要性。
这里有一份合成数据的相关paper的仓库,感兴趣的自提(一位群友整理的工作)。
Github: https://github.com/pengr/LLM-Synthetic-Data
说回数据的重要,现在对于很多企业或者产品的核心竞争力,我依然依然是数据。
我有个朋友,每次在Qwen、LLama等大模型有更新的时候,就说今年的KPI稳了,直接老数据+新模型,效果又拉满了!
那么如果没有老数据的你,该怎么办!所以现在对于大多数人或企业来说,数据的积累(数据本身、数据合成的方法、数据清洗的方法)才是现在的核心竞争力。
当然,随着模型的不断发展,本身使用的数据越多,那么对没那么封闭的领域的冲击也会越来越大,这也无法避免的,基础的LLM终将会吃掉一些领域的。
还有,你觉得为什么会有那么多API免费调用,我不说,大家自己体会。
我有个朋友,经常说你的数据其实也是垃圾,别人也不一定使用,所以也不用担心,想那么多。
最后,想吐槽一下,别老想着三五百条微调大模型,真没必要,不如ICL+动态示例,来的实在~~~
还有Continue-Pretrain吗?
你会发现,在2023年经常听到的Continue-pretrain在2024年已经很少听到了,反而Post-training听到的次数越来越多。
那么还有Continue-pretrain吗,我个人认为还是有的,不过确实很少有人可以或会做了,主要原因有以下几个方面吧。
CPT会影响模型通用能力,虽然通过数据混合,可以有一点的改善,但依然无法避免。而在进行CPT的时候,领域数据不能太少,要不然没少效果,但是很多想做的人,其实没有很多领域数据。
我有个朋友,说自己积累了10年的行业数据,想训练一个行业大模型,结果一统计数据,只有2w条数据。
CPT的过程,一般是基于Base模型训练的,而现在很多大模型效果好的重点很大程度上是靠Post-training阶段,那么就带了一个问题,你CPT之后,是否有能力做好Post-training呢,答案显而易见。既然如此,还不如放弃CPT,直接构造SFT数据来的实在。
此外,还有就是性价比的问题,CPT带来的收益是否可以cover住你的成本,是否可以通过更加廉价的技术手段来提高领域、场景上的效果,比如RAG。
还有随着大模型本身预训练数据的增多,Qwen2.5的预训练数据已经达到了18T Tokens,可能你所在领域的知识,早已被覆盖,也许你的CPT完全是在自嗨。
当然,上面情况你都已经考虑到,你有足够的领域数据,你只在乎领域上的效果,你有卡,但不足以从头Pretrain的时候,你依然可以选择CPT,毕竟直接站在巨人的肩膀上看世界,更容易一些。
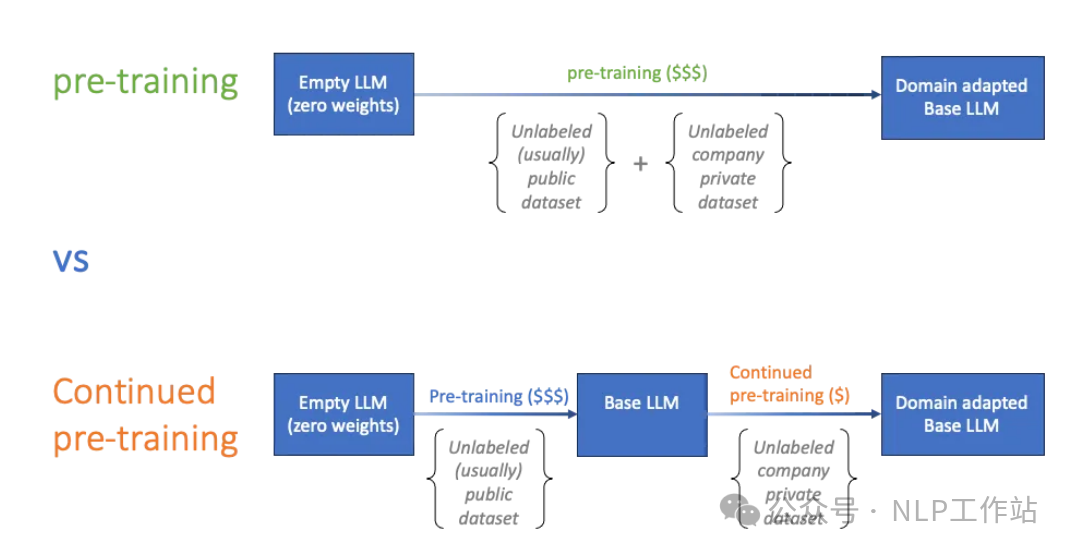
那么,你觉得CPT还需要吗?
RAG很容易落地吗
在2024年年初的时候,我曾在知乎上写过一个回答,预测2024年LLM主要的发展和落地方向,当时我说上半年应该会以RAG为主的知识库问答成为主要落地场景,下半年应该会以Agent为主进行应用落地。

图片来自: https://www.zhihu.com/question/638178103/answer/3352094177
2024年做了很多大模型落地项目,基本上都是以RAG为主,但是RAG落地真的很容易吗?真正落地的艰辛,只有交付过的人才懂。
我有个朋友说,现在很多客户被一些文章洗脑洗坏了,总是觉得xxx家的模型是万能的。
对于RAG来说,第一大坑,就是文档解析,大多数客户的文档都是PDF的,甚至很多偏老的企业的文档还都是扫描版的,那么如何将文档进行更好地解析,成为了RAG第一道关卡。
很多人会说,不就OCR嘛,也有很多开源的文档解析工具。我只想说,谁用谁知道了。就拿表格数据解析,只能说一言难尽。另外,新的抉择就是解析后的结果数据要不要二次人工校对。也许你觉得大模型有能力对文本错误内容进行纠错,但是这会与遵循文档原始内容相违背,幻觉加重。
第二大坑,就是向量召回了,你会发现,LLM的能力已经不错,整体效果的限制在于检索不到相关文档片段。很尴尬,不是说找不到,而是找不全,对于一些比较、总结的问题,如果基础素材补全,那么回答的结果就会有遗漏和偏差。并且Q-D匹配,会由于D向量的内容较多,向量化的结果不一定好,需要对向量模型进行二次训练,针对性优化,你最终发现,又干回老本行了。
接下来,有一大坑就是针对多模态内容的回复。当然也许一些客户没有提到这个问题,那么你应该感到庆幸。做了一些VQA的实验,只能说不稳定,结果极其不稳定。不是说回答不出来,是很多你觉得应该回答出来的,回答的令人大跌眼镜。当然也会有一些替代方案,比如先将图片、表格预先生成QA或描述,再进行问答。
最后一坑,就是模型本身效果的问题,不同家、不同使用者,会对最终的答案的形式、精炼程度、额外内容容忍度会不同,那么LLM本身还是需要针对性微调。并且你会发现很多answer,打眼一看还不错,仔细标注就会很纠结,可对可不对。还有就是项目交付就有准确率的问题,客户们已经被不良PR文洗脑,认为RAG的准确率起码要在95%+。但如果你用6B、7B、14B级别的模型,有时也挺难的,没人会在意你的痛苦,大家只知道RAG很好落地,可以解决幻觉。
所以,我想说,RAG搭出来很简单,做好还是有难度的,不是上嘴皮一碰下嘴皮就可以了。不过用心去做,还是很多项目顺利完了交付。
当然今年出的GraphRAG也是火了一阵子,但由于自动构建Graph的成本问题,也有相关的优化方案,这里不再过多赘述了。最后推几个RAG相关paper的仓库,需要自提。
Github: https://github.com/awesome-rag/awesome-rag
Github: https://github.com/coree/awesome-rag
2024没有Agents,只有WorkFlows
我又开始胡说八道了,没错2024年的Agents让我很失望,但我用WorkFlows做了很多项目。
我发现一个现象,很多人在混淆Agents和WorkFlows的概念。WorkFlows是由人来事先定义好明确的规则和流程,利用LLM或者工具解决中间某些步骤的问题;而Agents 是为了更加灵活地处理某些任务,由LLM直接动态决策自己的流程和工具使用,无需预定义的规则。所以,现在落地过程当中,大多都是WorkFlows。

图片来自:Building effective agents
推荐大家看看 Anthropic 在年底发的一篇《Building effective agents》文章,里面写的比较清楚,什么是Agents,什么时候该使用Agents,什么时候WorkFlow就够了。
link: https://www.anthropic.com/research/building-effective-agents
在这里强调一下不是批判WorkFlows不好,不管黑猫白猫,捉到老鼠就是好猫。并且由于很多真实落地的场景,都是有明确规则或流程的,完全没有必要非LLM自动编排。
而LLM虽然现在很强,但是你如果真使用LLM进行自动编排的时候,你就会发现不可控和不稳定的问题,也就是执行效率的问。
相同的一个任务,如果采用WorkFlows,32B模型用的稳稳当当;但采用Agents,可能GPT4要执行好多次才能给出最终的答案,而且可能有时候能给出了有时候给不出来。
所以,感觉真正落地,WorkFlows才是稳定的解法,当然RAG就是WorkFlows的一种。
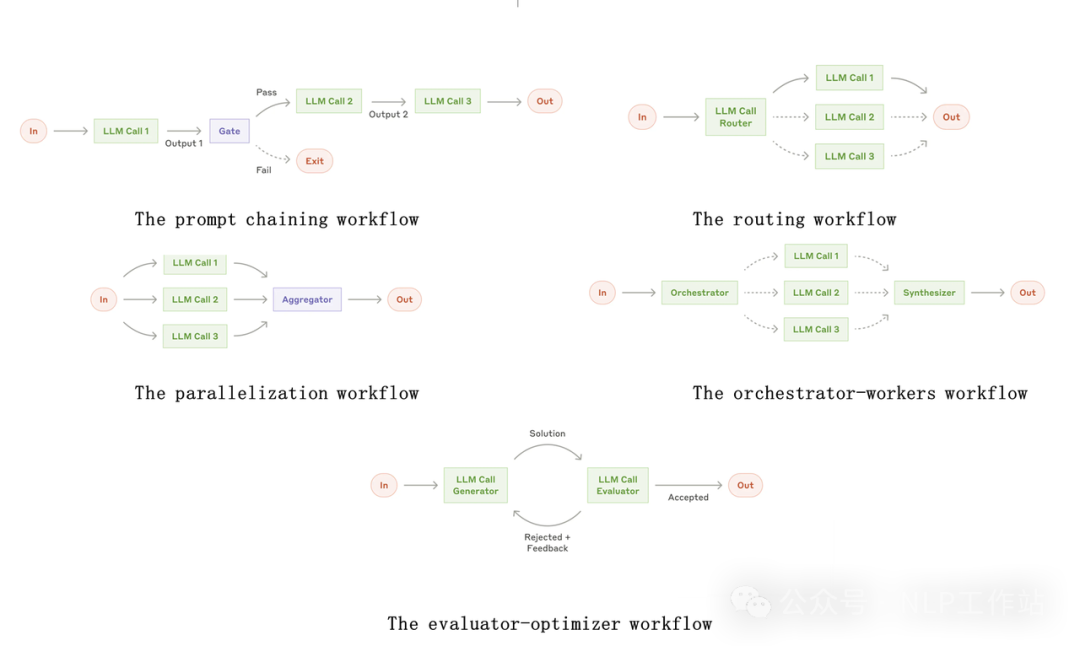
而Agents适合解决一些复杂、难以规划、需要不断探索的场景。
说回今年12月份,Devin正式上线,500$/月,有点小贵,充不起。有幸群友冲了一个,然后观摩了一下,有一些意想不到的效果,但给我的感觉就是很重,想用好其实也不是很容易。并且由于会反复进行一些校验操作,后台吃Token也是扛扛的。
我觉得,Agents是未来,但现在很多LLM还不足以支撑。
我有个朋友,说WorkFlows也不low,没必要非用Agents做掩饰!
多模态模型不如纯LLM智能
从GPT4-o出来之后,LLM在多模态方向也是全面发力,在2024年也是取得了很大的进步。开源的VLM模型在榜单指标上效果也是十分出色。
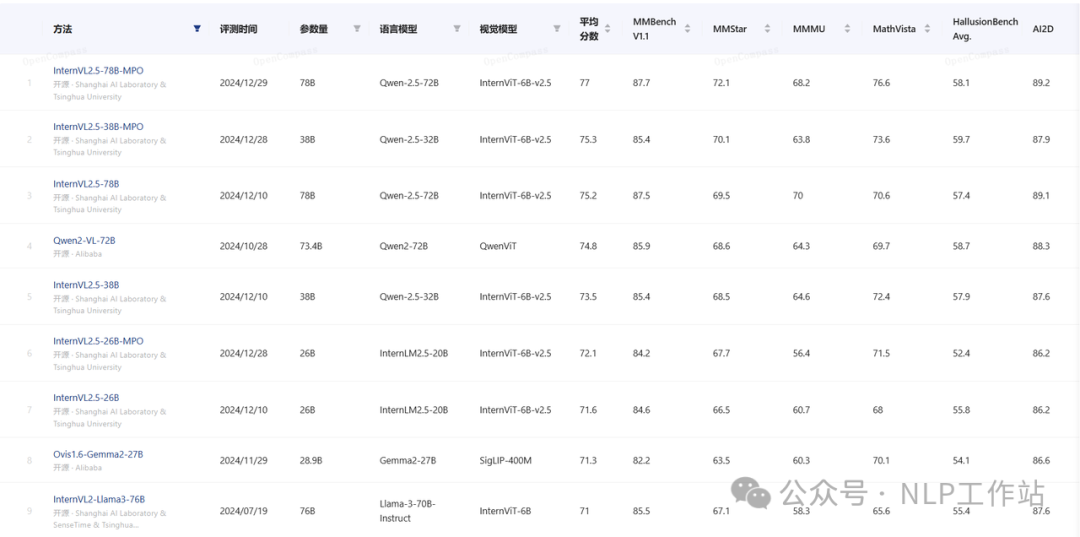
图片来自:OpenCompass评测榜单
但是在很多真实场景上,VLM的效果感觉还差很多,例如我需要将一张流程图,按照步骤解析成文本;从感知上我觉得不复杂,但VLM生成的结果,不是少步骤,就是编号有问题。当前我前几天也写了一篇关于多模态大模型在表格解析任务效果的文章,也是一个VLM落地失败的场景。特别是,我觉得VLM的稳定性不如纯LLM。
link: https://mp.weixin.qq.com/s/i4T3gpFM4FsA8j3ODNds8w
我也发现了一个有趣的问题,针对一道题目,以纯文本的形式问模型,可以回答的很好;但如果将这道题以图片的形式进行输出,那么就会回答错误。
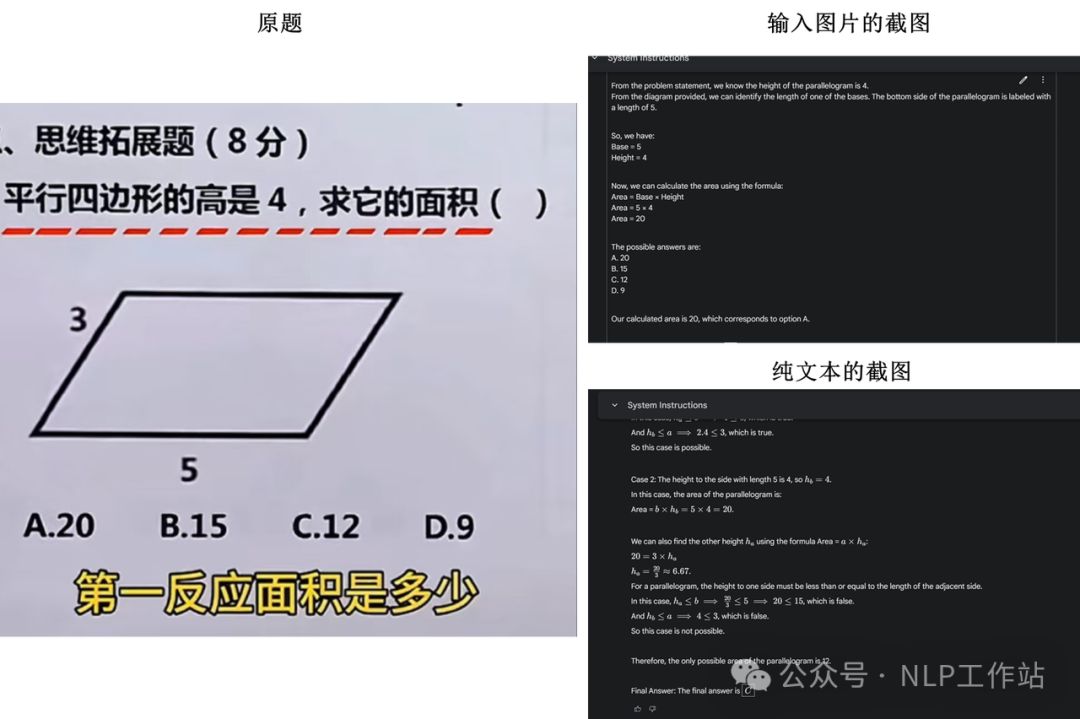
题目来自@南乔,模型为Gemini2.0
上面的截图只是一个示例,我有时候测试总是会发现是这样的问题。不确定是偶然还是必然,没有经过系统的评估。所以在这里抛出这个问题,欢迎大家指证,如果有相关Paper也欢迎甩出来。
总感觉,vision的部分会对llm有影响,而由于多模态训练的可能不充分,导致多模态模型不如纯LLM智能。
因为我没有系统的探究过VLM的相关论文,所以上面的想法,都是在实践过程中,遇到问题后的一些想法。我用着VLM的最舒服的场景是公式识别,有点东西的。
多模态应该就是AGI的未来,但目前看来,还得继续努力~~
O1给LLM又续了一条命
黑OpenAI归黑,但是你必须承认,它到目前为止还在引领着LLM的技术更新。
在O1出来前,我真的觉得强化学习都没了,感觉LLM都要没了,因为你会发现,LLM是蛮强的,但也就那样。LLM给人带来的冲击已经微乎其微,甚至很多人已经开始脱敏了。
今天xxx出了一个新模型,明天xxx又开源了一个新模型,内心os:又是刷榜、又是那一套。
但O1的出现,证明了RL和Inference Time Scaling是另外一个路线,当数据、参数基本达到上限的情况下,你可以通过Post-training和增加推理时间,来进一步提升模型的能力,解决更加复杂的问题。
该说不说,又是引领了一波潮流看,之后国内外其他厂,也陆陆续续推出了类O1的模型。反正Altman应该是有点怨言的,如下图。

当然O1不是万能的,就算后面推出的O3也不是,他在普通任务上的表现,有时不如GPT4-o,但它是一个发展的方向,与之前不同的发展方向。
我有个朋友,跟我说,现在的大模型做那种很难得奥数题,效果刚刚得杠杠的,有时候简单题反而到解不出来。有一种研究生学历的家长,被孩子小学题,难得满头大汗的感觉。
但OpenAI告诉我,强化学习才是未来,于是乎,又默默的打开了尘封已久的OpenRLHF项目代码。
2025年LLM的发展方向
借用Ilya的PPT,表示认同,Agents、Synthetic Data、Inference Time Compute-O1。
在额外新增多模态吧,总感觉现在加上图信息之后LLM回答会降智,总感觉图+文训练的没那么好。

写在最后
不知不觉之间已经写的差不多了,只能说今年感慨很多,走了一些弯路,也有一些成长。
上面的一些经历、吐槽、想法特此分享给大家。
虽然还有很多其他的有趣事情,篇幅有限,咱们2025继续!!
愿2025 LLM越来越好~~~
最后,我有个朋友,最听不得你的模型不如XXX【GPT等】这种话,你也不想想你的参数量,你的数据规模,你投入的精力。能不对算法人说尽量别说这种话吧,有时候心里挺难受的。
(文:机器学习算法与自然语言处理)