

回首2024,我们共同见证了人工智能领域的蓬勃发展,也一同探索了大模型时代的无限可能。感谢每一位读者的一路陪伴,你们的关注与支持,是我们前行的动力。展望2025,AI 的浪潮将更加汹涌澎湃,我们将继续与您携手,洞察 AI 趋势,拥抱智能未来!
中国信通院重磅发布《人工智能发展报告(2024)》,深度解析AI领域最新动态。报告揭示:大模型正引领AI从专用智能迈向通用智能的新纪元,工程化与工具链成为其落地关键,应用赋能呈现“两端开花、中间结果”的格局,安全治理已上升为“必答题”。更具前瞻性的是,报告提出“大小模型协同发展”和“后训练算力倾斜”两大反共识观点,为AI未来发展指明新航向。
来源:中国信息通信研究院,文末附报告原文下载地址。
大模型爆发:AI 技术范式转变
1 从专用到通用:大模型开启 AI 新时代
不再是科幻电影中的遥远幻想,人工智能已实实在在地走入我们的生活,而这背后,大模型技术的突破功不可没。中国信通院的这份重磅报告,为我们揭开了大模型时代的神秘面纱。大模型,以其规模可扩展、多任务适应、能力可塑三大特性,展现出类人智能的“涌现”能力,标志着人工智能正大步迈向通用智能时代。
从全球人工智能产业规模来看(如图1所示),大模型技术的推动作用极为显著。 据 IDC 预测,2024 年全球人工智能产业规模将达到 6233 亿美元,同比增长 21.5%。这其中,大模型的涌现式发展为人工智能产业高速增长提供了核心动力。
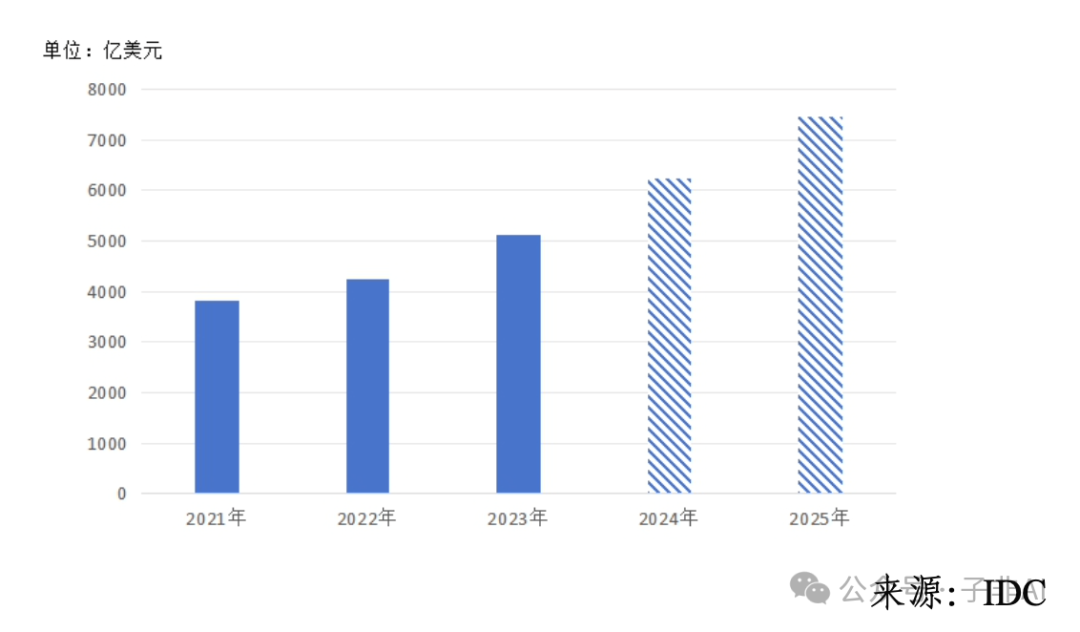
图 1:全球人工智能产业规模(单位:亿美元)
资本市场也对大模型青睐有加。如图2所示,生成式人工智能投融资规模呈现爆发式增长。 2023年,生成式人工智能投融资规模达 252 亿美元,约为 2022 年的 9 倍,占 2023 年所有人工智能相关投资的约四分之一。2024 年上半年,全球金额最大的 10 笔融资事件中有 6 笔为大模型企业融资,金额总计达 135 亿美元。
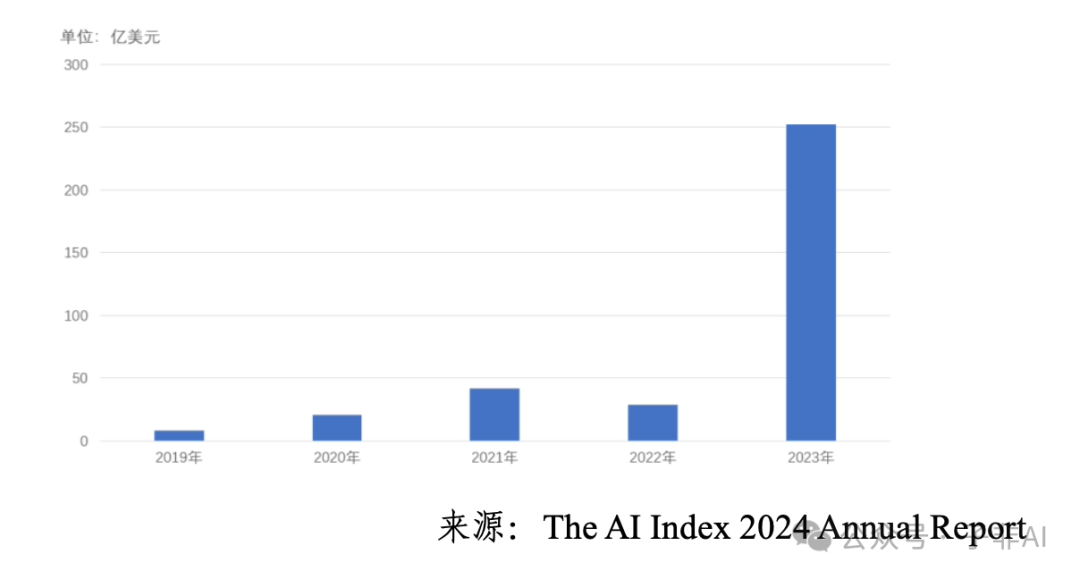
图 2:全球生成式人工智能投融资规模(单位:亿美元)
具体来看,无论是语言理解、图像识别,还是跨模态融合,大模型的能力都在飞速进化。 语言、视觉和多模态三类基础模型全面布局,如图3所示。
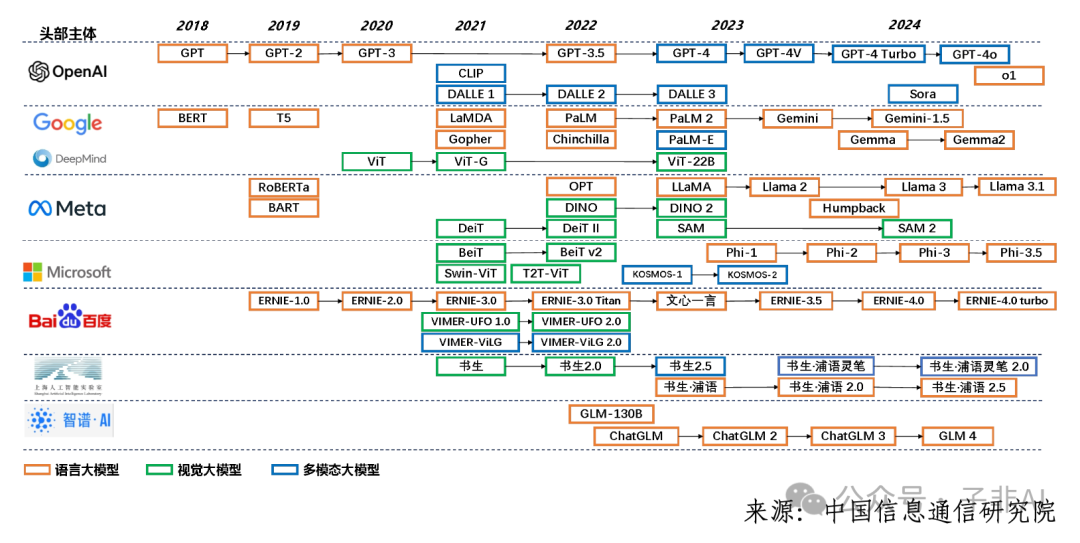
图 3:语言、视觉和多模态三类基础模型布局
在语言大模型方面,其演进迭代情况如图表1所示。当前主流大语言模型均已具备 128k 以上的上下文长度处理能力,轻松驾驭数十万字的文本,对信息的理解深度和广度远超以往。 例如,OpenAI 的 GPT-4 Turbo 和 o1/o1 mini 模型的上下文长度达到 128k;Anthropic 的 Claude 3.5 更是达到了 200k;谷歌的 Gemini-1.5 更是支持高达 1000k(100万)的上下文长度。MoE 架构的广泛采用,如谷歌的 Gemini-1.5 Pro、阿里云 Qwen-1.5 MoE 等,让大模型如虎添翼,能够容纳更多知识,并精准刻画任务,推理计算效率显著提升。
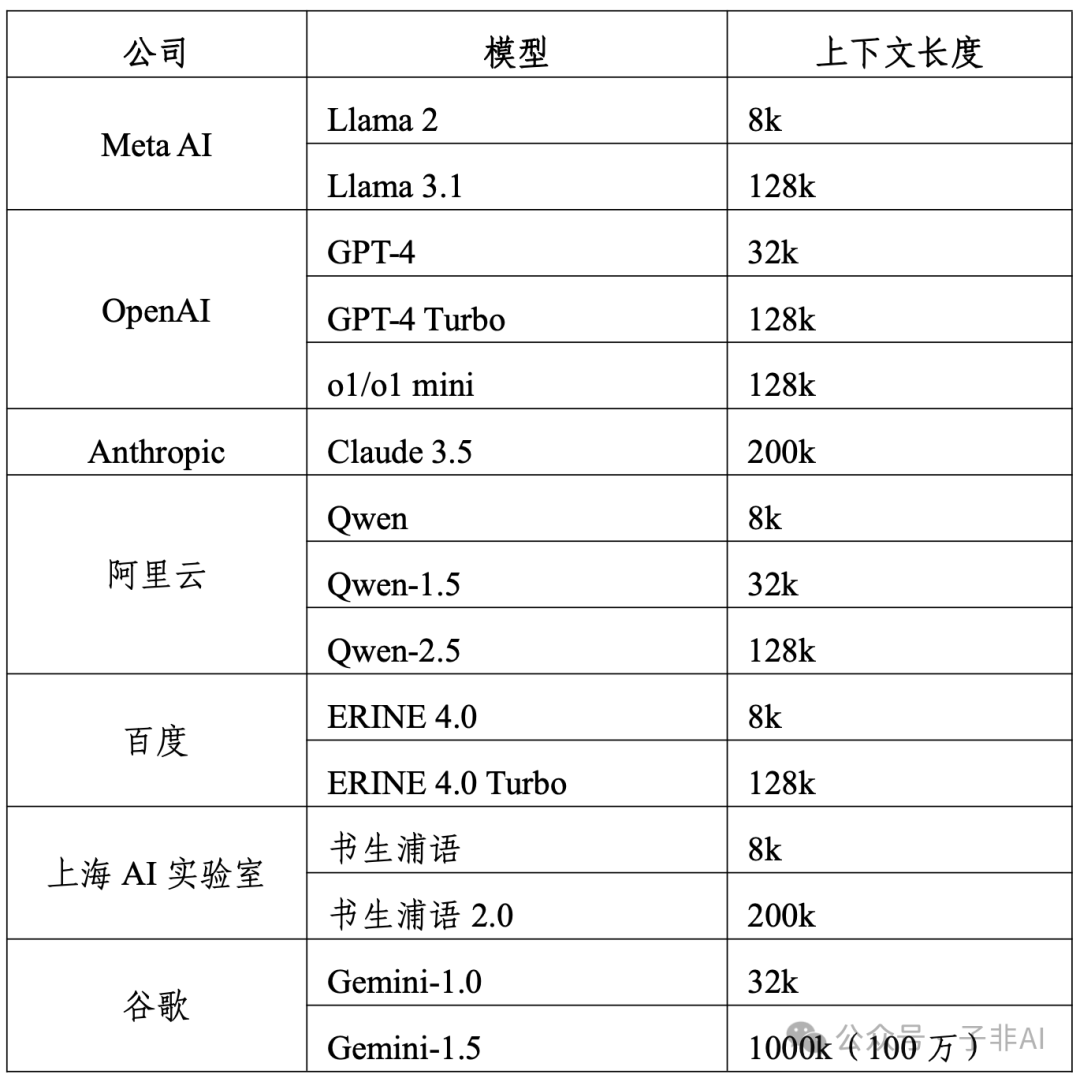
图表 1:语言大模型演进迭代情况
视觉领域,Transformer 架构赋能图像理解,扩散模型则让栩栩如生的图像生成不再是难题。而多模态大模型更是将多种感官信息融会贯通,能够同时处理文本、图像、语音等多种数据,并进行深度的语义理解和交叉模态处理。多模态模型技术路线如图表3所示。 例如,OpenAI 的 GPT-4o 和谷歌的 Gemini 均采用了端到端单体模型的方式学习文本、视觉、语音等不同模态的统一表征,实现跨模态实时交互相应。GPT-4o 能够根据手机拍摄视觉信息与用户对话交互实现多模态统一理解,具备 “听、看、说” 的多模态交互能力,平均响应速度 320ms,达人类对话水平。 这为实现具备深度人机交互和全面智能应用的通用人工智能铺平了道路。

图表 3:多模态模型技术路线表
2 Scaling Law 并非万能:后训练阶段将获更多算力投入
一直以来,Scaling Law 被奉为提升大模型能力的“金科玉律”——只要不断扩大模型规模、增加数据和算力,就能持续提升性能。然而,Scaling Law 并非万能!随着预训练阶段边际效益递减,后训练阶段的价值日益凸显,未来算力资源的天平将逐渐向后训练和推理阶段倾斜。
这一判断可谓振聋发聩。随着模型规模的爆炸式增长,预训练所需的计算资源和数据量呈指数级飙升,成本之高令人咋舌,效率却逐渐走低。相比之下,后训练阶段通过精细化的微调和优化,却能在相对较小的成本下,显著提升模型在特定任务上的性能,可谓“四两拨千斤”。
以 OpenAI 近期发布的 o1 系列大模型为例,其展现出的“慢思考”能力,正是得益于自博弈强化学习技术的应用。这有力地证明,通过改进后训练方法和算法,完全可以在不显著增加模型规模的情况下,大幅提升模型的推理能力和泛化性能。 例如,o1 模型在数学、物理、编程等复杂任务上的性能水平显著增强,甚至具备了自我反思与错误修正能力。 这无疑为大模型的发展开辟了一条新的道路。未来,随着后训练技术的不断成熟,算力资源的分配将更加均衡,更多资源将被投入到后训练和推理阶段,以实现模型性能的最大化和应用成本的最小化。这将推动人工智能技术更加高效、经济地发展,加速其在各个领域的应用和落地。

图表 2:语言大模型调整及解决方案
工程化与工具链:大模型落地的关键
1 工具链全覆盖:智能化转型的基础设施
如果说大模型是 AI 时代的“蒸汽机”,那么工程化与工具链就是将这股强大动力转化为现实生产力的“传动装置”。报告指出,完善的工具链覆盖了大模型开发、训练、部署、应用和运维的全流程,正成为推动企业智能化转型的基础设施。
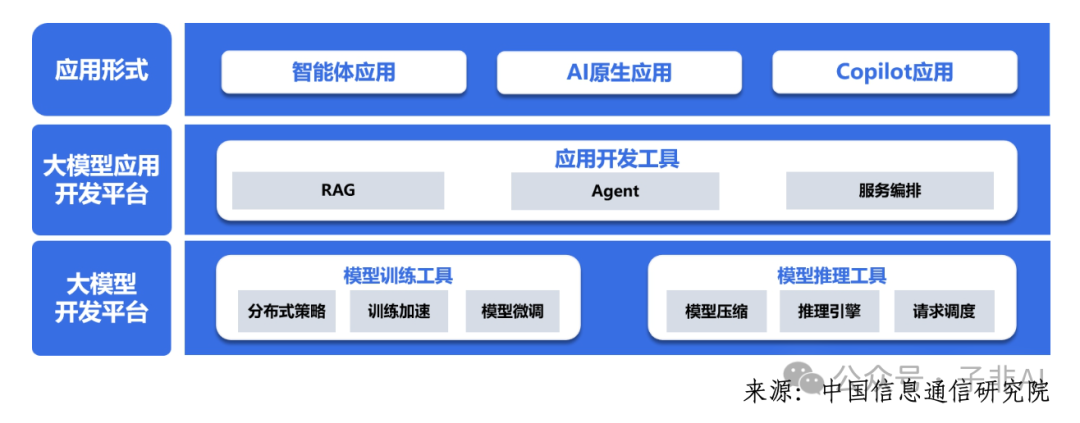
图 4:大模型工具链架构图
2 开发工具链与应用工具链:双链驱动,加速落地
开发工具链和应用工具链,犹如大模型落地的“双引擎”。开发工具链围绕分布式训练持续优化,大幅提升训练效率。 例如,DeepSpeed、Megatron-LM 等框架通过丰富的并行策略和计算加速策略,有力支撑了超大规模模型的预训练。同时,参数高效微调等技术创新,有效降低了计算和存储成本。
应用工具链则聚焦于智能体(Agent)、多模型编排、大小模型协同、知识库集成、检索增强生成(RAG)及多组件融合等关键技术,不断拓展应用广度,降低应用门槛,让大模型真正“飞入寻常百姓家”。
框架方面,PyTorch 凭借其易用性和灵活性,已成为学术界的“宠儿”。而国产框架也奋起直追,如百度飞桨、华为昇思等,正基于国产框架的行业解决方案正在向垂直领域快速渗透。大模型分布式训练需求的爆发,催生了一批大模型加速框架,成为新的竞争高地。
3 高质量数据:模型能力提升的基石
数据是 AI 时代的“石油”,高质量的多模态数据集更是大模型能力跃升的关键。报告强调,面向大模型的新一代数据工程已成为核心技术,涵盖数据采集、预处理、标注、质量评估、数据合成、开放共享等全生命周期。
以数据合成为例,其技术创新正呈现出合成数据模型走向深度进化、多模态合成能力不断突破、强化学习与合成数据逐渐融合发展、隐私保护与合规性技术不断增强等趋势。 例如,英伟达发布的 Nemotron-4 340B,其指令模型的训练仅依赖大约 2 万条人工标注数据,其余 98% 以上训练数据都是通过 Nemotron-4 340B SDG 专用数据管道合成,这充分展示了数据合成技术在解决大模型数据瓶颈方面的巨大潜力。
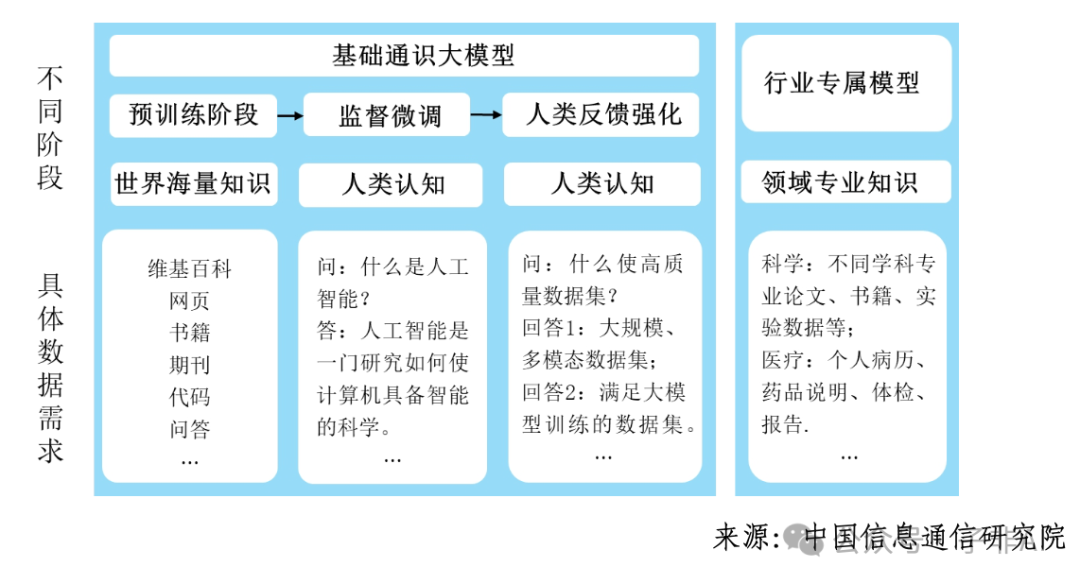
图 5:不同阶段的具体数据需求情况
应用赋能:“两端开花、中间结果”格局初显
1 知识密集型与服务密集型场景:大模型应用的“试验田”
大模型正加速渗透到各行各业,但在产业链不同环节的落地进度却呈现出鲜明的“两端开花、中间结果”的格局。在知识密集型场景,如科学研究、研发设计等领域,大模型凭借其强大的知识处理和推理能力大显身手。 例如,在药物研发领域,某药物分子大模型可将先导药的研发周期从数年缩短至数月,研发成本直降70%,效率提升令人惊叹!在服务密集型场景,如营销、运营等领域,大模型化身智能客服、个性化推荐官,服务效率和用户体验直线上升。
(文:子非AI)