

概览:本文介绍一篇 NeurIPS 2024 的工作,提出了一种新的视频时序定位扩展任务。传统的视频时序定位任务(Temporal Sentence Grounding,TSG)假设给定的视频中必然包含与指定查询文本相关的片段,但这一假设在实际应用中并不总是成立。
针对这一问题,作者提出了 TSG 的扩展任务——相关反馈的视频时序定位任务(Temporal Sentence Grounding with relevance feedback,TSG-RF)。TSG-RF 任务允许给定的视频中没有与查询文本相关的片段,首先要求预测视频中是否存在与指定查询文本相关的片段,如果存在则需从视频中精确定位与查询文本匹配的片段的起止位置,反之则不进行定位。
针对 TSG-RF 任务,作者设计了关系感知的视频时序定位框架(Relation-aware Temporal Sentence Grounding,RaTSG)。该框架通过将 TSG-RF 任务转化为前景与背景检测问题,利用多粒度相关性判别器捕捉文本与视频的语义关联,并通过关系感知定位模块动态调整是否执行定位操作。
此外,作者重构了 TSG 任务常用的 Charades-STA 和 ActivityNet Captions 数据集,使得两个数据集适用于 TSG-RF 任务的评价。大量实验结果表明,本文提出的 RaTSG 方法在 TSG-RF 新任务上有效性。目前 TSG-RF 任务的性能还不是很高,未来仍有很大的提升空间。

收录会议:
论文链接:
代码链接:

引言
视频时序定位任务(TSG)在智能机器人服务、视频点播、元宇宙等多媒体应用中有着广泛的应用前景。近年来,TSG 任务取得了显著进展,目标是根据自然语言描述,从长视频中精确检索出语义相关的片段。
然而,现有 TSG 方法假设每段视频中始终存在与查询文本相关的内容。这种设定在实际场景中并不现实,视频中可能完全不存在相关内容,导致传统方法生成错误的定位结果。
为应对这一挑战,本文提出了一种全新的任务——相关反馈的视频时序定位任务(TSG-RF),允许视频中可能不存在与查询文本相关的片段。当视频中存在与查询文本语义相关的内容时候,需要进行精确定位,否则需要明确告知用户当前查询无相关结果。与传统 TSG 相比,该任务更加灵活,适用于更复杂的实际场景。

针对 TSG-RF 新任务,作者提出了关系感知的视频时序定位框架(RaTSG),将 TSG-RF 任务定义为前景与背景的检测问题,不仅关注相关片段的定位,还支持查询文本和视频之间的部分相关性判别。
RaTSG 引入了一种多粒度相关性判别器,将细粒度的帧级相关性与粗粒度的全局级相关性相结合,系统性地捕捉查询文本与视频之间的部分语义相关性。此外,设计了关系感知的片段定位模块,能够基于前期相关性判别的反馈,动态选择是否执行片段定位操作,从而解决了传统方法在无相关内容场景下错误预测的局限性。
论文贡献总结如下:
1. 提出了一个更贴合实际应用场景的新型视频时序定位任务的扩展任务,即相关反馈的视频时序定位任务(TSG-RF)。
2. 针对 TSG-RF 任务,提出了一种全新的关系感知的视频时序定位框架(RaTSG),主要包括多粒度相关性判别器和关系感知的片段定位。多粒度相关性判别器基于查询文本与视频帧和视频整体之间的细粒度和粗粒度相关性进行相关性反馈预测,关系感知片段定位模块根据相关性反馈自适应地预测片段的开始和结束边界。
3. 本文重新构建了两个常用的 TSG 数据集,并建立了符合 TSG-RF 任务设置的评估指标。大量实验表明,所提出的框架在这些重构的数据集上表现出了卓越的效果。

方法
为了解决 TSG-RF 任务,本文提出了一个名为关系感知视频时序定位框架(RaTSG)。该框架主要依赖两个模块:多粒度相关性判别器和关系感知片段定位模块。
其中,多粒度相关性判别器通过在帧级和视频级别上分析文本和视频之间的语义关系,生成是否存在查询相关内容的反馈信息。关系感知片段定位模块依据这些反馈信息动态选择是否进行片段定位,并预测起止边界。
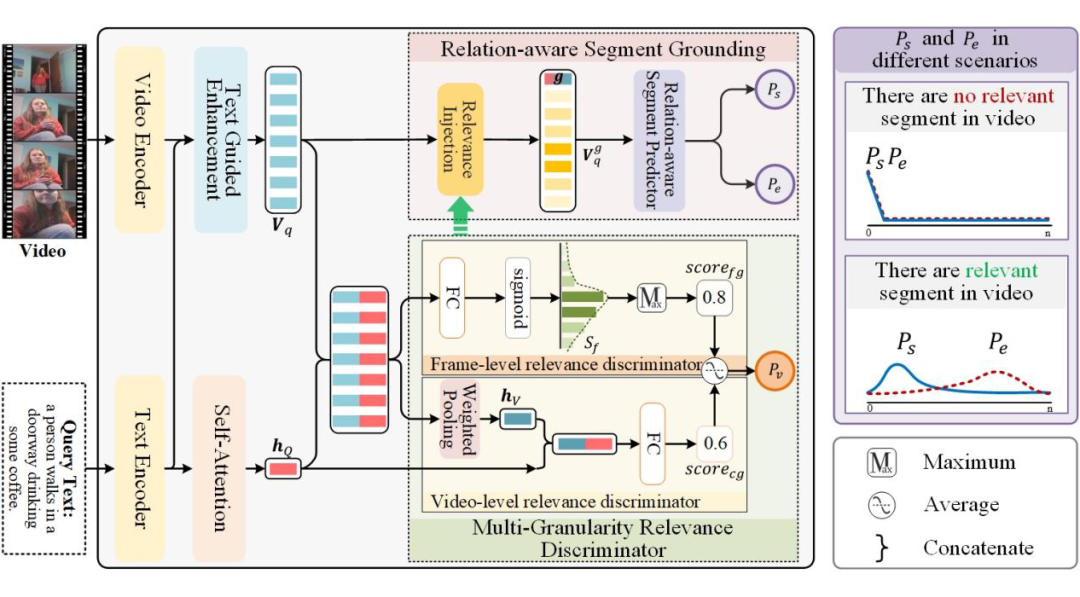
▲ 图二 具体方法示意图
在生成片段定位结果之前,需要首先评估视频与查询文本之间的语义相关性。为此,作者设计了一个多粒度相关性判别器,通过帧级和视频级的相关性分析来判断视频是否包含与查询相关的片段。
2.1.1 帧级相关性判别
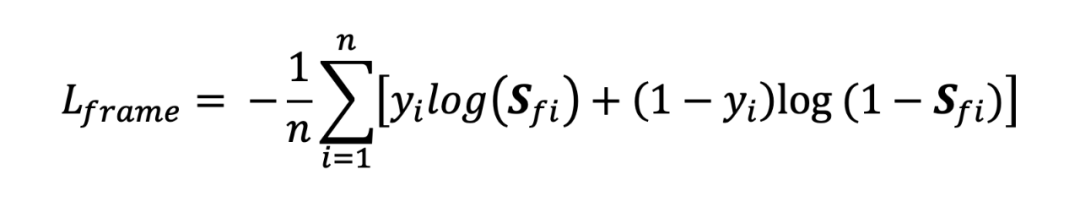
在帧级相关性捕获的基础上,视频级相关性判别模块通过生成全局视频表示并结合查询文本,进一步评估视频与查询在语义上的整体相关性。为此,引入了关系信号向量 ,该向量融合了视频和文本之间语义相关性知识。
首先,根据帧级相关性得分 对每帧的文本引导增强特征 进行加权求和,生成全局视频表示 。随后,查询文本的句子级特征 与全局视频表示 结合,通过一层全连接网络生成关系信号向量 。基于关系信号向量 ,通过 sigmoid 函数计算视频级粗粒度相关性分数 ,即:
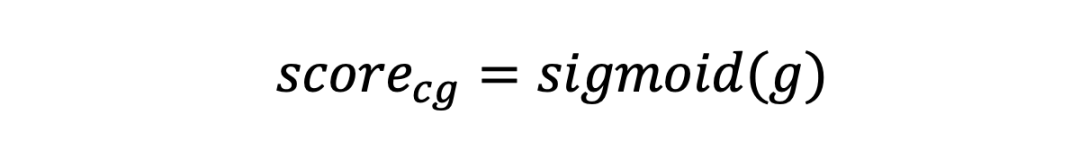
该粗粒度分数 全面描述了查询文本与整个视频的语义相关性。
为了训练视频级相关性判别器,作者定义了二元交叉熵损失 来优化视频和文本之间的粗粒度相关性分数判别:
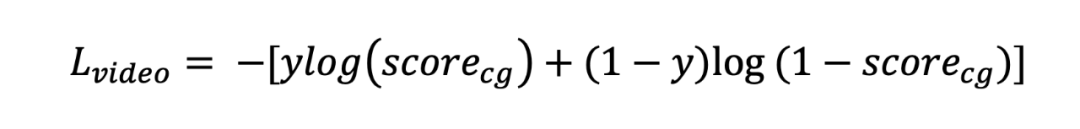
其中, 是视频的相关性标签(1 表示视频中存在与查询相关的内容,0 表示不存在相关内容)。
在获取查询与视频的相关性分数后,为了准确预测目标片段的起止边界,本文设计了一个关系感知片段定位模块。该模块利用从视频级相关性判别器中获得的关系信号向量 ,动态调整定位策略,以适应查询相关内容可能缺失的情况。
2.2.1 特殊标记的引入
2.2.1 边界预测方法
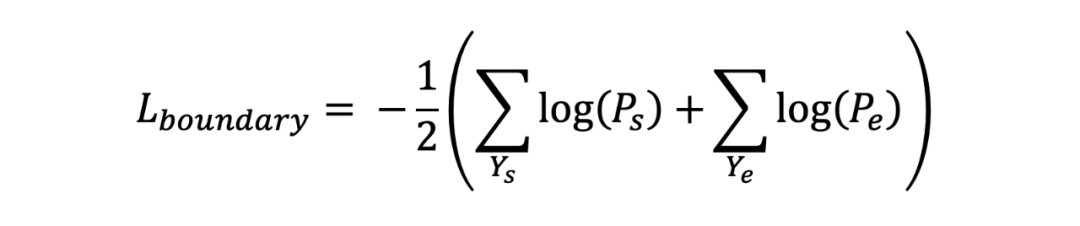
2.3 训练与推理
2.3.1 总损失函数
总损失函数的公式如下:
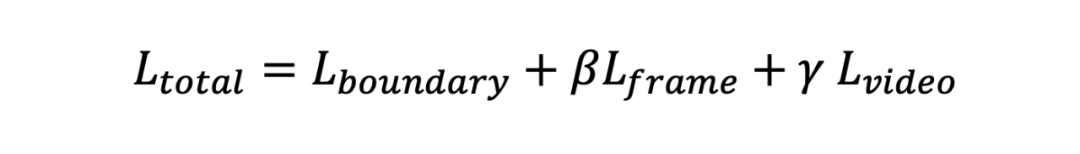
其中, 和 是超参数,用于平衡不同损失项的重要性。
在推理阶段,RaTSG 首先通过计算多粒度相关性得分 来判断查询相关内容是否存在于视频中。具体来说,模型将 与设定的阈值 进行比较:

对于判定为“存在相关内容”的样本,RaTSG 进一步通过片段定位模块预测目标片段的起止边界()。边界预测基于起始边界和结束边界的概率分布 和 。
具体地,计算开始边界概率分布 和结束边界概率分布 的联合概率分布矩阵,概率联合分布矩阵中最大值的二维索引即为预测片段的开始边界索引()和结束边界索引(),即:


实验
3.1 数据集重构
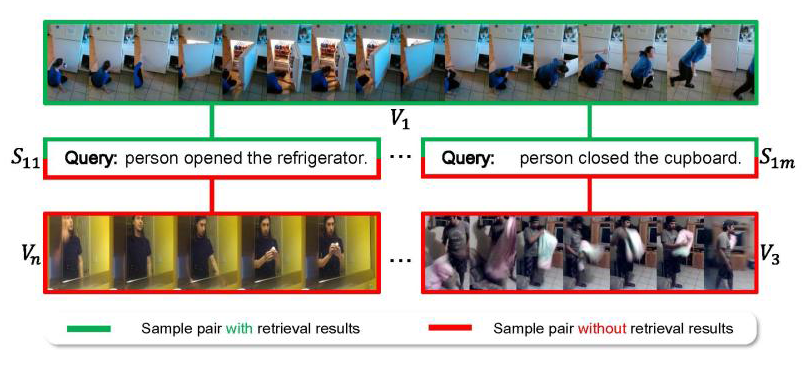
由于目前没有为 TSG-RF 任务创建的数据集,为了构建 TSG-RF 任务的测试环境,本文重构了两个在 TSG 任务领域使用广泛的数据集 Charades-STA 和 ActivityNet Captions 的验证集和测试集,得到 Charades-RF、ActivityNet-RF 重构数据集。
在原始数据集中,一个视频会对应多个查询文本,如图三所示,视频 对应 个有检索结果的查询文本 。对于每个文本,都要通过随机匹配其他视频的方式构造与查询文本不相关的片段样本。
由于我们提出的 TSG-RF 任务要求模型提供相关反馈,即判断样本是否有可定位的结果,我们使用准确率(Acc) 来衡量相关性反馈的能力。
为了评估模型的定位能力,作者参考 TSG 任务重常用的 R{n}@{m} 和 mIoU 作为评估指标。其中,R{n}@{m} 表示在排名前 n 的候选片段中,至少有一个片段与真实片段的 IoU(交并比)大于 m 的查询文本的比例。mIoU 表示所有测试样本中 IoU 的平均值。
值得注意的是,由于样本中包含无定位结果的情况,作者重新定义了 IoU 的计算方式,具体包括以下四种情形:
1. 当模型预测样本没有定位结果,但真实情况中存在定位结果时,IoU 设为 0。
2. 当模型预测和真实情况都表明样本没有定位结果时,IoU 设为 1。
3. 当模型预测样本有定位结果,但真实情况中没有定位结果时,IoU 设为 0。
4. 当模型预测和真实情况都表明样本有定位结果时,IoU 的值是模型预测片段和真实片段之间的交并比(IoU)。
3.3 和Baseline模型进行比较
由于当前尚无专门针对相关反馈的视频时序定位(TSG-RF)任务设计的模型,本文对现有的视频时序定位(TSG)模型进行了适配。具体而言,作者选取了六个近期公开源码且具有代表性的 TSG 模型,包括 VSLNet、SeqPAN、EAMAT、ADPN、UniVTG 和 QD-DETR。
为使这些模型能够支持 TSG-RF 任务,本文在其基础上引入了一个独立训练的相关性判别器,用于判断查询文本与视频内容的相关性,从而筛选出与查询相关的视频样本。
随后,这些样本被输入到原有的 TSG 模型中进行目标片段的时序定位预测。扩展后的模型分别命名为 VSLNet++、SeqPAN++、EAMAT++、ADPN++、UniVTG++ 和 QD-DETR++,能够提供针对 TSG-RF 任务的相关性反馈功能。
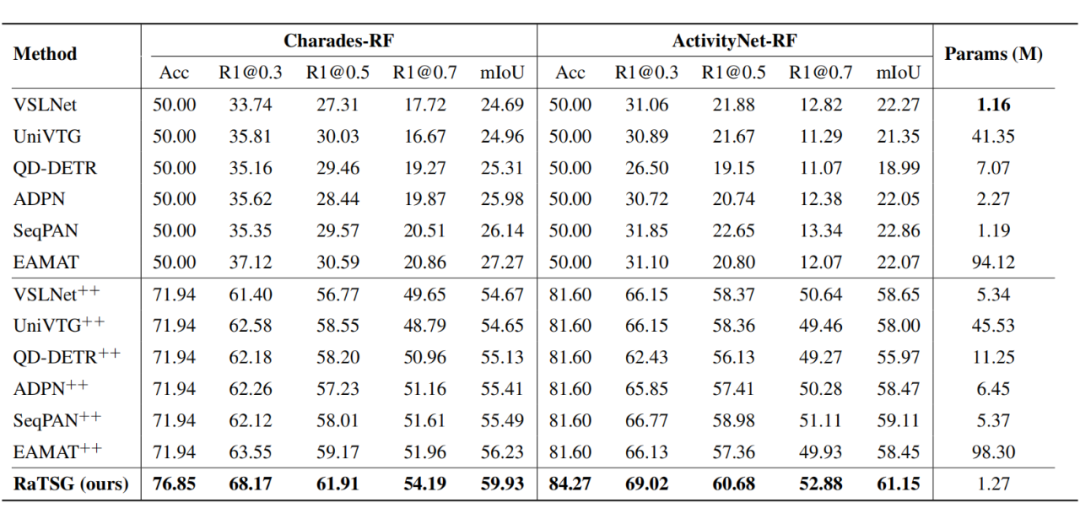
在 Charades-RF 和 ActivityNet-RF 数据集上的性能对比总结显示,传统的视频时序定位(TSG)模型缺乏区分样本相关性的能力。这些模型默认所有样本都存在定位结果,导致在处理无相关内容样本时性能较差,进一步引发预测不匹配问题,从而降低了 TSG-RF 任务中的召回率和 mIoU 指标。
此外,由于测试集包含等比例(1:1)的相关和无相关样本,这些模型的相关性预测准确率仅为 50%。相比之下,增强版的基线模型(VSLNet++、SeqPAN++、EAMAT++、ADPN++、UniVTG++ 和 QD-DETR++)通过引入相关性判别器,在性能上相较于未增强版本有显著提升。
然而,这些增强版模型需要对相关性判别器和视频定位模块进行独立训练,导致计算资源的冗余使用以及模型规模的增加。与之相比,本文提出的 RaTSG 模型通过将相关性判别和时序片段定位模块无缝整合,提供了一种更轻量化且全面的解决方案。
在性能方面,RaTSG 在召回率、mIoU 以及相关性反馈准确率等指标上均实现了最优表现,同时大幅减少了模型的复杂性和计算资源的使用。
3.4 消融实验
3.4.1 多粒度相关性判别器的有效性
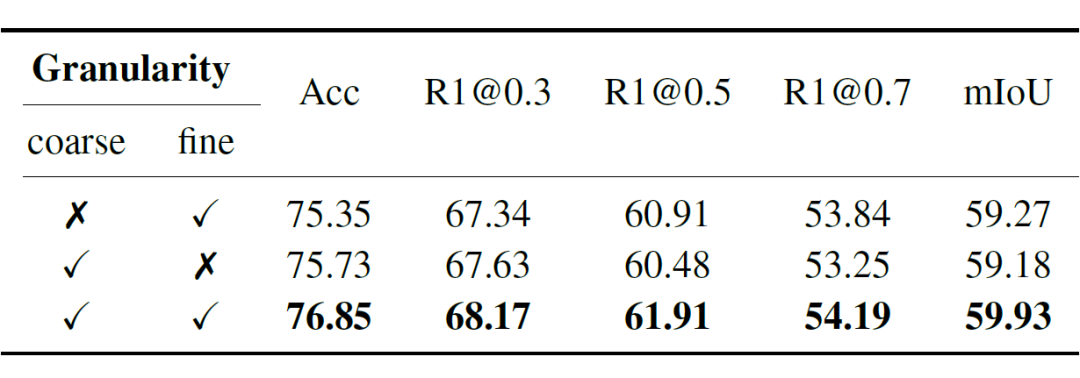
为了分析多粒度相关性判别器的作用,实验分别测试了仅使用帧级相关性、仅使用视频级相关性以及结合两者的性能。
结果显示,单独使用帧级或视频级相关性判别时,模型的相关性反馈准确率有所下降;而结合帧级和视频级的多粒度判别器时,性能得到显著提升。这表明,多粒度判别器能够有效捕捉局部细节与全局语义,提升模型对相关性判断的准确性。
3.4.2 关系感知片段定位模块的有效性
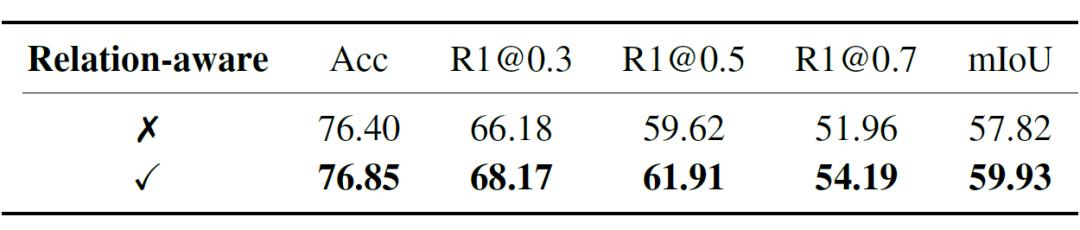
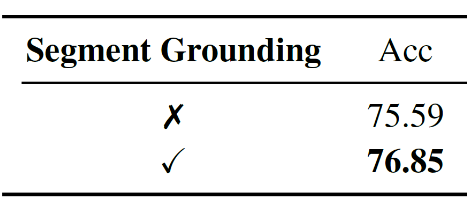
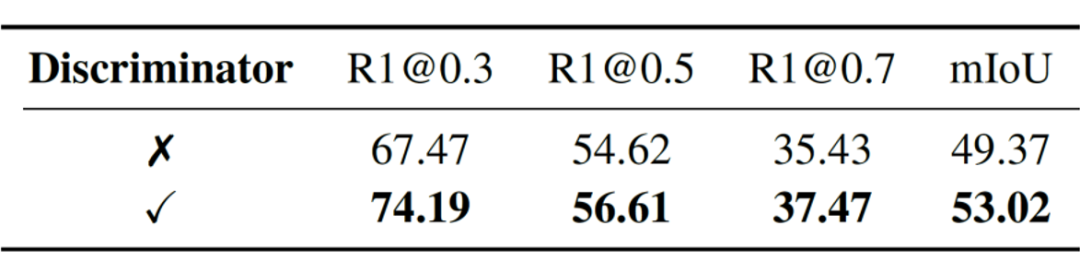
RaTSG 是一种同时执行相关性判别与时序片段定位任务的统一模型,采用多任务学习的方式进行训练。为探究这两个任务之间的相互关系,分别去除了模型中的时序片段定位模块和相关性判别器进行对比实验。
结果显示,去除片段定位模块会降低相关性判别的性能,说明定位结果能够为相关性判别提供辅助信息;而去除相关性判别器则会导致片段定位性能下降,表明相关性判别能够为片段定位任务提供有效的先验约束。实验结果证明了这两个任务在 RaTSG 模型中能够相互增强,从而提升整体性能,进一步验证了本文提出的双分支统一框架设计的有效性。
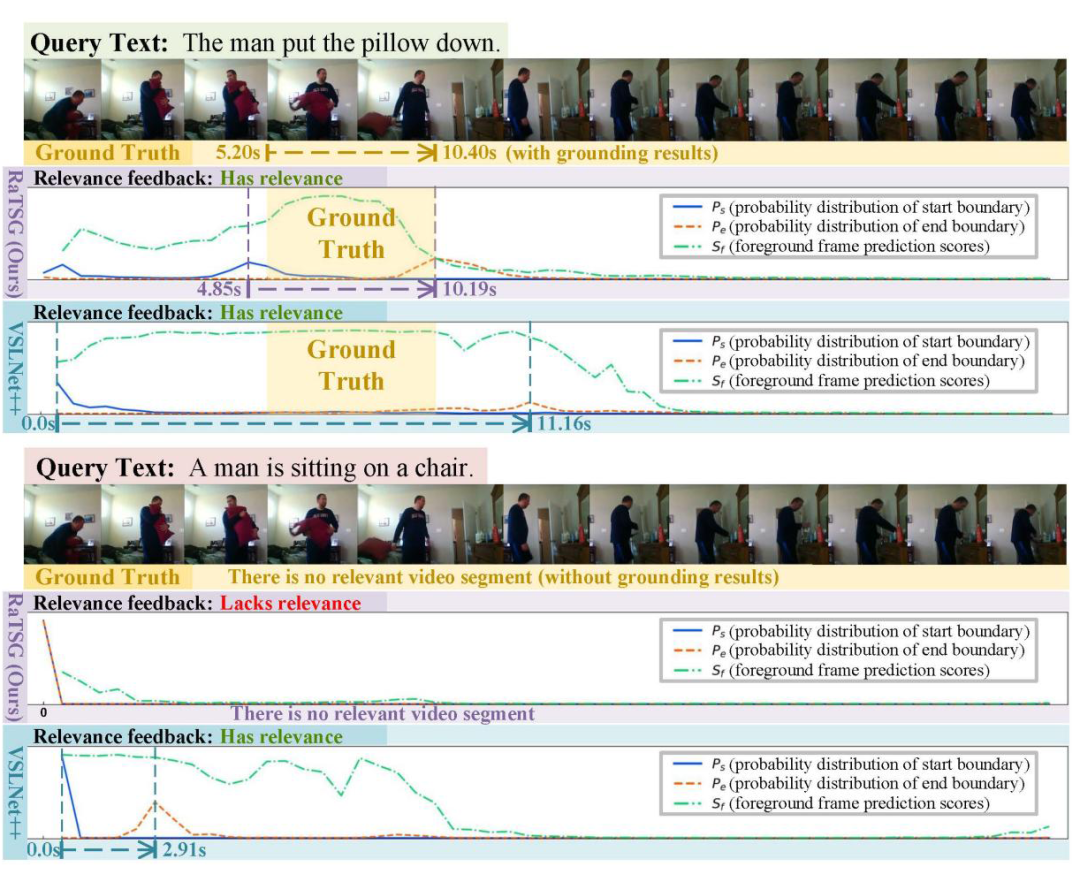
图四展示了 RaTSG 和基线模型 VSLNet++ 在两个示例上的定位结果,可用来分析两者在具有相关片段和无相关片段样本上的表现差异。对于第一个具有相关片段的示例,RaTSG 在定位查询文本对应的目标片段时表现得更准确。
具体而言,RaTSG 的前景帧预测分数更加合理,这是因为模型在训练过程中包含了无相关内容样本,使其能够学习背景帧与文本之间的特征相似性,从而提升了区分前景帧和背景帧的能力。
对于第二个无相关内容的示例,RaTSG 能够正确地预测出较低的前景帧分数,并提供了准确的相关性反馈。RaTSG 的关系感知片段定位模块高概率地分配特殊标记索引 0,表明不存在相关片段。
而相比之下,VSLNet++ 错误地预测了较高的前景帧分数,并给出了错误的相关性反馈,最终导致了错误的片段定位结果。

总结
(文:PaperWeekly)