跳至内容
如果说 OpenAI 是人工智能界的「神秘主义者」,那微软就是圈内著名的「爆料者」。2025 年伊始,微软又一次在论文中「不经意」地泄露了多个头部 AI 模型的关键参数数据。这不禁让人联想到 2023 年 10 月,微软曾在论文中透露 GPT-3.5-Turbo 为 20B 参数的往事。
医疗 AI 评测下的意外发现
这一切源于微软最新发布的一篇医疗 AI 评测论文。
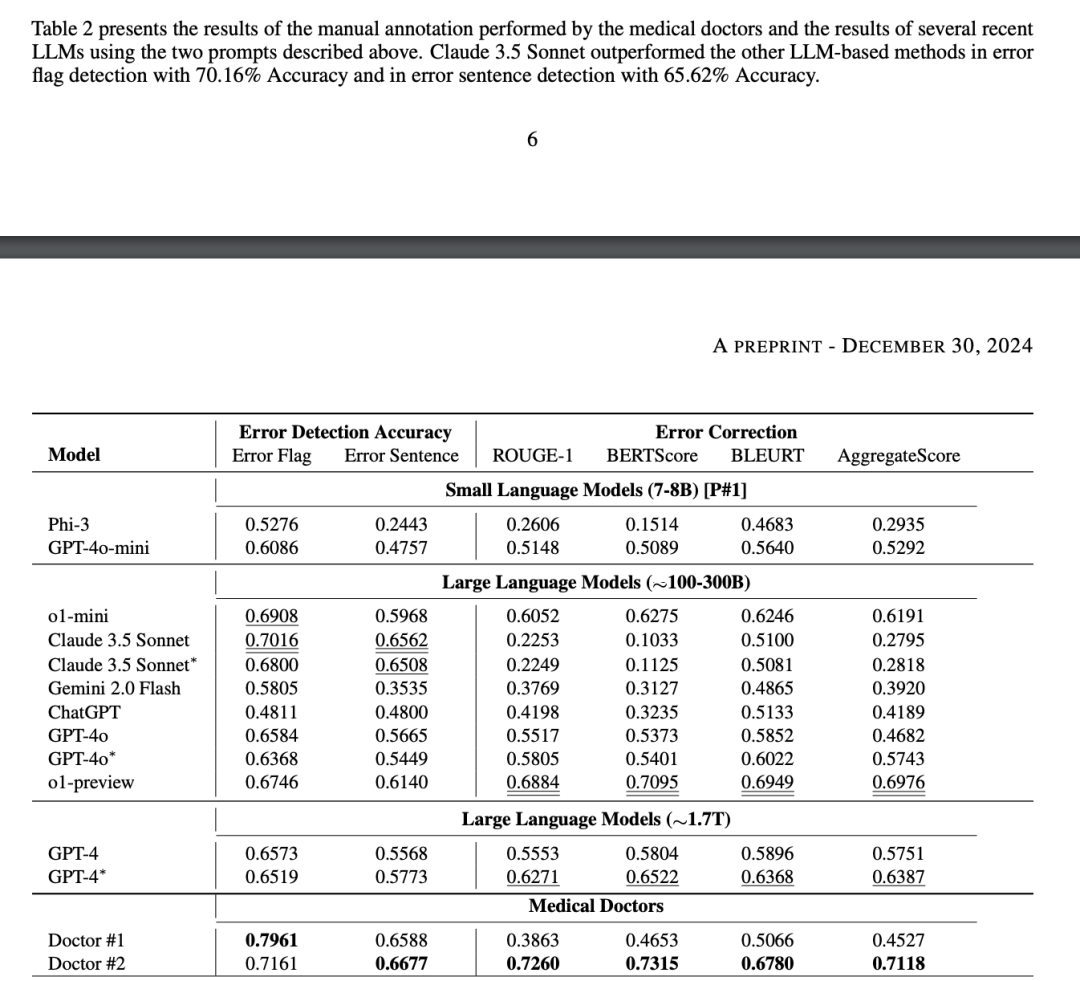
研究团队开发了名为 MEDEC 的评测基准,用于检验 AI 模型在识别和纠正医疗文档错误方面的能力。在介绍参与评测的模型时,论文列出了一系列令人瞠目的数据:o1-preview 约 300B 参数,GPT-4o 约 200B,GPT-4o-mini 仅有 8B 参数。
这与英伟达此前公布的 GPT-4 使用 1.8T MoE 架构的说法形成鲜明对比。更有趣的是,论文还披露了 Claude 3.5 Sonnet 约 175B 的参数规模,以及其他多个模型的具体数据。
数据背后的玄机
虽然论文声明这些数字「仅为估计」,但业内人士普遍认为微软的数据并非空穴来风。一种观点认为,由于大多数模型都在英伟达 GPU 上运行,通过 token 生成速度能够较准确地推算参数规模。这也解释了为何论文唯独对运行在 TPU 上的谷歌 Gemini 模型三缄其口。
参数规模的争议背后,折射出 AI 领域的几个关键趋势。首先是大型模型逐渐转向 MoE(混合专家)架构,这意味着模型的实际激活参数可能远低于总参数量。其次,Claude 3.5 Sonnet 以相对更小的参数量获得了最高的评测分数,印证了「大未必强」的观点。
行业格局的重构
这次参数数据的曝光,让我们得以一窥各大 AI 公司的技术路线。OpenAI 似乎在探索不同规模的模型系列,从 8B 到 300B 不等。Anthropic 则专注于提升模型效率,用较少的参数实现更好的性能。在医疗评测中,Claude 3.5 Sonnet 以 70.16 的得分领先其他模型,紧随其后的是 o1-mini。
微软自家的 Phi-3-7B 虽然参数量最小,但在某些特定任务上表现出色,这印证了模型架构和训练方法可能比简单的参数堆叠更为重要。
写在最后
在快速发展的 AI 领域,参数规模之争终将让位于实际应用效果。真正重要的是如何用最优的架构和方法,构建出能力匹配、成本适中的 AI 模型。无论是微软的「无意泄露」,还是业界的猜测讨论,都推动着整个行业向着更开放、更理性的方向发展。
毕竟,在技术创新的道路上,真相常常比猜测更精彩。而这场参数之争的背后,或许正是 AI 技术突破的新篇章。
如果你想阅读论文,可以查看:https://arxiv.org/pdf/2412.19260?
(文:毫河风报)