
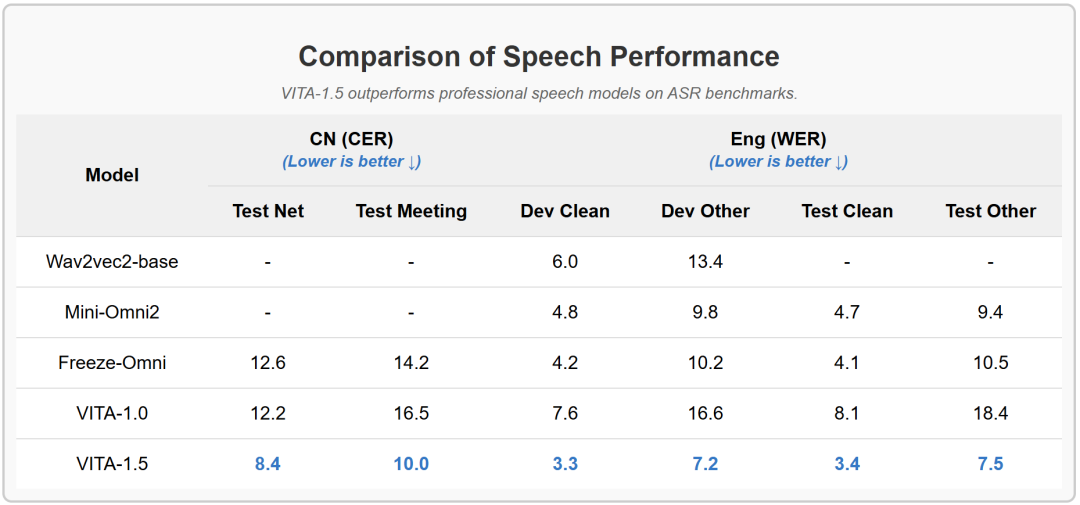
接近GPT-4o级别的开源实时视觉语音交互模型:VITA-1.5,能看懂图片视频,理解你的问题,用语音回答你。端到端语音交互时延从约4秒缩短到了1.5秒。语音识别WER(词错误率)从18.4%降到了7.5%。

参考文献:
[1] github:https://github.com/VITA-MLLM/VITA
(文:NLP工程化)
接近GPT-4o级别的开源实时视觉语音交互模型:VITA-1.5,能看懂图片视频,理解你的问题,用语音回答你。端到端语音交互时延从约4秒缩短到了1.5秒。语音识别WER(词错误率)从18.4%降到了7.5%。
参考文献:
[1] github:https://github.com/VITA-MLLM/VITA
(文:NLP工程化)