
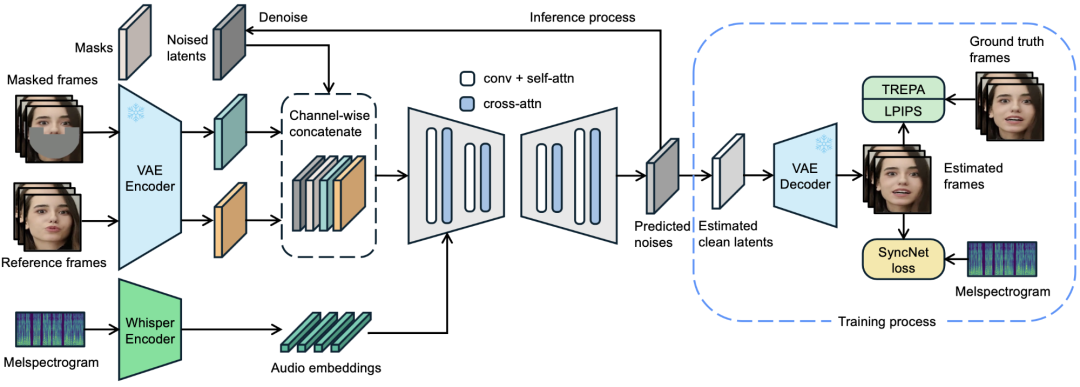
提出了LatentSync,这是一个基于音频条件潜在扩散模型的端到端口型同步框架,没有任何中间运动表示,这与以前基于像素空间扩散或两阶段生成的基于扩散的口型同步方法不同。我们的框架可以利用稳定扩散的强大功能来直接模拟复杂的视听相关性。
此外,我们发现基于扩散的口型同步方法表现出较差的时间一致性,因为不同帧之间的扩散过程不一致。我们提出了时间表示对齐 (TREPA)来增强时间一致性,同时保持口型同步准确性。TREPA 使用由大规模自监督视频模型提取的时间表示来将生成的帧与真实帧对齐。
参考文献:
[1] https://github.com/bytedance/LatentSync
(文:NLP工程化)