
本文主要介绍了英伟达 Cosmos 模型的细节,包括模型版本、模型架构、工程实现、推理速度(单GPU)、数据集:Cosmos使用专有和公开的视频数据集进行训练。具体细节,详见参考文献[1][2]。
一.模型版本
Cosmos-1.0-Diffusion-7B-Text2World:根据文字描述,预测 121 帧视频的输出结果。
Cosmos-1.0-Diffusion-14B-Text2World:根据文字描述,预测 121 帧视频的输出结果。
Cosmos-1.0-Diffusion-7B-Video2World:给定文字描述和第一帧图像,预测未来 120 帧图像。
Cosmos-1.0-Diffusion-14B-Video2World:给定文字描述和第一帧图像,预测未来 120 帧图像。
二.模型架构

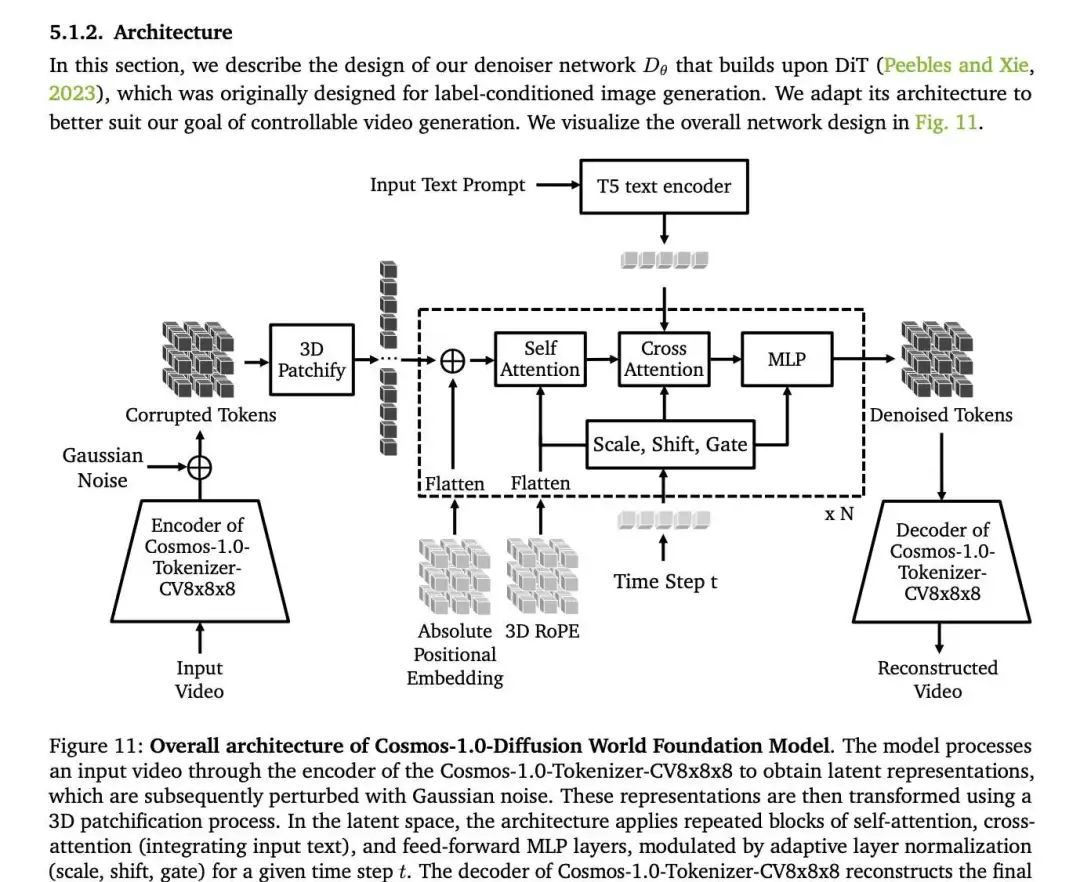
三.工程实现
目前包含四种主要类型的模型:NeMo Curator、Cosmos Tokenizer、Cosmos Guardrail 和 Cosmos World Foundation Model(后简称 Cosmos WFM)。
-
NeMo Curator 是一个视频编辑管道,它获取原始视频帧,将其分割成有意义的片段,并用语义标签、对象标签和场景描述对其进行注释。 -
然后将注释过的图像输入 Cosmos Tokenizer,生成 token 序列。这一步骤降低了数据维度,使 Cosmos WFM 能够有效处理大型或复杂的训练输入。 -
然后, Cosmos WFM 将使用经过编辑/注释的视频片段,并从真实世界的数据中学习底层物理和视觉动态。 -
当被查询时,Cosmos WFM 会输出新的 token 序列,然后将其解码为高分辨率和物理逼真的合成视频。 -
Cosmos WFM 在大规模视频数据集上进行预训练,让它们接触广泛的视觉体验,使它们成为通才。 -
为了构建专门的 WFM,开发人员需要使用从特定使用案例中收集的额外数据对 Cosmos WFM 进行微调。这些额外的数据将有助于调整 Cosmos WFM,使其适应预定的使用案例,确保其在真实世界的条件下发挥最佳性能。
四.推理速度(单GPU)
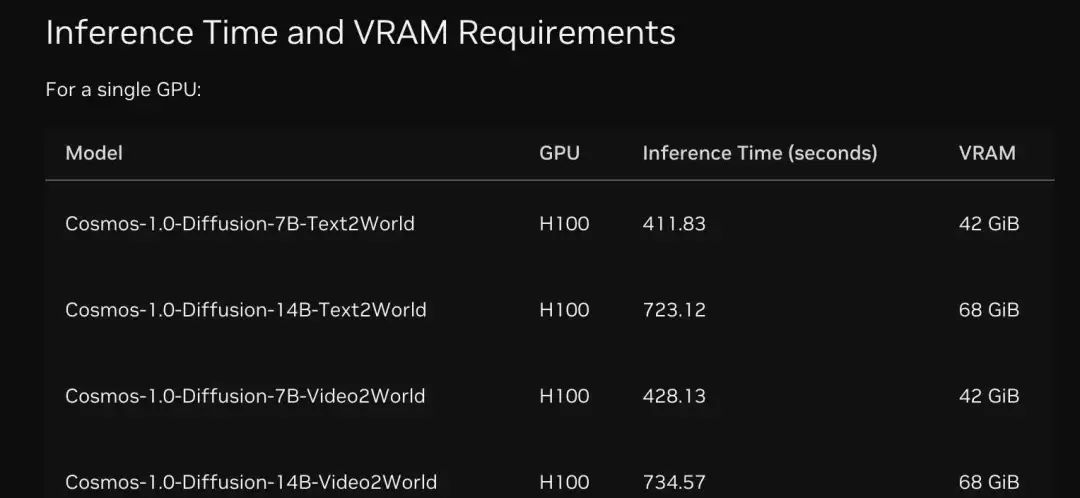
五.数据集:Cosmos使用专有和公开的视频数据集进行训练
数据包括:驾驶(11%)、手部运动和物体操作(16%)、人体运动和活动(10%)、空间意识和导航(16%)、第一人称视角(8%)、自然动态(20%)、摄像机动态移动(8%)、合成渲染(4%)、其他 (7%)
参考文献:
[1] 官网:https://build.nvidia.com/nvidia/cosmos-1_0-diffusion-7b
[2] 论文:https://d1qx31qr3h6wln.cloudfront.net/publications/NVIDIA%20Cosmos_2.pdf
(文:NLP工程化)