
字节跳动
字节跳动开源多模态AI Agent—UI-TARS-1.5
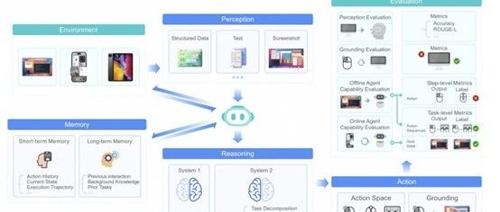
字节跳动开源的多模态AI Agent UI-TARS 1.5在计算机、浏览器和手机使用测试中表现优异,并在GUI定位方面显著提升。它在游戏领域也表现出强大能力,展现出出色的推理、决策和适应能力。
字节版“Manus”来了
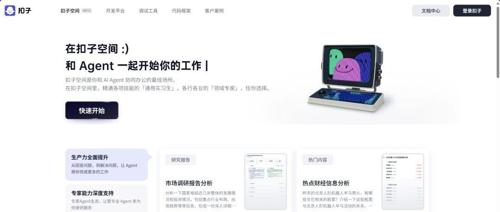
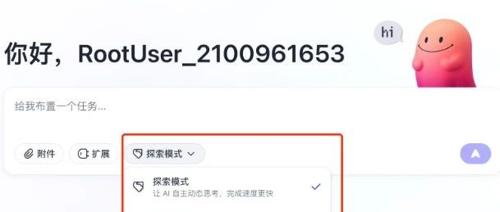
字节跳动新推出Agent产品“扣子空间”,支持无线裂变邀请码获取。用户可通过探索和规划模式生成网页、网页版吉他、天气预报网站等任务,并添加MCP扩展插件。目前处于内测阶段,存在一些小问题,但任务拆解与多模态输出超越多数竞品。
Agentic 是个谎言,本质还是经典RL

本文深入探讨了Agentic概念,指出其实质仍是经典强化学习(RL)。通过分析字节跳动的VeRL框架和相关实践案例,强调构建高质量、高效能的环境对于推进大模型RL训练的重要性。
深度|扣子空间开启内测,字节首个通用AI Agent平台有多强?
字节跳动旗下AI Agent平台‘扣子’开启内测,提供智能任务分解、高效协作等功能。通过60余款插件支持和内置MCP扩展,助力用户完成复杂任务。

字节重磅开源Agent UI-TARS-1.5,全面达到SOTA,超越OpenAI 和Claude!

,我就震撼了
这哥们不仅
能操作GUI界面
还能
玩游戏
?
还能
挖矿
?
上来就给咱展示了一手
视觉模型落地:AI打工,干活全自动

AI 在字节发布的豆包1.5深度思考模型中应用了一项视觉理解模型,能支持对单目标、多目标等进行边界框或点提示定位,并支持3D定位。该模型已广泛应用于各类巡检商业化场景中。通过此技术,用户可以将图交给它识别所有寿司盘的位置,并输出坐标信息。
字节推豆包1.5深度思考模型,PK阿里QWQ-32、Deepseek R1结果如何?

近日,字节跳动发布豆包1.5深度思考模型,该模型在推理能力、速度和多模态方面实现了突破性升级。其参数量为200B,激活参数仅为20B,具有低延迟(<20ms)的优势。通过多项权威基准测试,该模型在数学推理和编程竞赛方面表现出色,并展示了其对图片的视觉推理能力。