
大模型靠强化学习就能无限变强?清华泼了一盆冷水
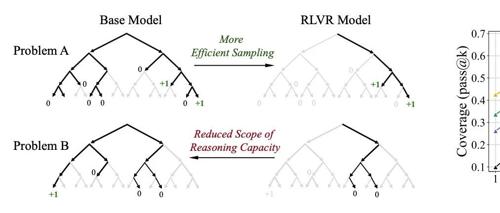
清华大学研究指出,强化学习虽能提升大模型在特定任务上的表现,但可能并未拓展其整体推理能力边界。研究通过pass@k评估发现基础模型在高尝试机会下也能追上甚至超越经过强化学习训练的模型。这表明当前RL技术主要提升的是采样效率而非新解法生成。
清华大学研究指出,强化学习虽能提升大模型在特定任务上的表现,但可能并未拓展其整体推理能力边界。研究通过pass@k评估发现基础模型在高尝试机会下也能追上甚至超越经过强化学习训练的模型。这表明当前RL技术主要提升的是采样效率而非新解法生成。