
极客说|Unsloth 的全微调之路:从 Adapter 到 Full Fine-tuning

Unsloth 框架从支持 LoRA 和 QLoRA 适配器微调到引入全参数微调,解决了大规模模型训练内存占用的问题。通过梯度检查点、激活值卸载和优化器状态分页等技术实现了高效的内存管理和加速训练过程。
Unsloth 框架从支持 LoRA 和 QLoRA 适配器微调到引入全参数微调,解决了大规模模型训练内存占用的问题。通过梯度检查点、激活值卸载和优化器状态分页等技术实现了高效的内存管理和加速训练过程。
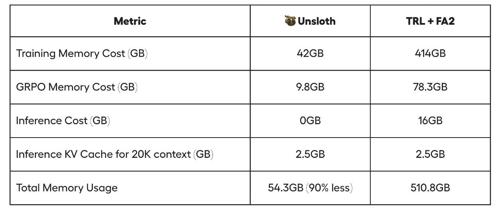
近日,Unsloth 团队升级了微调框架,使得使用其Qwen2.5-1.5B模型仅需5GB显存,相比之前减少了约29%。新的Efficient GRPO算法通过优化内存使用效率,使VRAM需求降至原本的54.3GB。