
近日,Unsloth 团队宣布对其微调框架进行了升级,优化了内存使用效率。现在,使用 Unsloth 微调 Qwen2.5-1.5B 模型仅需 5GB 显存,相比之前所需的 7GB 显存,内存占用减少了约 29%。延伸阅读:DeepSeek GRPO 技术揭秘:Unsloth 助力 7GB 显存体验“顿悟时刻”
此次升级主要得益于 Unsloth Efficient GRPO 算法的推出,该算法在保持 10 倍更长上下文长度的同时,将 VRAM 使用量降低了 90%。例如,在 TRL + FA2 的GRPO 设置中,使用 Llama 3.1(8B)进行 20K 上下文长度的训练,原本需要 510.8GB 的VRAM,而 Unsloth 的90% VRAM 减少使得需求降至仅 54.3GB 。
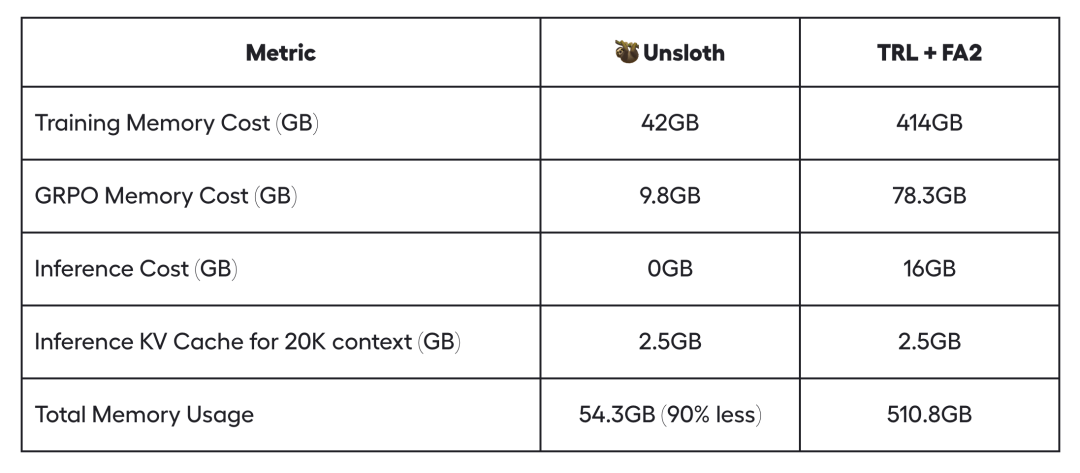
Unsloth 团队通过以下方式实现了 90%的 VRAM 减少:
-
新的内存高效线性算法,将内存使用量削减了 8倍以上; -
智能的 Unsloth 梯度检查点(Unsloth gradient checkpointing[1])算法,将中间激活异步地卸载到系统 RAM,仅慢 1%; -
使用与底层推理引擎(vLLM)相同的 GPU / CUDA 内存空间。
感兴趣的朋友可直接在colab体验:https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Llama3.1_(8B)-GRPO.ipynb
项目地址:https://github.com/unslothai/unsloth
参考资料
Unsloth gradient checkpointing: https://unsloth.ai/blog/long-context
(文:AI工程化)