
阿里开源QwenLong-L1:首个以强化学习训练的长上下文推理大模型
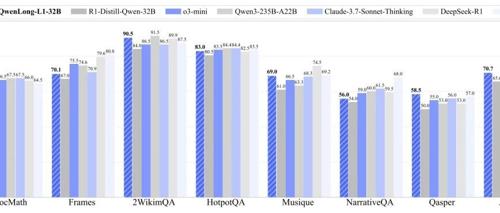
阿里开源的QwenLong-L1框架通过强化学习训练提升了长文本情境推理能力,优于OpenAI-o3-mini等旗舰LRMs,在七个长上下文DocQA基准上表现优异。
阿里开源的QwenLong-L1框架通过强化学习训练提升了长文本情境推理能力,优于OpenAI-o3-mini等旗舰LRMs,在七个长上下文DocQA基准上表现优异。
阿里开源的QwenLong-L1模型在HuggingFace今日热门论文第二,其32B参数版本性能优秀。对比基础模型,QwenLong-L1通过回溯和验证机制成功处理了长文本推理中的干扰信息问题,准确计算了金融文档中涉及优先票据发行成本与第一年利息支出合并的总资本成本。