
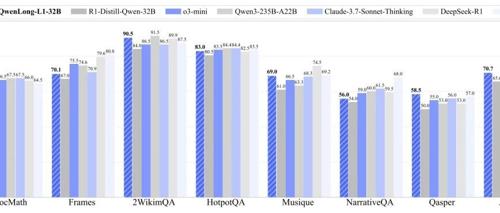

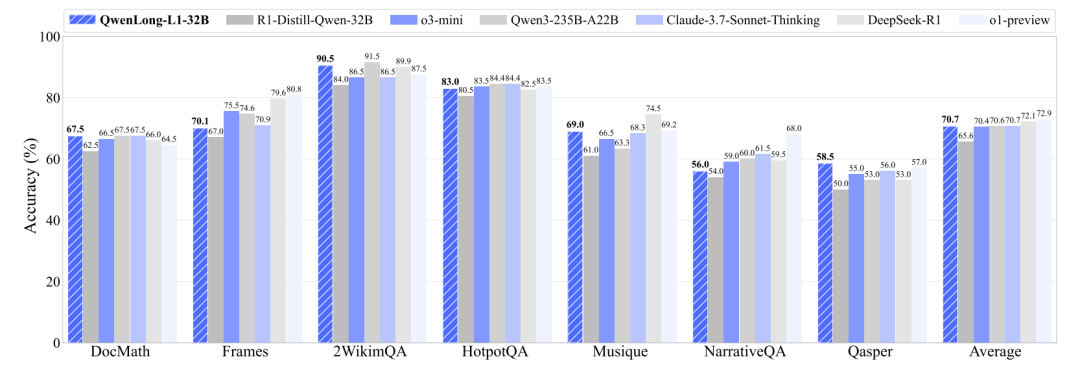
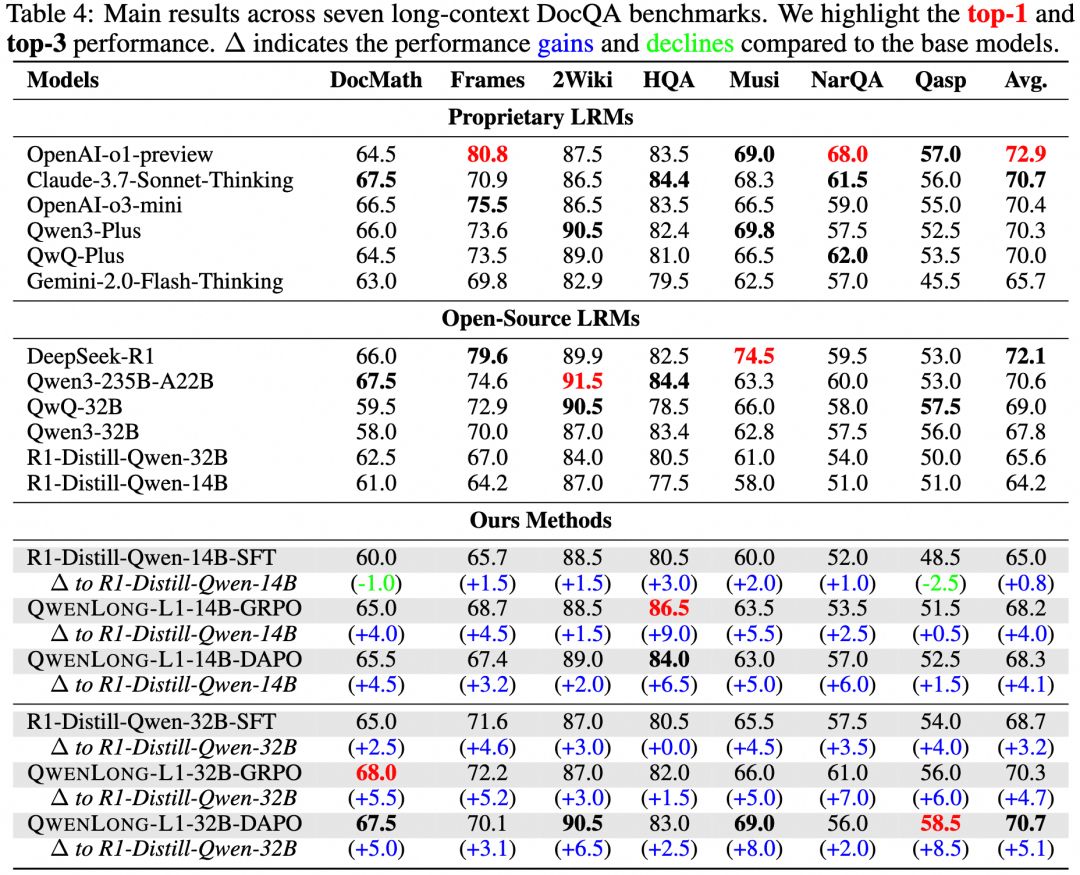
QwenLong-L1是一个新颖的强化学习 (RL) 框架,旨在促进 LRM 从短上下文熟练度向稳健的长上下文泛化能力的转变。在初步实验中,展示了短上下文和长上下文推理 RL 训练动态之间的差异。

-
QWENLONG-L1 框架:该框架通过逐步扩展上下文(progressive context scaling)的方式,将短文本情境的 LRMs 适应到长文本情境。它包含三个核心组件:
-
预热阶段的有监督微调(Supervised Fine-Tuning, SFT):通过高质量的标注数据对模型进行初始化,以建立稳健的初始策略。
-
基于课程的分阶段强化学习(Curriculum-Guided Phased RL):通过逐步增加输入长度的方式,稳定地从短文本到长文本进行适应。
-
基于难度感知的回顾性采样策略(Difficulty-Aware Retrospective Sampling):通过优先采样复杂实例来激励策略探索。
-
RL 算法:文章采用了 GRPO(Group Relative Policy Optimization) 和 DAPO(Decoupled Clip and Dynamic Sampling Policy Optimization) 两种算法,以提高训练的稳定性和效率。
-
混合奖励机制(Hybrid Reward Mechanisms):结合基于规则的验证(rule-based verification)和基于 LLM 的判断(LLM-as-a-judge),平衡了精确性和召回率。





https://www.arxiv.org/pdf/2505.17667QWENLONG-L1: Towards Long-Context Large Reasoning Models with Reinforcement Learninghttps://huggingface.co/Tongyi-Zhiwen/QwenLong-L1-32B
(文:PaperAgent)