
DeepSeek-R1的风吹到了多模态,Visual-RFT发布,视觉任务性能飙升20%
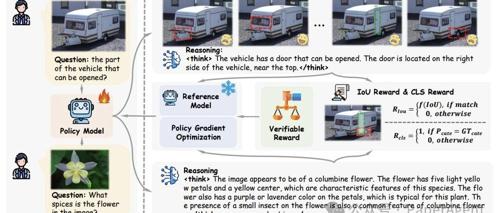
视觉强化微调(Visual-RFT)通过设计特定的可验证奖励函数提升了语言-视觉双向模型在多模态任务中的性能,并展示了其在细粒度图像分类和少样本目标检测等基准测试中的竞争力。
视觉强化微调(Visual-RFT)通过设计特定的可验证奖励函数提升了语言-视觉双向模型在多模态任务中的性能,并展示了其在细粒度图像分类和少样本目标检测等基准测试中的竞争力。

视觉强化微调项目 Visual-RFT 通过规则奖励和强化学习方法,实现了视觉语言模型在目标检测、分类等任务中的高效提升。项目已开源,欢迎加入。