


受人类记忆中“违反预期的事件更难忘”这一观点的启发,定义了一个模型的惊讶度为其对输入的梯度。梯度越大,输入数据与过去数据的差异越大。提出了一个改进的惊讶度量,将过去惊讶度和瞬间惊讶度结合起来,以更好地处理有限记忆。
基于惊讶度量,提出了一个记忆更新规则,结合了过去惊讶度和瞬间惊讶度,通过这种方式,模型可以更好地管理有限的记忆资源。
遗忘机制
-
适应性遗忘:为了管理大量序列数据中的过去信息,提出了一种适应性遗忘机制,允许模型在需要时忘记不再需要的信息。
-
遗忘门控:遗忘机制通过一个门控机制实现,该机制可以灵活地控制记忆的更新,决定多少信息应该被遗忘。这种遗忘机制与现代循环模型中的遗忘门控机制有关。
记忆架构
-
简单MLP:选择了简单的多层感知器(MLP)作为长期记忆的架构,希望专注于长期记忆的设计以及如何将其整合到架构中。这种选择也为未来设计更有效的记忆架构提供了新的研究方向。
如何整合记忆
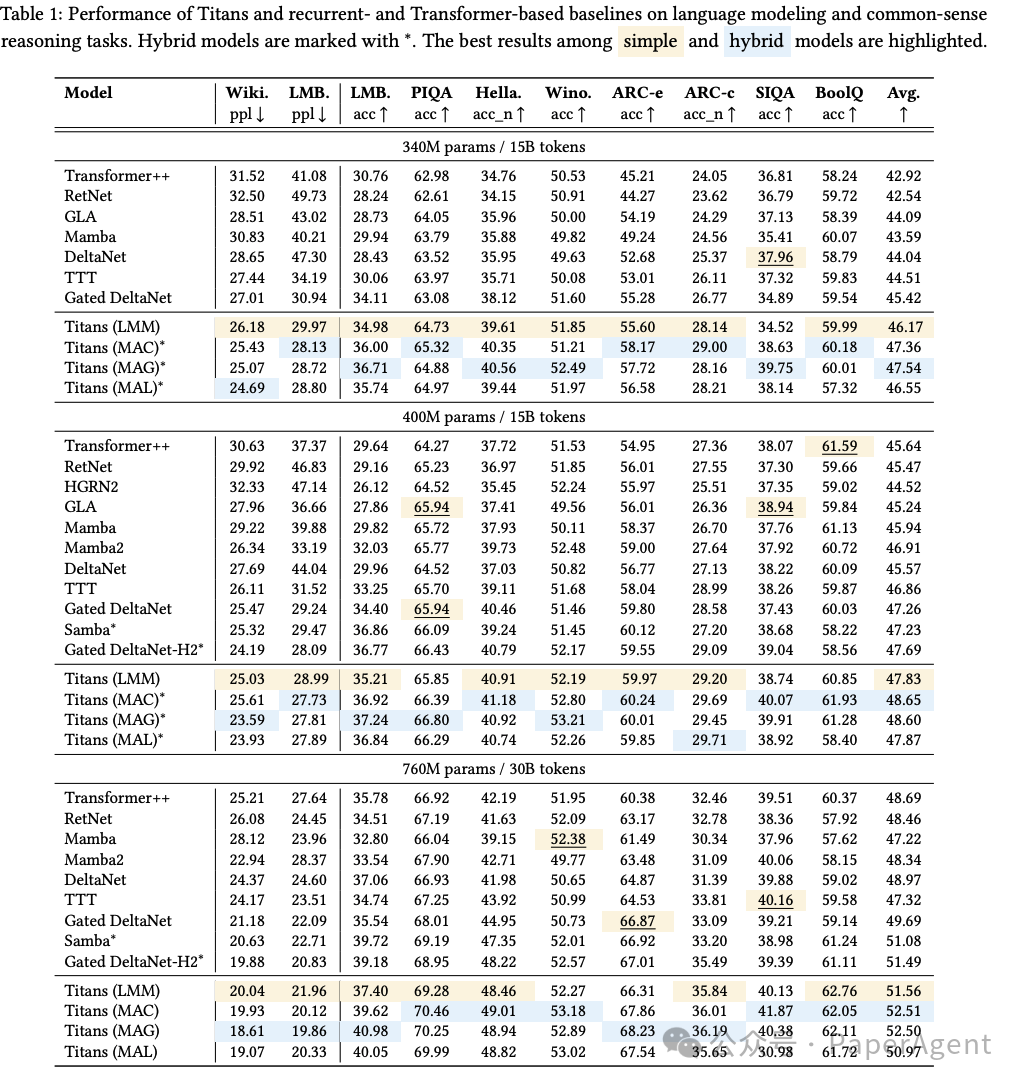
提出了Titans架构,包括三种变体:Memory as a Context (MAC)、Memory as a Gate (MAG) 和 Memory as a Layer (MAL)。这些变体展示了如何将长期记忆模块有效地整合到深度学习架构中。
-
MAC架构:将记忆作为当前信息的上下文,通过注意力机制决定是否需要长期记忆信息,并帮助记忆存储有用的信息。

-
MAG架构:使用滑动窗口注意力作为短期记忆,长期记忆模块作为模型的渐忘记忆,通过门控机制结合两者。
-
MAL架构:将神经记忆模块作为深度神经网络的一层,负责压缩过去和当前上下文,然后通过注意力模块进行处理。



https://arxiv.org/pdf/2501.00663Titans: Learning to Memorize at Test Time
(文:PaperAgent)
Wow, Titans definitely got the memory upgrade! 🐦GitHub/https://github.com/huggingface/petrinet-labs/titans