

大家好我是歸藏(guizang),今天教大家制作现在最火的 AI 视频品类。
无论你是否关注 AI 最近肯定在不同的社交媒体上刷到了这类视频。
一个大猩猩或者其他动物对着镜头絮叨,要不就是各种虚构的历史事件的采访。
每一个点赞和播放都很高不管是在国内还是海外。
虽然很无聊但是刷到就看的停不下来,即使是我这种经常接触 AI 内容的人都是如此。
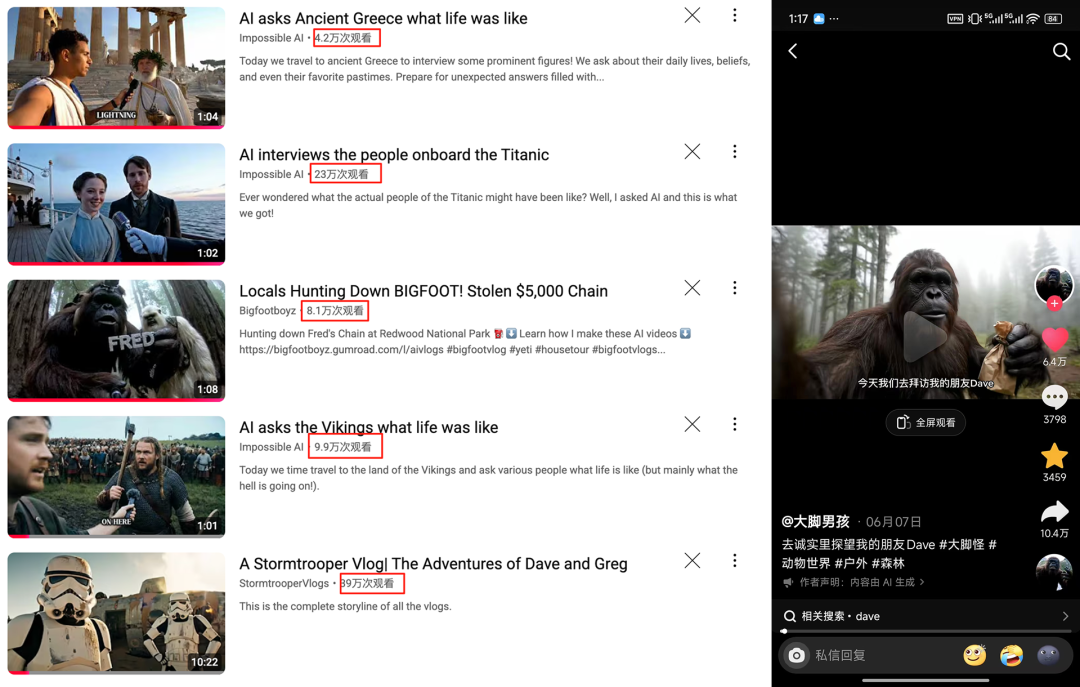
这种品类甚至都渗透到了广告和营销的领域。
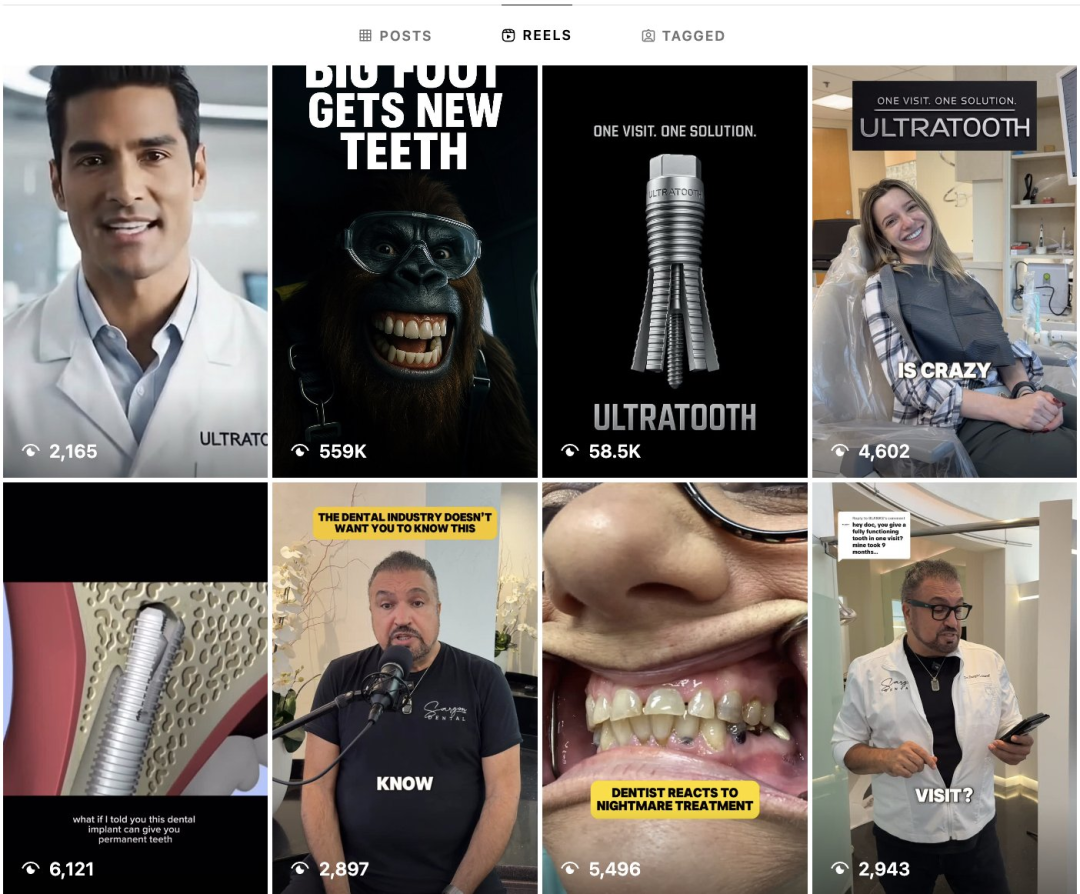
ins 上有个牙医诊所每天都发广告,每个播放都只有几千,但是换成“大脚男孩”之后他的广告播放高达 56 万次!
有了 Veo3 之后 AI 视频的制作成本下降了非常多。
现在可能是你入门 AI 视频制作非常好的机会,只需要两次生成简单的合并两段视频,你的作品就已经完成了。
你可能以为上面这些视频的点子都是创作者自己想的,但我要告诉你,其实不是。
上面大部分爆火的 AI 视频几乎从构思到提示词到生成全是 AI 为主,人类需要做的事情只有挑选点子,生成和复制提示词而已。
所以这篇内容我不只会教你如何用视频模型,我还会教你用各种工具分析视频从而生成新的创意,给你提示词模板,让你从创意到生成全部自动化。
我这个流程其实接近工程化了,你甚至可以用来做视频 Agent 产品,先要个赞🩷不过分吧。
先来看两个我用这流程做的这类 AI 视频,首先是荒诞采访形式的海盗财报会议。
之后是一个给巨龙看守地牢的倒霉哥布林牛马的一天。
是不是很牛批!好了,从现在开始扔掉你的脑子,开搞!!!
如何分析爆款视频
首先我们要教的是如何分析视频和拓展创意,这里我用的 NotebookLM。
你是不是只用 NotebookLM 来分析有口播的 youtube 视频,但我要告诉你,Gemini 其实是能分析视频画面的,所以你可以让 Noteboolm 帮你分析任何 Youtube 爆款视频的创作形式。
你甚至可以往里面加入多个爆款视频一起交叉分析。
你需要做的第一步是打开页面,新建一个 NotebookLM 笔记本,在添加来源这里输入你找到的 youtube 爆款视频地址。
你可以在来源这里继续添加,我最后一次性添加了找到的四个 Veo3 做的爆款 AI 视频,两个是第一人称Vlog 形式的,两个是采访形式的。
然后就可以写提示词让 NotebookLM 开始分析了,这里我放上我的提示词改一下前面的部分可以套用到任何创意视频上。
这四个视频都是用谷歌新发布的 Veo 3 视频模型生成编排的,在 Youtube 非常火爆,详细分析每个视频的每一个分镜的台词和画面内容,然后总结爆火的原因。
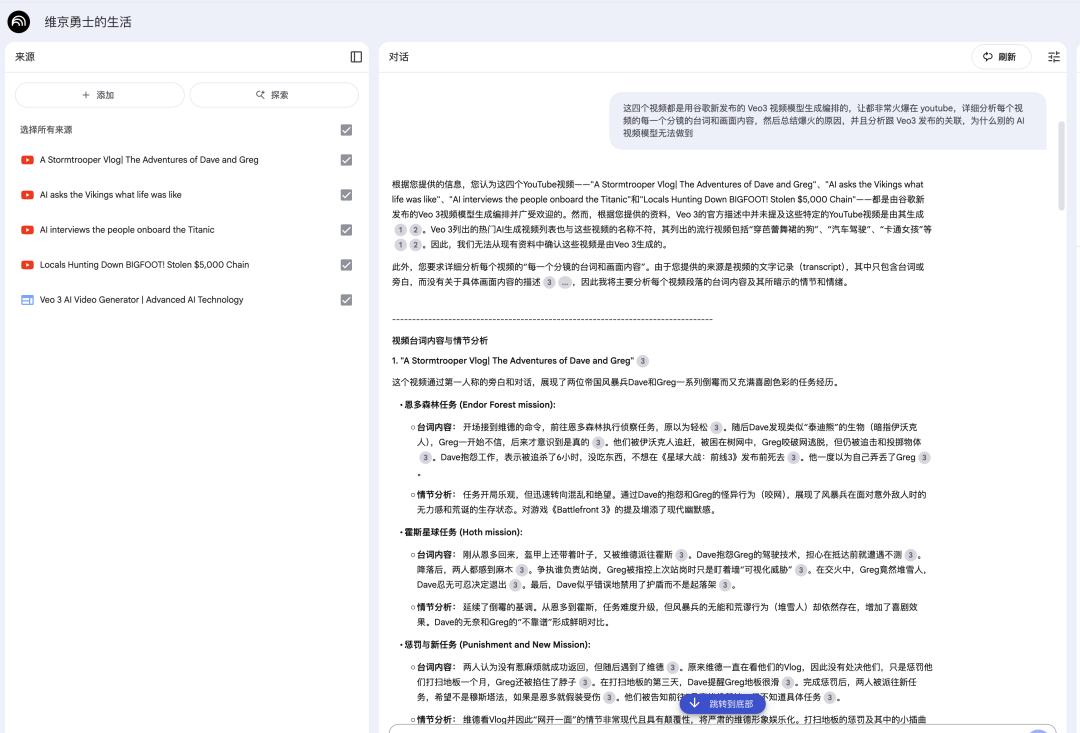
可以看到 NotebookLM 分析的非常详细。
每个视频的分镜画面以及台词内容都输出了,同时对于这类视频爆火的原因分析的也非常好。
我看完对这些视频爆火的原因是有些感觉到,但是完全做不到 NotebookLM 分析的这么细致和完整。
Veo3 伪纪实爆款视频的万能公式:四大核心要素
核心引擎:巨大的“反差感” (Contrast Engine)
这是所有笑点的根本来源。视频的成功在于将两个完全不搭界的元素进行强行碰撞,从而产生荒诞的喜剧效果。
- 时代反差: 用最现代的形式(Vlog、街头采访)去呈现古老或虚构的内容(泰坦尼克号、维京人、大脚怪、暴风兵)。
- 身份反差: 让本应神秘、严肃或邪恶的角色(大脚怪、维京人、暴风兵)表现出普通人(甚至“屌丝”)的一面,充满生活气息和人性弱点。
- 情境反差: 在极度危险或宏大的背景下,角色们关心的却是微不足道的日常琐事。例如,在即将撞上冰山时,乘客关心的是明早的吐司;在炮火连天的战场上,暴风兵在堆雪人。
表现形式:“伪纪实”的沉浸感 (Authentic Format)
视频都采用了模拟真实记录的拍摄手法,让观众产生“这好像是真的”的错觉,从而使反差感更加强烈。
- 伪采访 (Pseudo-Interview): 如《泰坦尼克号》和《维京人》,采用一本正经的新闻采访形式,让荒谬的回答显得更加滑稽。
- 第一人称Vlog (First-Person Vlog): 如《大脚男孩》和《暴风兵》,使用自拍杆和主观镜头,极大地增强了代入感,仿佛在看这些角色的“朋友圈”视频。
内容基石:利用“共同认知” (Shared Knowledge)
这些视频从不凭空创造世界观,而是巧妙地站在“巨人”的肩膀上,利用了观众已有的知识储备和刻板印象。
- 历史事件: 观众都知道泰坦尼克号会沉、维京人好战。
- 流行文化/IP: 观众都认识《星球大战》的暴风兵和维达。
- 文化迷因: 观众都了解“大脚怪”的传说或特定人群的刻板印象(如开斯巴鲁的户外爱好者)。 这极大地降低了观众的理解成本,笑点无需铺垫,一点就通。
传播关键:极强的“职场/生活共鸣” (Relatable Complaints)
视频最“扎心”也最搞笑的部分,是把所有宏大的叙事都拉回到普通人的抱怨和吐槽上。
- “打工人”的嘴替: 暴风兵把维达叫做“混蛋老板”,抱怨工作环境差、任务危险、同事不靠谱。这让所有上班族都感同身受。
- 日常的烦恼: 泰坦尼克号的电梯工抱怨工作繁琐,维京女人抱怨总在洗血衣服。这些充满生活气息的细节让角色瞬间变得鲜活,也让观众产生了强烈的共鸣。
如何拓展视频创意
我们上面已经有了这类爆款视频的创作逻辑和分镜描述了,接下来我们需要让 AI 根据这些上下文帮我们拓展创意。
你可以打开任何一个你用的惯的 AI 模型,我这里用的还是 Gemini。
将刚才 Notebooklm 分析的结果发给他,然后跟他说:
我会发给你几个最近非常火爆的用 AI 视频模型生成的视频内容和爆火的原因,你需要结合这些内容给我一些类似第一人称 Vlog 形式的点子,详细描写每个分镜(8 秒)对应的环境和角色以及说话内容和语气,适当插入打破第四面墙的说话方式,比如要赞。

这里我们首先做的是第一人称 Vlog 形式的视频。
这里的文案可能和内容可能我们生成提示词到时候并不会用,但是依然要让他输出是因为需要用详细的分镜内容和口播文案来判断创意的质量,不能只依赖标题和简单的描述。
之后你就可以根据他输出的点子内容进行挑选,首选比较好实现和偏现实题材的,这样生成的效果比较好。
这里我选了哥布林牛马这个,感觉反差感很强,在《龙与地下城》这种宏大视觉观的小角色视角。

在虚构采访这里我选用了海盗年会和金融行业黑话这个点子,反差感也很足,也会让打工人很有共鸣。

提示词生成
如果你对某个分镜感觉有需要修改的部分可以让他重新修改,直到内容你就的没问题。
这里我偷懒了,没有改直接进入了下一步,开始生成提示词。
这部分就比较简单了,我会给你第一人称 Vlog 和采访两个方案的提示词模板。
让 AI 基于刚才讨论的结果和提示词模板输出每个分镜的提示词就行。
第一人称 Vlog 风格视频提示词生成:
【地老哥布林清洁工】,这个点子很好,将每个分镜的所有提示描述内容都放在一段话中,包括音频相关内容,每个分镜 8 秒,注意台词长度,不要超时。
参考这个模板生成提示词:A cinematic, handheld selfie-style shot of [a detailed character description, e.g., a sci-fi explorer in a sleek silver spacesuit]. They hold the camera at arm’s length, and their [specific arm/hand description, e.g., armored silver gauntlet] is clearly visible in the frame as they show a [specific emotional expression, e.g., look of pure awe]. The scene is a [detailed location and time of day, e.g., bioluminescent alien jungle at twilight], and behind them, [describe the key background element, e.g., massive, pulsating mushroom-like trees] cast a [specific lighting quality, e.g., vibrant purple and blue light] across the landscape. The character looks directly into the camera and speaks in a [specific tone of voice, e.g., breathless, excited whisper]: “[Your Dialogue Here]”. (Optional: For extra control, add specs like Lens: wide-angle with shallow focus or describe a camera pan).

虚构采访类型提示词生成
【海盗会议】,这个点子很好,将每个分镜的所有提示描述内容都放在一段话中,包括音频相关内容,每个分镜 8 秒,注意台词长度,不要超时。
参考这个模板生成提示词:A cinematic, medium handheld interview shot featuring [a detailed character description, e.g., a fearsome pirate captain in a captain’s coat with a Bluetooth earpiece]. They display a [specific emotional expression, e.g., look of confident authority] as they speak. The scene is set in [detailed location, e.g., a secluded alcove of a massive, torch-lit sea cave], with [key background elements, e.g., other pirates mingling near a makeshift bar] visible in the slightly out-of-focus background. The atmosphere is thick with [describe environmental sounds, e.g., the murmur of distant conversations and the clinking of tankards]. Flickering [specific lighting quality, e.g., torchlight] illuminates the character, casting dynamic shadows. Crucially, the character looks slightly off-camera, addressing an unseen interviewer. They speak in a [specific tone of voice, e.g., a fast-talking, confident finance-bro voice]: “[Your Dialogue Here]”. (Optional: For extra control, specify lens details like ‘shot on a 50mm lens with a shallow depth of field’ or describe camera movement like ‘a slow push-in during the dialogue’).
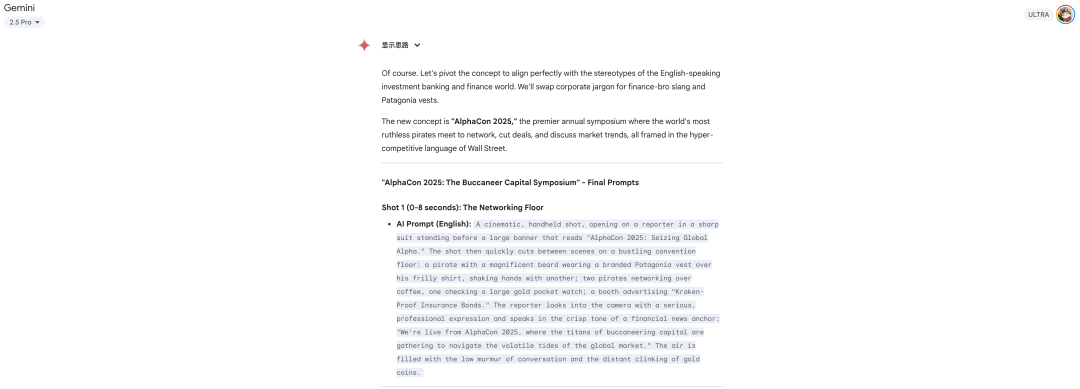
到这一步,基本上我们的前期准备工作就结束了。
因为 Veo3 强大的提示词遵循和稳定性以及音频生成能力,我们可以直接跳过图生视频的图片生成、语音生成、唇形同步、音效匹配这几步。
如果以前要做类似的视频你可以想象要多麻烦,上面跳过的每一步都有可能出问题导致增加好几倍的工作量。
生成视频
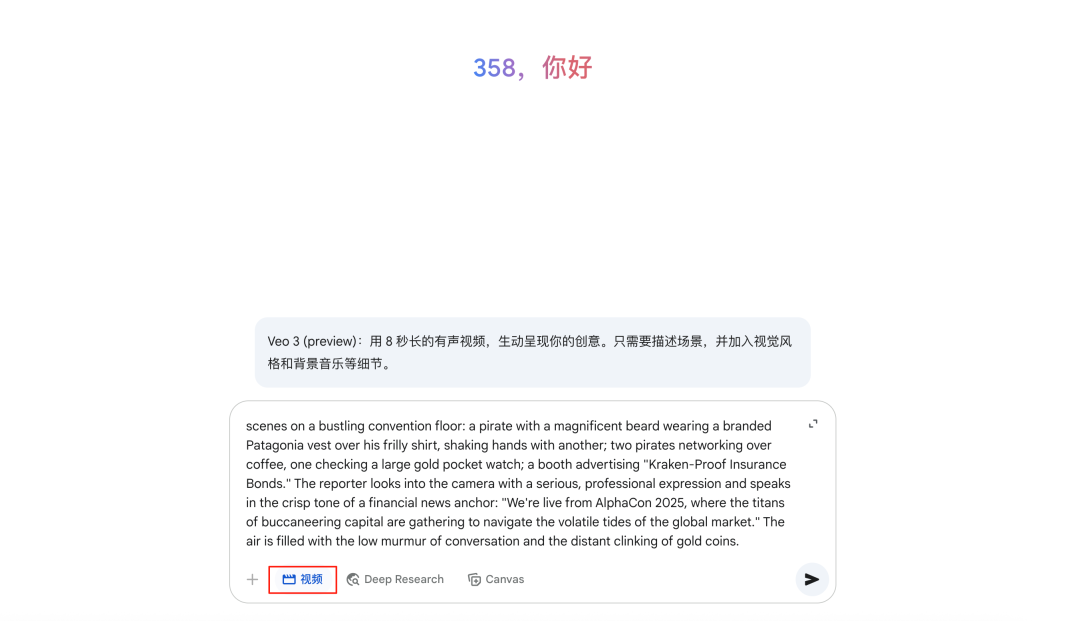
接下来我们就可以生成视频了,如果你想简单点搞定,我推荐你开个 Gemini Pro 会员,在 Gemini 里面生成。
直接进入到 Gemini APP 里面,选中输入框下面的视频按钮,输入提示词然后回车就行。
如果你不怕麻烦的话可以用 FLOW (labs.google/fx/zh/tools/flow/)这个谷歌专门用来视频生成的产品。
详细的教程我之前写过《Veo3和FLOW一手实测:谷歌这次成了,这次视频创作可能彻底变天》,这里就写一下简单的。
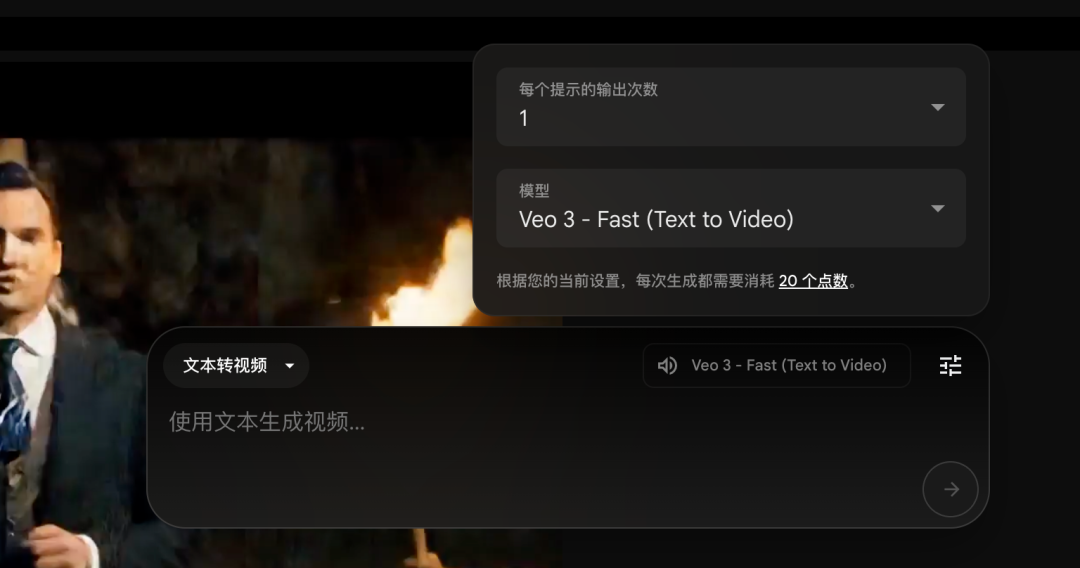
进来以后先创建项目,然后在输入框设置这里把模型调整到 Veo3 Fast 模型,这个很便宜。
不要再因为没切换模型,跑来问我为啥视频没声音了!
如果你追求质量可以用Quality 模型,但很贵。然后输入提示词等待生成就行。
如果这里下载的时候可以选择将生成的结果超分成 1080P,视频会清晰一些。
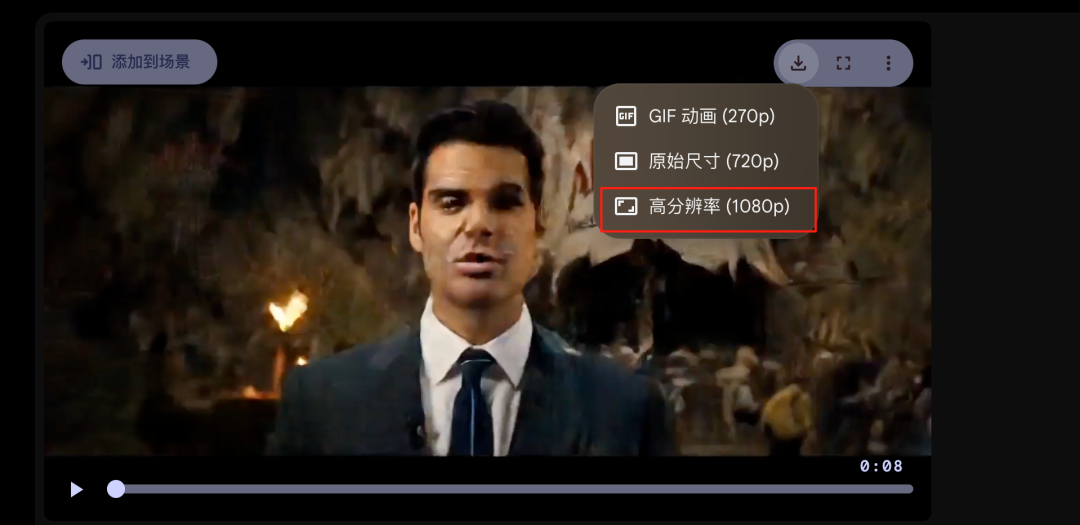
到这里我们基本上全部都 OK 了。
视频合并及后处理
最后就是把视频合起来了,由于 Veo3 生成的视频基本就是完整的,你只需要用剪映或者其他工具把多端视频拼接然后导出就行,这应该都会做吧。
如果是英文的话可以点上面的字幕让剪映帮你自动生成一个字幕。
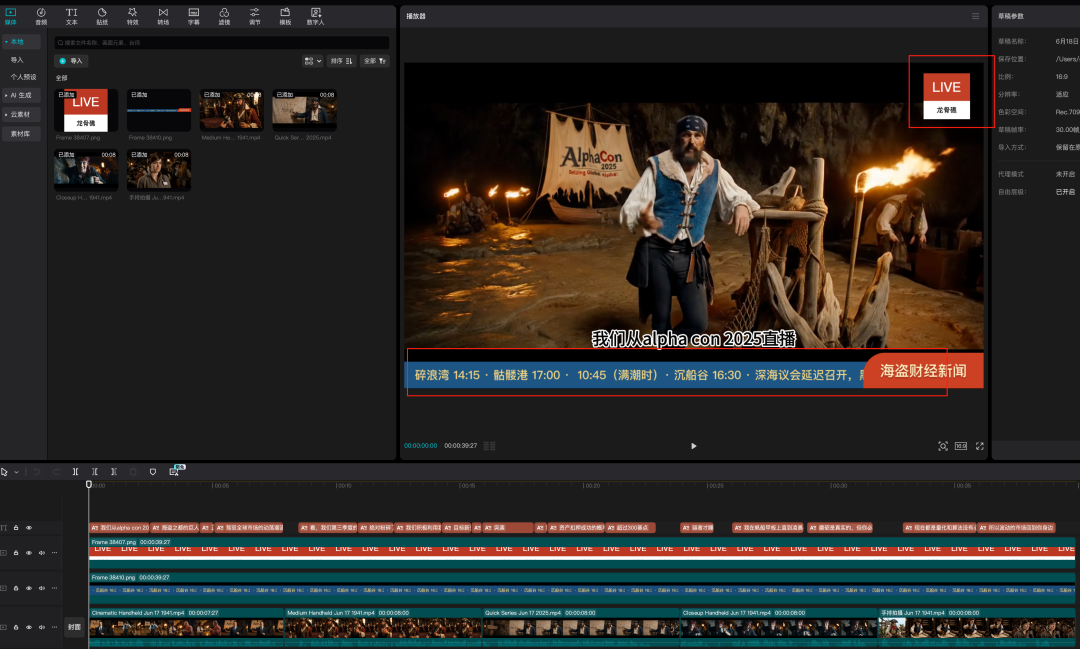
如果你还需要增加一些沉浸感的话可以加一些装饰,比如像我这个海盗年会一样加了一些类似电视台新闻直播都有的台标和文字滚动新闻。
在一个月前我 Veo 3 的测评文章里面就说过,“每一次Agent的模型化即使每个部分的模型本身质量没有升级也会带来非常多的应用场景和新的产品机会”。
现在回看我这个预言是不是算成真了,最近几乎每天都有基于 Veo3 制作的视频爆款产生,而且不断向不同的视频品类扩散。
AI 视频制作过程每少一步对于创作者基本盘的拓展就不止 10 倍这么简单,很多人有很好的点子和流量嗅觉只是因为技术和对 AI 的了解不够,所以没办法生产内容。
Veo3 生产成本已经很低了,如果出现视频类 Agent 把视频字幕之类的包装工作搞定,AI 视频生产者又何止百倍。
我们今年或许就能看到这一天的到来。
好了,到这里教程基本就结束了,谢谢各位的双击🩷和大大的赞👍,孩子饿坏了,给点吧。
(文:归藏的AI工具箱)